
تصور کنید وبسایتی طراحی کردهاید که برای چشم انسان خیرهکننده است، اما برای هوش مصنوعی شبیه به یک هزارتوی بیراهه است. اگر امروز روی بهینهسازی بصری سایت خود سرمایهگذاری میکنید، احتمالاً برای «مخاطب دوم» وب — یعنی عاملهای هوش مصنوعی — نامرئی هستید. این واقعیت پس از اظهارنظر یکی از کارکنان you.com در یک هکاتون آشکار شد: وب اکنون یک مخاطب دوم دارد.
بر اساس گزارشهای منتشر شده از ابزار Agentis Lux، پورتفولیوهای سادهی توسعهدهندگان مستقل در حال حاضر عملکرد بهتری نسبت به غولهای تجارت الکترونیک و سایتهای دولتی در زمینه خوانایی برای هوش مصنوعی دارند. در این بنچمارک، یک سایت شخصی با امتیاز ۹۱ از ۱۰۰، صدرنشین شد. این ابزار توسط توسعهدهندهای به نام earlgreyhot1701D برای هکاتون H0 (با همکاری Vercel و AWS Databases) ساخته شده تا تفاوت بین آنچه ما روی صفحه میبینیم و آنچه عاملهای بازیابی (Retrieval Agents) در قالب HTML خام پردازش میکنند را آشکار کند.
وقتی از یک عامل (Agent) — مثل کتابخانهداری که میلیاردها صفحه را خوانده و حالا با همان لحن جواب میدهد — سؤالی میپرسید، او تصاویر یا دکمههای استایلدار شما (Hero Images یا Styled Buttons) را نمیبیند. طبق اعلام سازندگان ابزار، این عاملها فقط کدهای مارکآپ زیرین را میخوانند و اغلب اجرای جاوااسکریپت را کاملاً نادیده میگیرند. بنابراین، مدلهایی مثل ChatGPT یا Perplexity نسخهای تکهتکهشده و عاری از ظاهر سایت شما را تجربه میکنند.
همانطور که در تحلیلهای قبلی ما دربارهی امنیت مدلهای بازمتن اشاره کردیم، درک لایههای زیرین سیستم برای بهینهسازی حیاتی است. Agentis Lux نیز با همین فلسفه ساخته شده؛ شبیه به وقتی که یک برنامهنویس مدل GPT-2 را از صفر با زبان C/CUDA میسازد تا ریاضیات زیربنایی آن را بفهمد. این پروژه تکاملیافتهی ابزار Hermes Clew است که پیشتر برای چالش پلتفرم Agent در GitLab Duo طراحی شده بود. در حالی که Hermes به عنوان یک موتور پایتونی در داخل چت GitLab Duo قرار داشت و فایلهای ریپازیتوری (مثل HTML, JSX, TSX) را اسکن میکرد، Agentis Lux این منطق را به وب آزاد منتقل کرده است. در واقع، این ابزار فایلهای خاص ریپازیتوری را با هر URL زندهی وب جایگزین کرده و یک ابزار پنجره-چت را به یک محصول مستقل روی معماری ابری تبدیل کرده است.
زمینه: آگاهی بهجای قضاوت
Agentis Lux بر پایه یک فلسفه دقیق بنا شده: نمایش وضعیت (Visibility)، نه ارائه حکم (Judgment). برخلاف ابزارهای ممیزی دیگر، این سامانه هیچ راهکاری برای اصلاح کد پیشنهاد نمیدهد. این یک انتخاب آگاهانه بود تا این ابزار از Hermes Clew متمایز شود. هدف این است که توسعهدهنده دقیقاً ببیند یک عامل چه چیزی را تجربه میکند، بدون اینکه به او گفته شود کدش را چگونه تغییر دهد.
به عنوان مثال، گزارش ابزار به سادگی نمیگوید «این بخش خراب است». در عوض، دیدگاه یک عامل را ارائه میدهد: «یک عامل که وارد این صفحه میشود نمیتواند تشخیص دهد کدام المان شروع فرآیند پرداخت (Checkout) است، چون این بخش یک div استایلدار است و نه یک دکمه (button)». ارزش این ابزار در ایجاد آگاهی است و تصمیمگیری درباره نحوه تکرار و بهبود کد را بر عهده توسعهدهنده میگذارد.
سازوکار موتور Perseus Clew
این ابزار از معماری دو لایهای به نام موتور Perseus Clew استفاده میکند. هسته اصلی آن «deterministic» یا معین است؛ به این معنا که امتیازدهی بر اساس تطبیق الگوها (Pattern Matching) انجام میشود، نه بر اساس احتمالات هوش مصنوعی. این امر تضمین میکند که یک ورودی ثابت، همیشه یک امتیاز ثابت دریافت کند. اصل راهنمای اینجا این است: «ساختار معین است؛ اما لحن و flavor متعلق به هوش مصنوعی است».
Agentis Lux برای امتیازدهی به فرانت-اند از ۶ بررسی قطعی استفاده میکند تا نمرهای از ۱۰۰ را محاسبه کند:
- HTML معنایی: استفاده درست از المانهای ساختاری.
- دسترسی به فرمها: اینکه یک عامل چقدر راحت میتواند ورودیها را تجزیه کند.
- ARIA: برچسبهای دسترسی برای عاملها.
- دادههای ساختارمند: متادیتای ماشینخوان و Schema.
- محتوای موجود در HTML: حضور واقعی متن در مارکآپ خام.
- لینکها و ناوبری: شفافیت نقشه سایت (Sitemap).
در کنار اینها، مجموعهای دوم شامل ۶ بررسی API در بکاند اجرا میشود. برای ارائه تحلیل کیفی، ابزار از Amazon Bedrock در دو نقطه خاص که در آنها Regex (عبارات منظم) کمکی نمیکند، استفاده میکند:
- حکم به زبان ساده: یک فراخوانی از Bedrock که یک خلاصه تکخطی از نتیجه را مینویسد.
- شبیهسازی عامل: لایهای دوم که استدلال میکند یک عامل بازیابی چه تجربهای خواهد داشت و چه کارهایی را میتواند یا نمیتواند انجام دهد. تأکید میشود که این یک عامل خودمختار نیست که روی صفحه کلیک کند، بلکه شبیهسازی تجربه است.
برای جلوگیری از «خلاقیت» یا توهم مدل، هوش مصنوعی با دمای (Temperature) پایین، محدودیت تعداد توکن و یک پرامپت سیستمی سختگیرانه محدود شده است. این پرامپت استفاده از کلمات قضاوتی، خط تیره (em dashes) و پیشنهادهای اصلاحی را ممنوع میکند. شبیهسازی یک JSON ساختاریافته را باز میگرداند که در برابر یافتههای قطعی فیلتر میشود. اگر مدل سعی کند یافتهای را ابداع کند که ریاضیاتِ هسته معین آن را پیدا نکرده است، از اعتبارسنجی رد شده و به یک قالب (Template) پیشفرض بازمیگردد.
زیرساخت بکاند
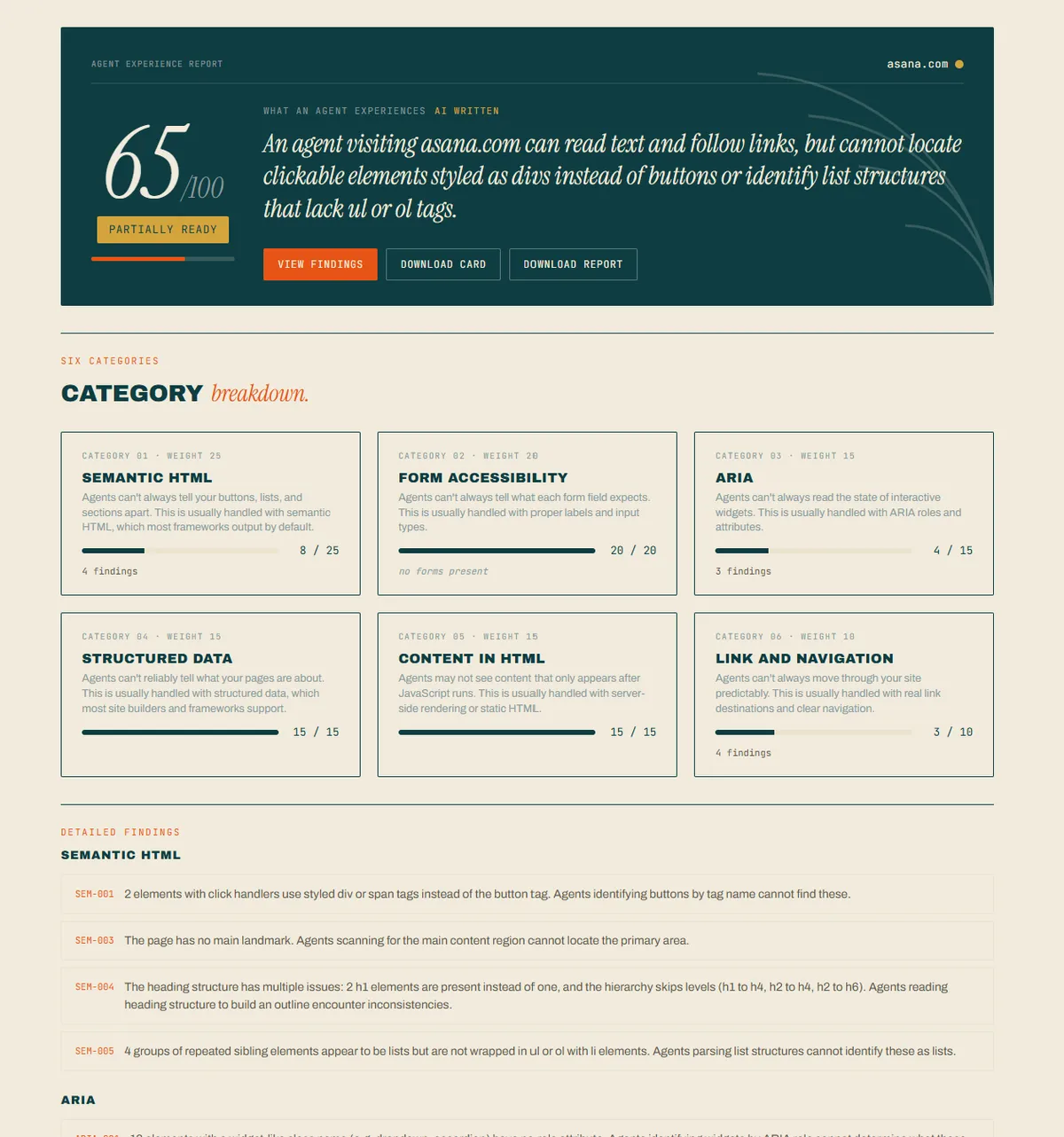
این محصول روی Vercel مستقر شده و از AWS با استفاده از DynamoDB به عنوان لایه دادههای اصلی بهره میبرد. معماری سیستم به گونهای است که DynamoDB را به عنوان یک مدل دادهای تعمدی برای جستوجوهای تک-کلیدی (Single-key lookups) میبیند، نه صرفاً یک ذخیرهساز کلید-مقدار ساده.
سیستم از پنج جدول تخصصی استفاده میکند (که همگی پیشوند PerseusClew دارند):
- ScanCache: با TTL (زمان بقا) ۱۵ دقیقهای؛ کلیدگذاری شده بر اساس هش URL برای حذف درخواستهای تکراری و کاهش هزینههای Bedrock.
- ScanResults: با TTL ۲۴ ساعته؛ کلیدگذاری شده توسط یک ID مبهم برای نتایج ناشناسی که به طور خودکار منقضی میشوند.
- BenchmarkScans: ذخیره دادههای ۵۰ سایت با یک شاخص ثانویه جهانی (GSI) بر اساس دستهبندی (Vertical)؛ این دادهها ماهانه از طریق EventBridge بازنویسی میشوند.
- ScanCounters: شمارشهای سمت سرور بدون اطلاعات شناسایی شخصی (PII)، که برای سطح تیم رزرو شده است.
- Users: یک ساختار ساده برای تاریخچه کاربران وارد شده.
این تفکیک بین «ریاضیات» و «هوش مصنوعی» یک تصمیم اقتصادی است. چون هسته معین هزینه بسیار اندکی دارد، لایهی رایگان ابزار میتواند رایگان بماند. توسعهدهنده فقط برای توکنهای مدل در دو بخشی که انسان واقعاً میخواند (جمله خلاصه و شبیهسازی) هزینه پرداخت میکند.
یافتههای بنچمارک
توسعهدهنده برای جلوگیری از تغییر معیارها (Moving the goalposts)، ابتدا پیشبینیهای خود را برای ۵۰ سایت ثبت کرد و آنها را با مهر زمانی (Timestamp) در ریپازیتوری قرار داد. این رویکرد «ابتدا پیشبینی، سپس داده» باعث شد نتایج عینی باقی بمانند. دادهها از ۱۰ سایت در هر یک از دستههای تجارت الکترونیک، SaaS، رسانه و محتوا، دولت آمریکا و پروژههای توسعهدهندگان مستقل جمعآوری شد.
نتایج تضاد شدیدی را نشان داد:
- توسعهدهندگان مستقل: با میانگین امتیاز ۷۷ از ۱۰۰ برنده بنچمارک شدند.
- بالاترین امتیاز: یک پورتفولیوی شخصی توسعهدهنده به امتیاز ۹۱ رسید.
- دولت/SaaS/تجارت الکترونیک: همگی رتبههای پایینتری نسبت به مستقلها داشتند.
- مسدودکنندهها: چهار سایت، از جمله OpenAI، دسترسی ابزار را در همان ابتدا مسدود کردند.
- دامنه نمرات: امتیازها در بازه ۳۴ تا ۹۱ متغیر بود.
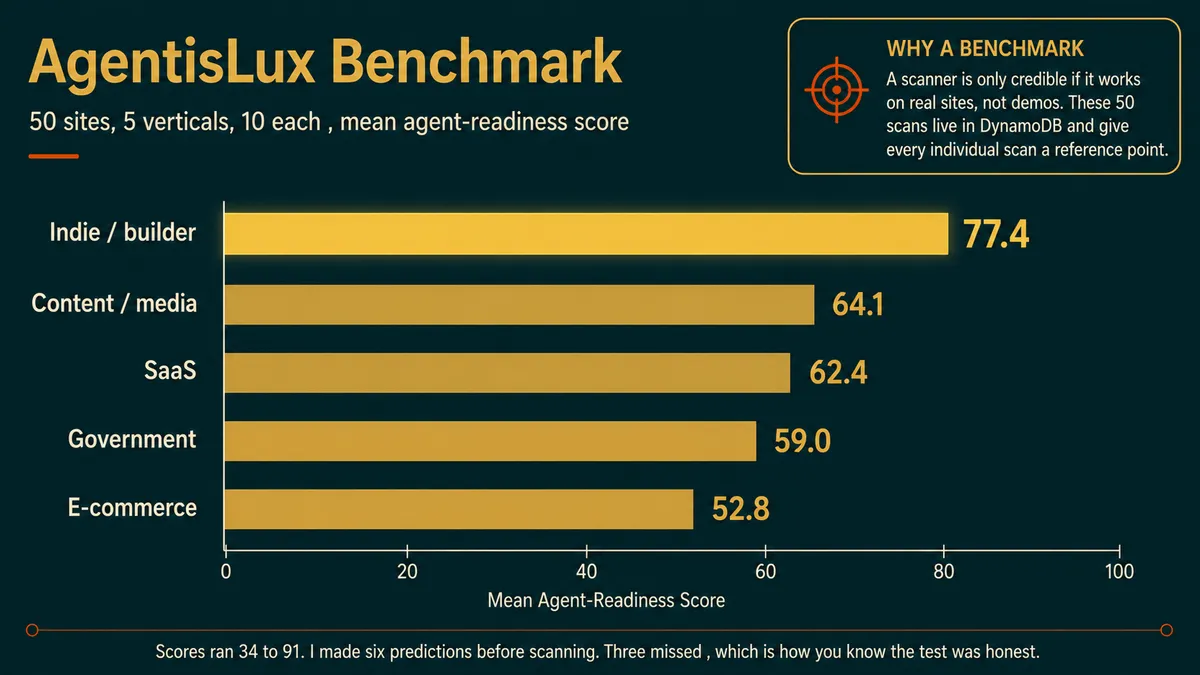
توسعهدهنده سه پیشبینی از شش مورد خود را اشتباه حدس زده بود. این موضوع به عنوان یک موفقیت تلقی شد زیرا ثابت کرد دادهها عینی هستند. نتیجه نهایی این است که «ظرافت ساختاری (Craft) بر رعایت قوانین خشک (Compliance) پیروز میشود»؛ یک سایت دستساز شخصی اغلب برای یک عامل تمیزتر از سایتهای بزرگترین شرکتهای جهان است.
امنیت و محدودیتها
فراخوانی URLهای ارسالی توسط کاربر در یک نقطه انتهایی عمومی ریسکهای امنیتی زیادی دارد. برای سختسازی بکاند، چندین لایه پیادهسازی شد:
- رزولوشن کامل DNS و مسدود کردن IPهای خصوصی یا رزرو شده.
- اعتبارسنجی هر گام تغییر مسیر (Redirect hop) و اجبار به استفاده از HTTPS.
- تعریف سقف برای اندازه پاسخ (Response size) و زمان انتظار.
بهدلیل اینکه این یک پروژه تکنفره با ضربالاجل زمانی بود، برخی محدودیتها باقی مانده است: بکاند به جای TypeScript با JavaScript نوشته شده است. صفحه بنچمارک به جای پرسوجوی زنده از DynamoDB، یک اسنپشات منتشرشده را نمایش میدهد. همچنین، سیستم به گونهای طراحی شده که شکست Bedrock پذیرفته شود؛ اگر مدل خطا دهد، گزارش همچنان نمایش داده میشود زیرا حکم هوش مصنوعی یک قالب قطعی به عنوان کف (floor) دارد.
چشمانداز رقابتی
Agentis Lux جایگاه متفاوتی نسبت به ابزارهای دیگر دارد. در حالی که ابزاری مثل Scrunch (که توسط Sitecore خریداری شد) روی این تمرکز دارد که آیا یک برند در پاسخهای هوش مصنوعی ذکر میشود یا خیر (دیدهشدن/Visibility)، Agentis Lux روی این تمرکز دارد که آیا عامل واقعاً میتواند صفحه را بخواند و از آن استفاده کند (کارپذیری/Operability).
همچنین با ممیزی Agentic Browsing گوگل در Lighthouse (که در می ۲۰۲۶ معرفی شد) متفاوت است. در حالی که گوگل سطح «عامل بهعنوان کنشگر» (Agent-as-actor) از طریق WebMCP و رانندگی در مرورگر را بررسی میکند، Agentis Lux سطح «عامل بهعنوان خواننده» (Agent-as-reader) — یعنی همان برداشت خام HTML که یک عامل بازیابی پیش از هر کنشی تشکیل میدهد — را تحلیل میکند.

اثرات درجه دوم
این تحول نشان میدهد وب در حال تبدیل شدن به دو تجربه کاربری مجزا است: یکی بهینه برای انسانهای بصری و دیگری بهینه برای عاملهای بدون سر (Headless Agents). عاملها طیفی هستند؛ از خزنده (Crawler)های بازیابی که جاوااسکریپت را نادیده میگیرند تا عاملهای راننده مرورگر که آن را اجرا میکنند. شکاف بین این دو، مرز بعدی برای این ابزار است و برنامههایی برای پرسوجوی زنده بنچمارک و یک حالت رندر (Render mode) وجود دارد تا تفاوت بین دیدگاه عاملهای غیر JS و JS-capable را نشان دهد.
برای صاحبان کسبوکار، یک سایت با نرخ تبدیل بصری بالا ممکن است برای عاملهای هوش مصنوعی که کاربران را به سمت محصولات هدایت میکنند، «نامرئی» باشد. اهمیت این بهینهسازی را میتوان در نتایج عملی مشاهده کرد؛ برای مثال، دادههای اخیر نشان میدهد که سازمانهای خدماتی با بهرهگیری از عاملهای بهینه شده توانستهاند در مدت کوتاهی به بازگشت سرمایه دست یابند. Agentis Lux ثابت میکند مدرنترین سایتهای سنگین از نظر جاوااسکریپت، اغلب برای نسل بعدی وب سختترین سایتها برای استفاده هستند. این ابزار حتی برای بهینهسازی خودش به کار رفت و امتیاز سایتش را از ۷۰ به ۹۶ رساند.
شما میتوانید خوانایی سایت خود را در agentislux.io بررسی کنید یا دادههای خام را در مخزن گیتهاب Perseus Clew ببینید.
گام بعدی شما
- سایت خود را در agentislux.io تست کنید تا متوجه شوید چه بخشهایی از محتواتان برای LLMها نامرئی است.
- در توسعه صفحات، اولویت را به HTML معنایی (Semantic HTML) بدهید و برای هر المان کلیدی، برچسب ARIA تعریف کنید.
- اگر از جاوااسکریپت برای رندر محتوای اصلی استفاده میکنید، یک نسخه سادهشده از متنها را در HTML خام قرار دهید تا عاملهای بازیابی سریعتر به شما برسند.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.



گفتگو