
تصور کنید یک تحلیلگر ارشد مالی باشید که باید در هر لحظه تصمیم بگیرد کدام خبر از میان هزاران گزارش شرکتی واقعاً حیاتی است. طبق گزارش ۳ جولای ۲۰۲۶ از آزمایشگاه AIA متعلق به Bridgewater و Thinking Machines، مدلهای عمومی هوش مصنوعی در این «سازهبندی سریع» (Triage) شکست میخورند.
این اتفاق نشان میدهد که برای استدلالهای سطح بالای مالی، پرامپتنویسی ساده دیگر کافی نیست. در واقع، ارزش واقعی نه در دانش عمومی مدل، بلکه در تخصص خصوصی سرمایهگذاران انسانی است. مدل زبانی بزرگ (LLM) — مثل کتابخانهداری که میلیاردها صفحه را خوانده و حالا با همان لحن کتابها جواب میدهد — در اینجا باید به یک متخصص پوست تبدیل شود؛ یعنی همان فرآیند تنظیم دقیق (Fine-tuning) که مدل کلی را روی یک حوزه تخصصی متمرکز میکند.
همانطور که در تحلیل قبلی ما دربارهی جایگزینی گردشهای کاری دستی توسط Claude اشاره کردیم، اتوماسیون کارهای پرزحمت در حال پیشرفت است، اما این بار هدف، دقت است نه فقط سرعت. این روند همراستا با تلاشهای شرکت Anthropic برای جایگزینی نرمافزارهای مالی سنتی است که میتواند جایگاه ارائهدهندگان دادههای مالی را تغییر دهد. پژوهشگران شش تکلیف پیچیده را بررسی کردند؛ برای مثال، تشخیص اینکه آیا یک سند بانک مرکزی سیگنالی برای تغییر نرخ بهره در آینده دارد یا خیر.
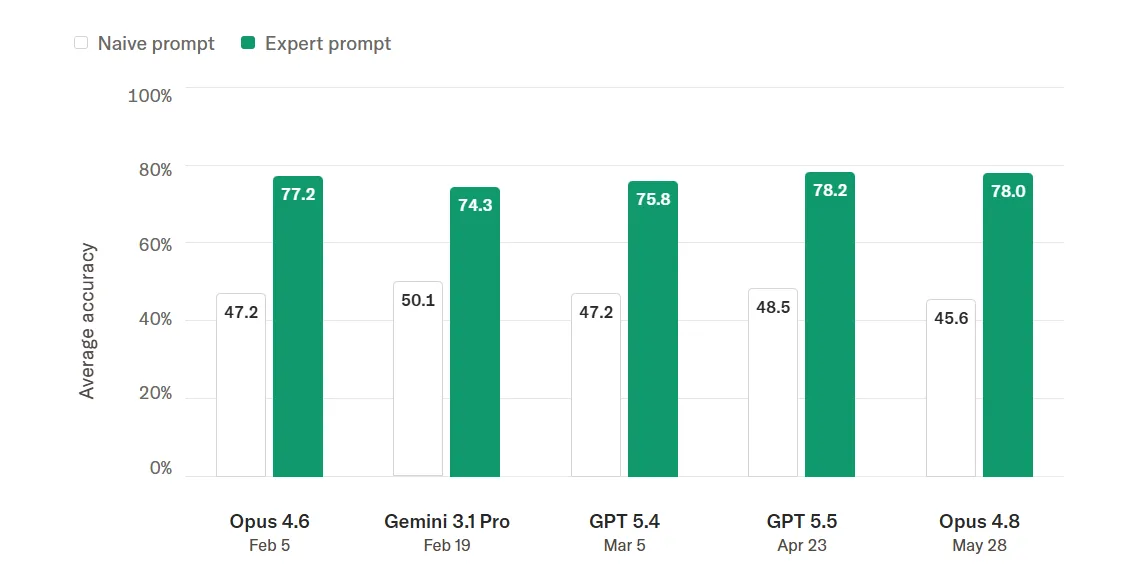
به نقل از این گزارش، مدلهای Gemini، Claude و GPT با پرامپتهای ساده تنها به دقت ۵۰٪ رسیدند. حتی با دستورالعملهای خبره و سیستم رتبهبندی سه سطحی، دقت آنها در محدوده ۷۰ تا ۸۰ درصد باقی ماند و نتوانستند به آستانه ۸۰٪ که برای استقرار قابلاعتماد لازم است، برسند.
برای رفع این مشکل، تیم از پلتفرم Tinker استفاده کرد تا مدل Qwen3-235B را تنظیم کند. آنها از یک روش هوشمند برای برچسبگذاری استفاده کردند: ابتدا یک مدل ارزانقیمت اختلافات بین برچسبهای پیمانکاران و پیشبینیهای AI را شناسایی میکرد و تنها موارد مورد مناقشه برای اصلاح نهایی به سرمایهگذاران انسانی گرانقیمت ارجاع داده میشد.
بر اساس مستندات این پروژه، نتایج نهایی خیرهکننده بود:
- مدل تنظیمشده به دقت ۸۴.۷٪ دست یافت.
- بهترین مدل پیشرو (Frontier) تنها ۷۸.۲٪ صحت داشت.
- راهکار وزنهای باز (Open Weights) — یعنی مدلی که «دستور پخت» آن علناً منتشر شده — ۱۴ برابر ارزانتر از مدلهای تجاری اجرا شد.
علاوه بر این، گزارش اشاره میکند که بازگشت سرمایه در مدلهای پرچمدار در حال کاهش است. برای مثال، GPT 5.4 حدود ۴۳٪ گرانتر از نسخه ۵.۲ بود، اما تنها بهبود اندکی در دقت ایجاد کرد.
این نتیجه یک چرخش استراتژیک برای سازمانهاست. ثابت شد که آزمایشگاههای بزرگ، دادههای ارزشمند و اختصاصی شرکتها را جذب نکردهاند. شرکتهایی که بهترین دادههای خود را به مدلهای عمومی میدهند، در واقع در حال ساخت ابزاری هستند که روزی رقیب آنها خواهد شد. در واقع، تکیه بر یک مدل واحد میتواند به یک ریسک تجاری تبدیل شود و لایههای مسیریابی هوشمندتر جایگزین مزیت رقابتی مدلهای تکسویه میشوند.
با تنظیم مدلهای باز، شرکتها کنترل کامل روی دادهها، وزنها و سختافزارهای خود دارند. این رویکرد، دانش سازمانی خصوصی را به یک «خندق رقابتی» تبدیل میکند که هوش مصنوعی عمومی نمیتواند آن را breached کند.
گام بعدی شما
- اگر دادههای تخصصی دارید، به جای تکیه بر پرامپتهای پیچیده، روی استراتژیهای تنظیم دقیق (Fine-tuning) مدلهای باز متمرکز شوید.
- هزینههای استنتاج مدلهای تجاری را با دقت مدلهای باز در حوزه کاری خود مقایسه کنید.
- برای پاکسازی دادههای اختصاصی، خط لولههای «انسان در حلقه» (Human-in-the-loop) را پیادهسازی کنید.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.



گفتگو