تصور کنید یک مهندس نرمافزار هفتهها وقت صرف کند تا هسته مرکزی یک سیستم پیچیده را بدون دسترسی به کد منبع بازنویسی کند؛ اکنون هوش مصنوعی دقیقاً همین کار را انجام میدهد. این سطح از استقلال، تفاوت بنیادین میان یک دستیار ساده و یک عامل تمامعیار است.
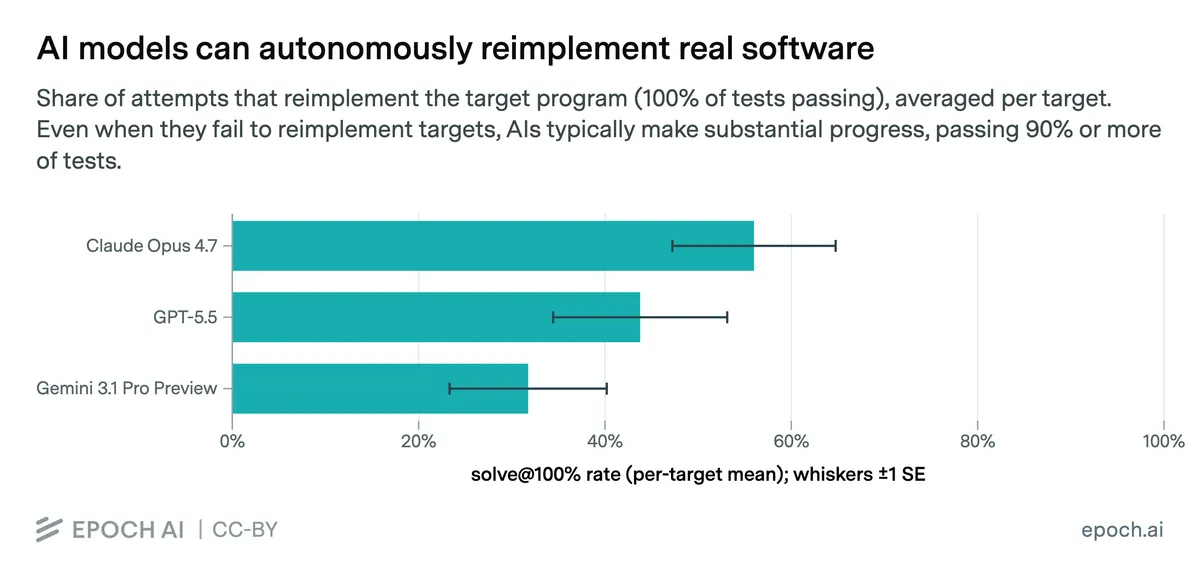
طبق اعلام Epoch AI و METR، مدل Claude Opus 4.7 توانست ۵۶٪ از تکالیف برنامهنویسی MirrorCode را با موفقیت حل کند. این نتیجه ثابت میکند که مدلها دیگر تنها به تولید قطعات کوچک کد (Snippets) محدود نیستند و میتوانند پروژههای مهندسی سخت و بلندمدت را پیش ببرند.
همانطور که در پوشش پیشین ما دربارهی امنیت مدلهای بازمتن دیدیم، تمرکز صنعت از تولید محتوا به سمت اجرای عملیاتی تغییر کرده است. در حالی که ابزارها پیشتر بر روی خودکارسازی مستندات تمرکز داشتند، MirrorCode توانایی مدلها در ساخت هسته عملکردی یک سیستم را از نقطه صفر میسنجد. این یک چرخش از حالت «کمکخلبان» (Copilot) به سمت اجرای عاملمحور (Agentic) است. این پیشرفت در برنامهنویسی تضاد جالبی با سایر حوزهها دارد؛ چرا که در بخشهای اداری، تنها ۳٪ از وظایف پیچیده توسط پیشرفتهترین مدلها حل شده است و نشان میدهد شکاف عملکردی میان کدنویسی و کارهای اداری همچنان عمیق است.
بر اساس گزارش منتشر شده در ۲۶ ژوئن ۲۰۲۶، محک MirrorCode شامل ۲۵ برنامه هدف در حوزههای رمزنگاری، بیوانفورماتیک و تحلیل ایستا است. برخلاف محکهای سنتی که هزینه استنتاج (Inference) را محدود میکنند، MirrorCode بودجههای محاسباتی عظیمی را برای شبیهسازی چرخههای واقعی مهندسی در نظر گرفته است.
عملکرد و هزینههای بنچمارک
- Claude Opus 4.7: حل ۵۶٪ تکالیف؛ از جمله یک ابزار بیوانفورماتیک (gotree) با ۱۶,۰۰۰ خط کد Go در ۱۴ ساعت و با هزینه ۲۵۱ دلار.
- GPT-5.5: نرخ موفقیت ۴۴٪، اما هزینه اجرای آن برای تکالیف مشابه سه برابر بیشتر از نسل قبلی بود.
- Gemini 3.1 Pro Preview: با نرخ موفقیت ۳۲٪ در جایگاه سوم قرار گرفت.
بر اساس مستندات این پژوهش، یکی از افراطیترین موارد، تکلیفی بود که هزینه آن به ۲,۶۰۰ دلار رسید و مدل برای ۱۹ روز متوالی، بدون هیچ دخالت انسانی، در حال اجرا بود. با این حال، محققان سقف مشخصی را شناس کردند: در حالی که برنامههای «کوچک» با اطمینان هندل میشوند، هیچ مدلی نتوانست گرههای پیچیده در دسته برنامههای «بزرگ» را بگشاید.
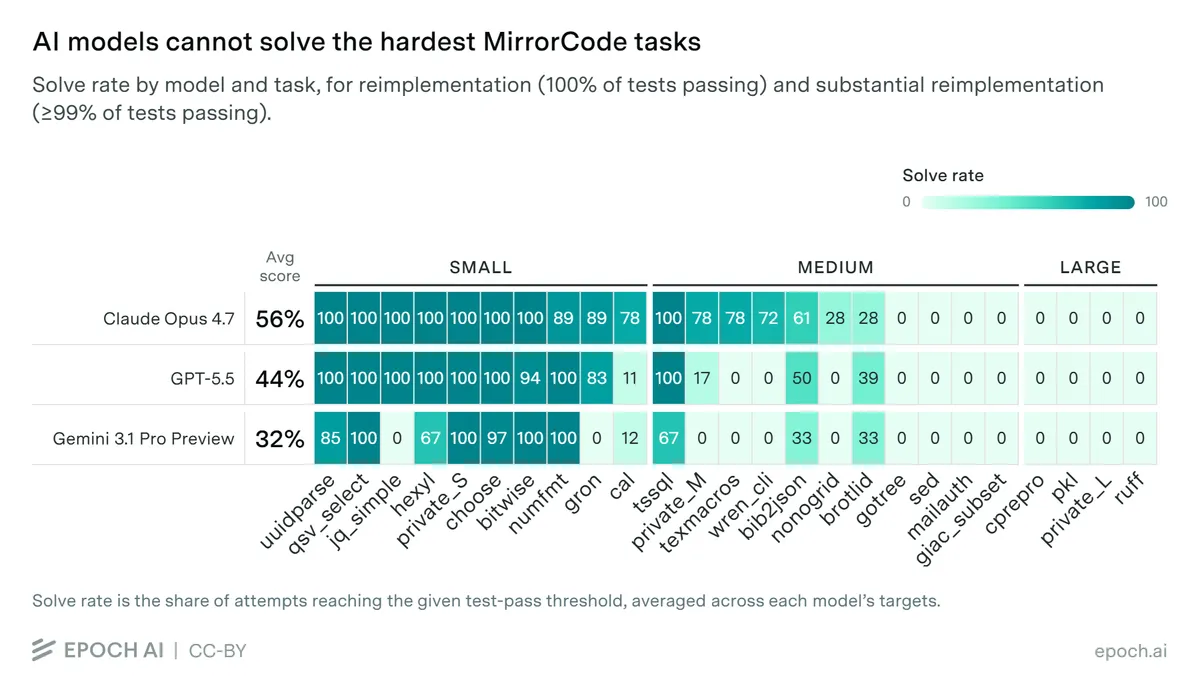
برای متخصصان فنی، این نتایج پیشفرضهای مربوط به «مسائل سخت برنامهنویسی» را تغییر میدهد. اینکه مدلها ۹۰٪ تستهای واحد را حتی در صورت شکست در بازپیادهسازی کامل پاس میکنند، نشان میدهد که صلاحیت عملکردی بالایی وجود دارد و تنها مانع اصلی، «آخرین مایل» یا همان یکپارچهسازی نهایی پیچیده است. در این میان، چالش مدیریت کد تولید شده همچنان پابرجاست، چرا که بسیاری از توسعهگران متوجه شدهاند دیباگ کردن کدهای AI میتواند هزینهبرتر از نوشتن دستی آنها باشد.
البته یک نکته حیاتی وجود دارد. Epoch AI اشاره میکند که چون اهداف این آزمون از کدهای بازمنبع گرفته شدهاند، احتمال دارد مدلها در طول پیشآموزش با آنها مواجه شده باشند و بخشی از نتایج ناشی از حافظه (Memorization) باشد نه استدلال خالص.
برای پیشبرد این حوزه، Epoch AI اکنون ۲۲ برنامه از ۲۵ هدف و زیرساخت تست را بهصورت بازمنبع منتشر کرده است که ۱۳۲ مورد را در ۶ زبان مختلف پوشش میدهد. شما میتوانید از این ابزارها برای استرستست جریانهای کاری عاملمحور داخلی خود استفاده کنید.
گام بعدی شما
- بررسی مخزن بازمنبع MirrorCode برای ارزیابی توانایی مدلهای داخلی در بازنویسی سیستمهای Legacy.
- مقایسه هزینه استنتاج در مقابل نرخ موفقیت برای بهینهسازی بودجههای GPU در پروژههای بلندمدت.
- مطالعه متدولوژی METR برای درک نحوه مدیریت عاملهایی که نیاز به اجرای چندروزه دارند.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.



گفتگو