
اگر امروز از مدلهای استدلالی با زنجیره تفکر طولانی استفاده میکنید، میدانید که تأخیر در تولید پاسخ، بزرگترین نقطه ضعف این سیستمها است. اما DFlash با تغییر بنیادین در فرآیند پیشبینی توکنها، این سد محاسباتی را میشکند.
ماهیت خودبازگشتی (Autoregressive) در تولید متن، به این معناست که مدل باید هر توکن را یکییکی تولید کند. این رویکرد، گلوگاه اصلی استنتاج در مدلهای زبانی بزرگ (LLM) است. DFlash با پیشنهاد بلوکهای کامل از توکنها در یک گذر پیشرو (Forward Pass) واحد، شتابی بدون نقص (Lossless) تا ۶.۰۸ برابر در وظایف خاص و جهشی عظیم در توان عملیاتی روی سختافزارهای نسل بعد ایجاد کرده است.
سالها بود که رمزگشایی گمانهزنانه (Speculative Decoding) بر پایه یک مدل پیشنویس کوچک بود که توکنهای آینده را حدس میزد و سپس یک مدل هدف بزرگتر آنها را تأیید میکرد. با این حال، اکثر متدهای پیشرفته فعلی، مانند EAGLE-3، هنوز این توکنها را بهصورت خودبازگشتی و یکی پس از دیگری پیشنویس میکنند. این امر منجر به ایجاد یک حلقه متوالی میشود که باعث میگردد قدرت محاسباتی عظیم GPUهای مدرن، بهویژه در خروجیهای طولانی مورد نیاز برای مدلهای استدلالی (Chain-of-Thought)، که در آنها تأخیر به بخش غالب تولید تبدیل میشود، بلااستفاده بماند.
DFlash که توسط تیم پژوهشی z-lab در دانشگاه سندیگو معرفی و توسط مهندسان NVIDIA اعتبارسنجی شده است، پیشنویس متوالی را با یک مدل انتشار (Diffusion Model) سبک و بلوکی جایگزین میکند. برخلاف تلاشهای قبلی مبتنی بر انتشار، DFlash قصد ندارد دقت مدل هدف را جایگزین کند؛ بلکه تنها نیاز دارد «به اندازه کافی خوب» باشد تا تأیید موازی مدل هدف، توزیع نهایی را بدون نقص تضمین کند. این رویکرد، مشکلات رایج مدلهای زبانی مبتنی بر انتشار مستقل را دور میزند؛ مشکلاتی مانند عقب ماندن از مدلهای خودبازگشتی در دقت یا کند شدن به دلیل مراحل متعدد حذف نویز (Denoising).
معماری انتشار بلوکی
نوآوری اصلی در انتقال از پیشنویس توکنبه-توکن به حذف نویز موازی بلوکی (Parallel Block Denoising) است. DFlash تولید موازی را با یک ساختار بلوکی خودبازگشتی ترکیب میکند. از آنجایی که یک پیشنویس انتشار، تمام توکنها را در یک گذر موازی تولید میکند، تأخیر پیشنویس با رشد اندازه بلوک تقریباً ثابت (Flat) میماند. این یک بهبود چشمگیر نسبت به پیشنویسهای خودبازگشتی است که هزینههای آنها بهصورت خطی با تعداد توکنهای گمانهزن رشد میکند.
مشخصات فنی کلیدی این معماری عبارتند از:
- اندازه مدل: یک پیشنویس بسیار سبک ۵ لایهای (که برای مدل Qwen3-Coder به ۸ لایه گسترش یافت). این ساختار بسیار کوچکتر از روشهای انتشار قبلی مانند DiffuSpec و SpecDiff-2 است که از مدلهای غولپیکر ۷ میلیارد پارامتری استفاده میکردند و سرعت را تنها در محدوده ۳ تا ۴ برابر محدود میکردند.
- تزریق ویژگی (Feature Injection): مدل DFlash حالتهای پنهان (Hidden States) را از چندین لایه مدل هدف استخراج کرده و آنها را در یک ویژگی زمینه (Context Feature) متراکم ادغام میکند تا مدل پیشنویس را شرطی کند.
- یکپارچگی KV Cache: برخلاف EAGLE-3 که ویژگیهای هدف را تنها در Embeddingهای ورودی پیشنویس تزریق میکرد (جایی که سیگنال با افزایش عمق لایهها رقیق میشود)، DFlash این ویژگیها را مستقیماً در تصویرسازیهای Key و Value (پروژکسیونهای کلید و مقدار) در هر یک از لایههای پیشنویس تزریق میکند.
این ویژگیهای تصویرشده در KV Cache پیشنویس قرار میگیرند و در طول تکرارها باقی میمانند. این رویکرد که بر این اصل استوار است که «مدل هدف بهتر میداند» (Target Knows Best)، اجازه میدهد طول پذیرش توکنها با عمق پیشنویس مقیاسپذیر شود. در آزمایشهای عملی، یک پیشنویس ۵ لایهای DFlash که ۱۶ توکن تولید میکرد، از نظر تأخیر و نرخ پذیرش، عملکرد بهتری نسبت به EAGLE-3 با ۸ توکن داشت.
بنچمارکهای سرعت
به نقل از گزارش فنی منتشر شده در اوایل ۲۰۲۶ (arXiv 2602.06036)، DFlash در بنچمارکهای مختلف با استفاده از مدل Qwen3-8B (با بکاند Transformers و دمای ۰)، از EAGLE-3 پیشی گرفت. در وظیفه MATH-500، مدل DFlash به اوج شتاب ۷.۸۷ برابر ($\tau = 7.87$) رسید، در حالی که EAGLE-3 تنها ۱.۸۱ برابر را ثبت کرد. بهطور میانگین در تمام وظایف آزمایش شده، DFlash شتاب ۶.۴۹ برابری را نسبت به خط پایه ۱.۰۰ برابر ثبت کرد، در حالی که EAGLE-3 در اندازه درخت ۱۶ توکن به میانگین ۱.۷۶ برابر و در اندازه درخت ۶۰ توکن به ۲.۰۲ برابر رسید.
جزئیات عملکرد به تفکیک هر وظیفه روی مدل Qwen3-8B نشاندهنده دستاوردهای قابلتوجه است:
- GSM8K: مدل DFlash (۱۶ توکن) به شتاب ۵.۱۵ برابر رسید در حالی که EAGLE-3 مقدار ۱.۹۴ برابر را ثبت کرد.
- AIME25: مدل DFlash (۱۶ توکن) به ۵.۶۲ برابر رسید در مقابل ۱.۷۹ برابر برای EAGLE-3.
- HumanEval: مدل DFlash (۱۶ توکن) به ۵.۱۴ برابر رسید در مقابل ۱.۸۹ برابر برای EAGLE-3.
- MBPP: مدل DFlash (۱۶ توکن) به ۴.۶۵ برابر رسید در مقابل ۱.۶۹ برابر برای EAGLE-3.
- LiveCodeBench: مدل DFlash (۱۶ توکن) به ۵.۵۱ برابر رسید در مقابل ۱.۵۷ برابر برای EAGLE-3.
- MT-Bench: مدل DFlash (۱۶ توکن) به ۲.۷۵ برابر رسید در مقابل ۱.۶۳ برابر برای EAGLE-3.
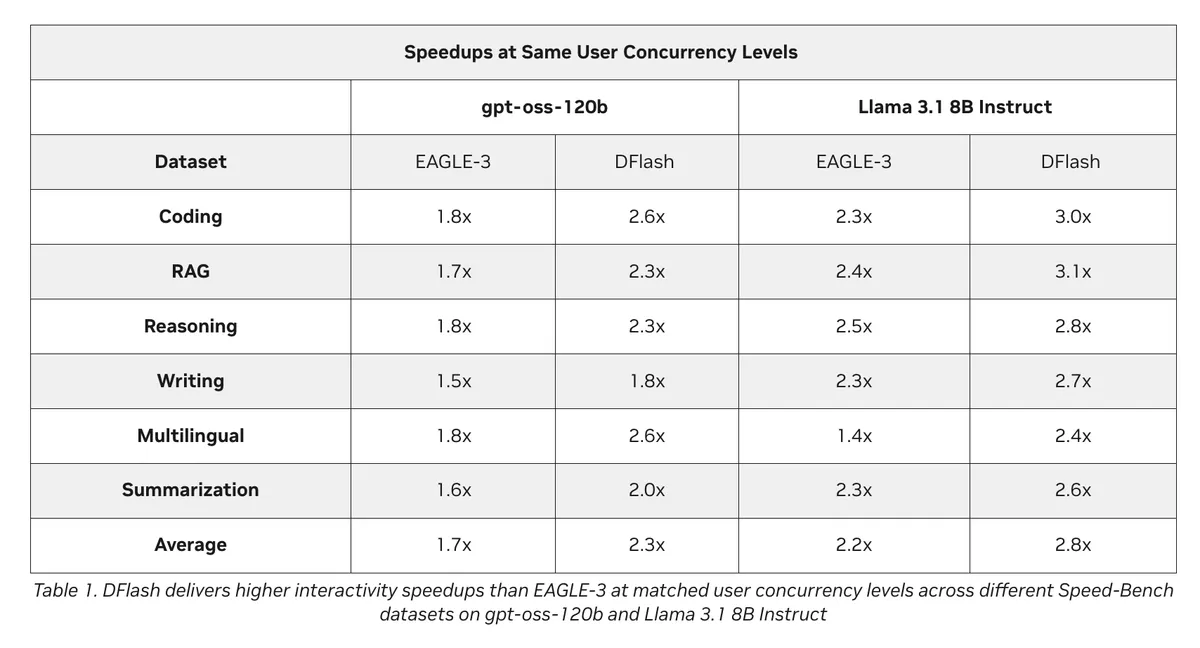
بر روی یک سیستم DGX B300 مجهز به هشت GPU NVIDIA Blackwell، این دستاوردها باز هم مقیاسپذیرتر شدند. با استفاده از TensorRT-LLM و مدل gpt-oss-120b، انویدیا گزارش داد که DFlash توان عملیاتی بیش از ۱۵ برابر نسبت به رمزگشایی خودبازگشتی استاندارد در یک هدف تعاملی ثابت (۵۰۰ تا ۶۰۰ توکن در ثانیه برای هر کاربر) فراهم میکند. این مقدار تقریباً ۱.۵ برابر بیشتر از توان عملیاتی EAGLE-3 در همان نقطه است. علاوه بر این، معیار NVIDIA Speed-Bench سرعت تعاملی را در همگرایی (Concurrency) یکسان اندازهگیری کرد: DFlash در مدل Llama 3.1 8B Instruct میانگین ۲.۸ برابر (در مقابل ۲.۲ برای EAGLE-3) و در مدل gpt-oss-120b میانگین ۲.۳ برابر (در مقابل ۱.۷ برای EAGLE-3) شتاب داشت.
یکپارچهسازی در دنیای واقعی
استقرار DFlash برای کمترین اصطکاک از طریق نقاط بازرسی (Checkpoints) و پشتیبانی از چارچوبها طراحی شده است. کاربران میتوانند با جایگزینی یک پیکربندی EAGLE-3 با یک پیکربندی DFlash در vLLM، بدون نیاز به بازنویسی کد اپلیکیشن، سیستم را پیادهسازی کنند. برای مثال با استفاده از دستور:vllm serve Qwen/Qwen3.5-27B --speculative-config '{"method": "dflash", "model": "z-lab/Qwen3.5-27B-DFlash", "num_speculative_tokens": 15}'
بستر Transformers نیز از مدلهای Qwen3 و LLaMA-3.1 از طریق فراخوانی spec_generate پشتیبانی میکند. این قابلیت به توسعهدهندگان اجازه میدهد تا یک مدل پیشنویس (مانند z-lab/Qwen3-8B-DFlash-b16) را بهراحتی با یک مدل هدف (مانند Qwen/Qwen3-8B) جفت کنند.
این ویژگی DFlash را بهویژه برای سه مورد کاربردی خاص بسیار قدرتمند میکند:
۱. عاملهای کدنویسی (Coding Agents): در این کاربرد، پاسخهای سریع و تعاملی حیاتی هستند. انویدیا در مدل Gemma 4 31B با استفاده از vLLM، تا ۵.۸ برابر شتاب در Math500 و ۵.۶ برابر در HumanEval در همگرایی ۱ گزارش کرد.
۲. مدلهای استدلالی: ردپاهای طولانی زنجیره تفکر (Chain-of-Thought) زمان تولید را اشغال میکنند. با فعالسازی حالت تفکر (Thinking Mode)، مدل DFlash در حالت Greedy decoding حدود ۴.۵ برابر و در حالت نمونهبرداری (Sampling) روی مدلهای Qwen3-4B و 8B حدود ۳.۹ برابر شتاب دارد.
۳. سرویسدهی با تراکم بالا (High-Concurrency): روی سیستم SGLang با استفاده از GPU B200، این مدل به شتاب ۵.۱ برابری در Qwen3-8B (در وظیفه Math500 و همگرایی ۱) رسید. اگرچه با افزایش همگرایی، میزان دستاوردها کاهش مییابد اما همچنان مثبت باقی میماند و هزینههای کلی سرویسدهی را کاهش میدهد.
این تغییر در معماری، این فرض رایج در این حوزه را که عمق مدل پیشنویس لزوماً باعث افزایش تأخیر میشود، تغییر میدهد. DFlash با بهرهگیری از بینش «مدل هدف بهتر میداند»، عملاً مانند یک آداپتور انتشار روی مدل هدف عمل میکند و اجازه میدهد طول پذیرش توکنها بدون جریمه هزینه خطی، مقیاسپذیر شود.
توسعهدهندگان اکنون میتوانند به نقاط بازرسی DFlash از طریق Hugging Face دسترسی داشته باشند و پیادهسازی آن را در GitHub بررسی کنند تا خط لولههای استنتاج خود را برای سختافزارهای سطح Blackwell بهینه کنند.
گام بعدی شما
- بررسی نقاط بازرسی DFlash در Hugging Face برای بهینهسازی خط لولههای استنتاج.
- تست جایگزینی پیکربندی DFlash در vLLM برای کاهش تأخیر در مدلهای کدنویسی.
- مطالعه پیادهسازی GitHub برای درک نحوه تزریق ویژگیها به KV Cache.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.



گفتگو