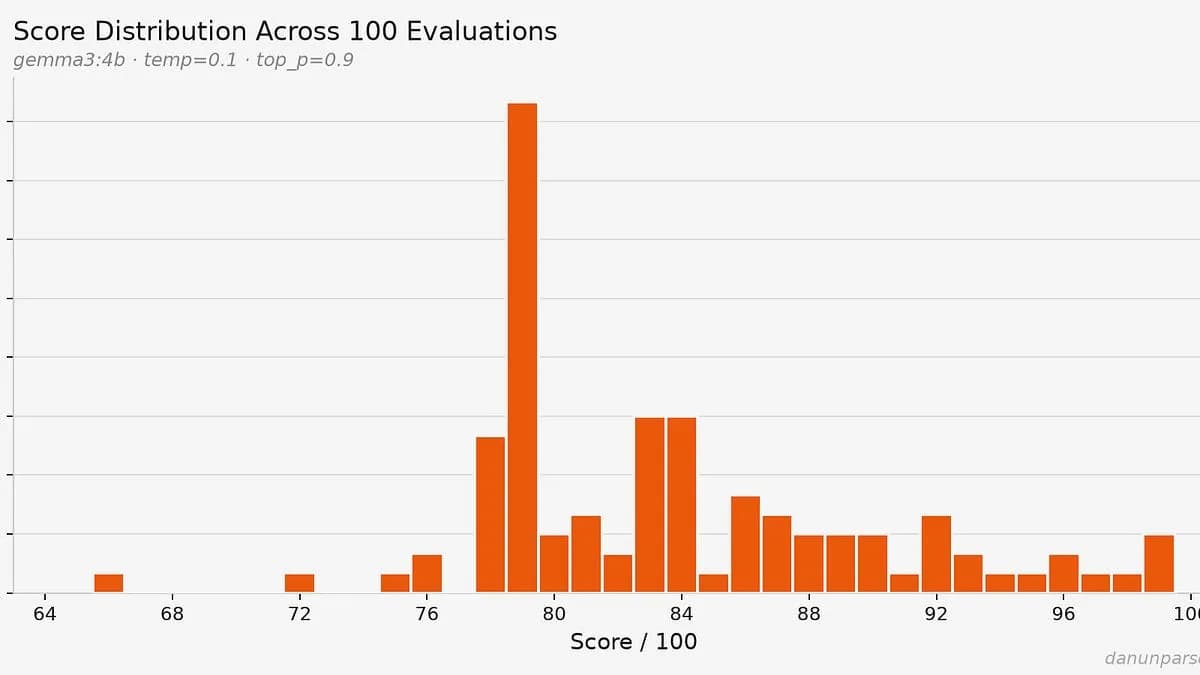
تصور کنید متقدیترین رزومه شغلی شما، در یک لحظه نمره عالی میگیرد و در لحظهای دیگر، توسط یک ربات رد میشود؛ آن هم بدون اینکه تککلمهای در متن تغییر کرده باشد. طبق یک ممیزی فنی در ۲۹ ژوئن ۲۰۲۶، غربالگری رزومهها با هوش مصنوعی ممکن است بهجای عدالت، شبیه به پرتاب تاس باشد. بر اساس این مطالعه، یک رزومه واحد در عامل استخدام (Hiring Agent) متنباز HackerRank نمراتی بین ۶۶ تا ۹۹ دریافت کرده است.
در حالی که تیمهای جذب استعداد برای مدیریت حجم انبوه متقاضیان، بررسی دستی را با مدلهای زبانی بزرگ (LLM) — که شبیه کتابخانهداری است که میلیاردها صفحه را خوانده و حالا با همان لحن جواب میدهد — جایگزین میکنند، این تغییر مسیر، استخدام را به یک «جعبه سیاه» تبدیل کرده است. این روند با گزارشهای پیشین ما همسو است که در آن ابزارهای هوش مصنوعی با رد کردن ۶۵٪ متقاضیان، سدی الگوریتمی در مسیرe استخدام ایجاد کردهاند. در این وضعیت، سرنوشت متقاضی بهجای مهارتهای واقعی، به ماهیت تصادفی خروجی مدل وابسته است.
زمینه و ابزارها
همانطور که در تحلیلهای قبلی ما دربارهی توهمات مدلهای زبانی اشاره کردیم، عدم قطعیت در پاسخها یکی از چالشهای بنیادی این فناوری است. ابزار مذکور که با نام hiring-agent در گیتهاب میزبانی میشود، اخیراً در لینکدین و ردیت توجه زیادی جلب کرده و در پستهایی با صدها یا هزاران لایک ظاهر شده است. هدف این ابزار، خودکارسازی مرحله اولیه غربالگری از طریق تبدیل اسناد خام به یک امتیاز عددی است.
طبق مستندات فنی، سازوکار این ابزار به صورت زیر است:
- فایل PDF شما به متن خام تبدیل (Parse) میشود.
- یک مدل زبانی ۶ بار فراخوانی میشود تا اطلاعات ساختاریافته را استخراج کند: اطلاعات پایه، سوابق کاری، تحصیلات، مهارتها، پروژهها و جوایز.
- عامل ابزار پروفایل گیتهاب شما را فراخوانی کرده و مخازن (Repositories) برتر را اسکن میکند تا زمینههای اضافی را به دادهها اضافه کند.
- تمام دادههای ترکیبی به صورت یکجا برای نمرهگذاری نهایی به مدل زبانی ارسال میشوند.
این سیستم وزنهای مشخصی برای امتیازدهی دارد: مشارکت در پروژههای متنباز (۳۵ امتیاز)، پروژههای شخصی (۳۰ امتیاز)، سوابق کاری (۲۵ امتیاز) و مهارتهای فنی (۱۰ امتیاز). علاوه بر این، تا ۲۰ امتیاز پاداش برای داشتن تجربه در استارتاپها، داشتن سایت پورتفولیو یا نوشتن وبلاگهای فنی در نظر گرفته شده است.
آزمایشها و عدم قطعیت (Non-Determinism)
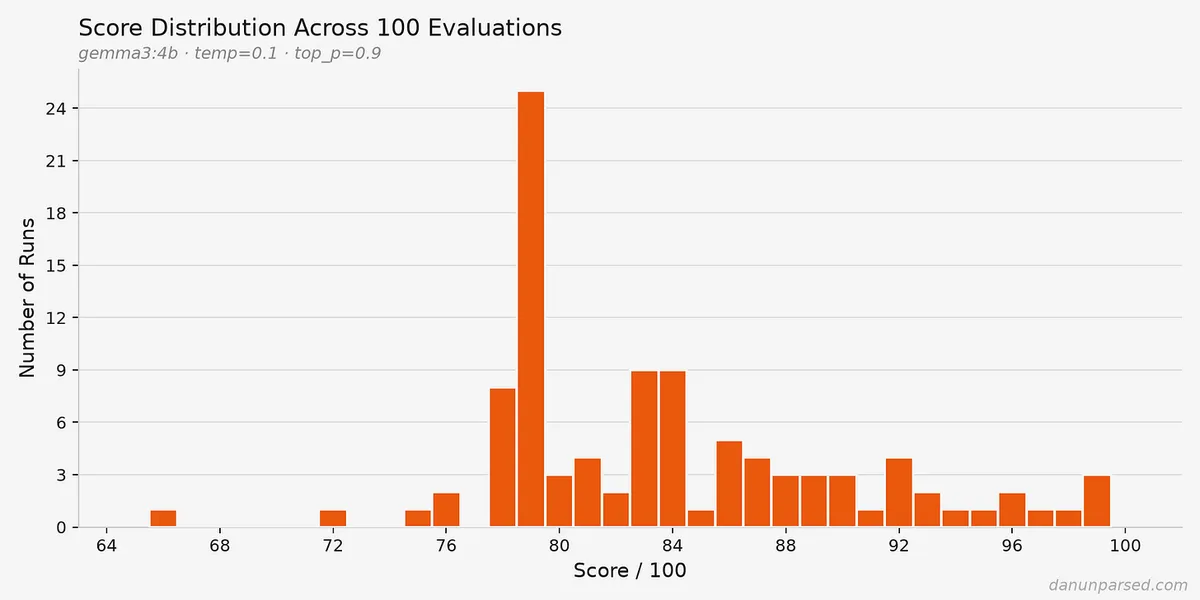
در بررسیهای انجام شده با مدل پیشفرض gemma3:4b و تنظیم دما (Temperature) — که مانند پیچ تنظیم خلاقیت مدل است و هرچه کمتر باشد، مدل پاسخهای خشکتر و تکرارپذیرتری میدهد — روی ۰.۱، ناسازگاریهای عمیقی دیده شد. دمای پایین برای سوق دادن مدل به سمت خروجیهای قطعی (Deterministic) انتخاب شده بود، اما باز هم شکست خورد. در یک تست، اجرای اول نمره ۹۰ از ۱۰۰ گرفت، اما پس از حذف سادهی چند عبارت چاپ عیبیابی (Debug print statements) و اجرای مجدد دقیقاً همان رزومه و دستور، نمره به ۷۴ سقوط کرد.
به گزارش این ممیزی، وقتی مدل در یک حلقه ۱۰۰ تایی در حالی که حالت توسعه (DEVELOPMENT_MODE) غیرفعال بود اجرا شد، نمرات بین ۶۶ تا ۹۹ متغیر بود. این یعنی اگر خط برش یک شرکت ۸۵ باشد، یک کاندیدای واحد ۶۵٪ مواقع فقط به دلیل «بدشانسی» رد میشود.
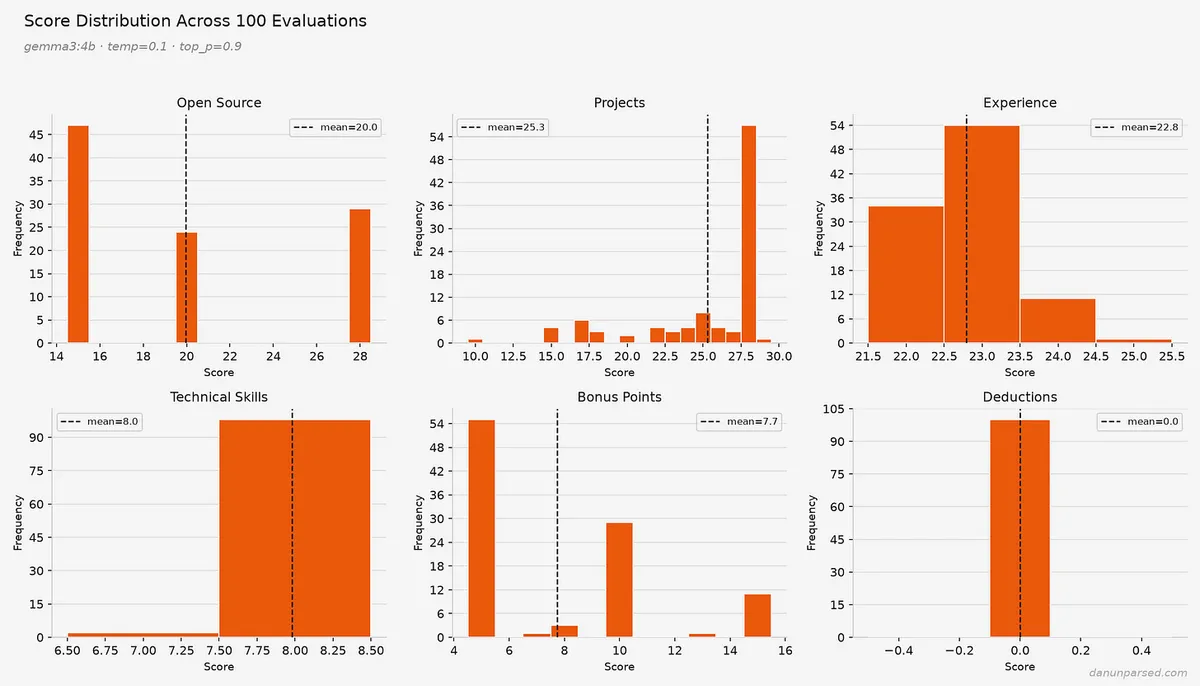
دلیل این نوسان، دستهبندی «پروژهها» است. در حالی که بخش مهارتهای فنی (به دلیل چکلیستی بودن) پایدار بود و در ۹۸ مورد از ۱۰۰ اجرا، نمره ۸ از ۱۰ گرفت، مدل در مورد اینکه آیا یک پروژه «فاقد پیچیدگی معماری» است یا «استقرار واقعی در دنیای واقعی را نشان میدهد»، هر بار نظر متفاوتی داد.
این ناپایداری صرفنظر از تنظیمات باقی میماند. حتی در دمای ۰ نیز مشکل حل نشد. یک گزارش (Issue) در گیتهاب از ماه اکتبر نشان داد که کاربری در ۶ اجرای متوالی با دمای ۰.۲، نمراتی شامل ۲۷، ۳۴، ۳۲، ۳۴، ۳۴ و ۳۰ دریافت کرده است.
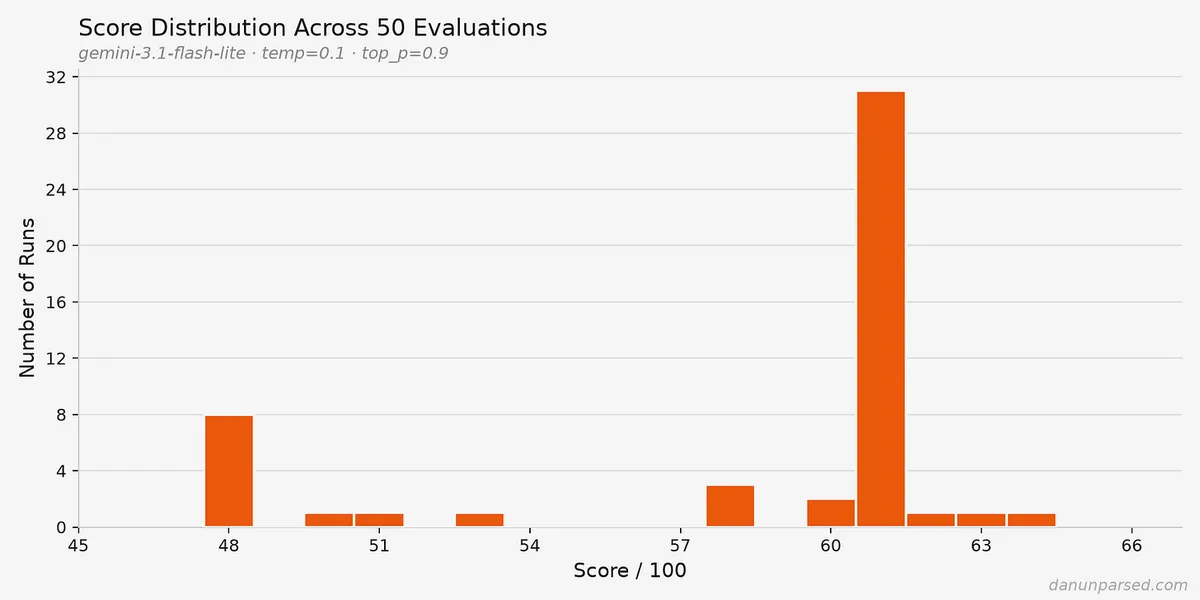
تغییر مدل به Gemini نیز این نقص بنیادی را حل نکرد. اگرچه نمرات در بازه ۴۸ تا ۶۴ متمرکزتر (Cluster) شدند، اما کاندیدایی که نیاز به نمره ۶۰ داشت، باز هم در ۲۸٪ موارد رد میشد، در حالی که رزومهاش هیچ تغییری نکرده بود.
تناقض تجربه
یک تناقض عجیب در بخش «تجربه» مشاهده شد. طبق یافتههای ممیزی، این دسته سازگار بود اما عملاً بیفایده. هم یک مهندس جونیور با تنها یک دوره کارآموزی و هم یک مهندس ارشد (Principal Engineer) با یک دهه تجربه در سیستمهای توزیعشده، نمره کامل ۲۵ از ۲۵ را دریافت کردند.
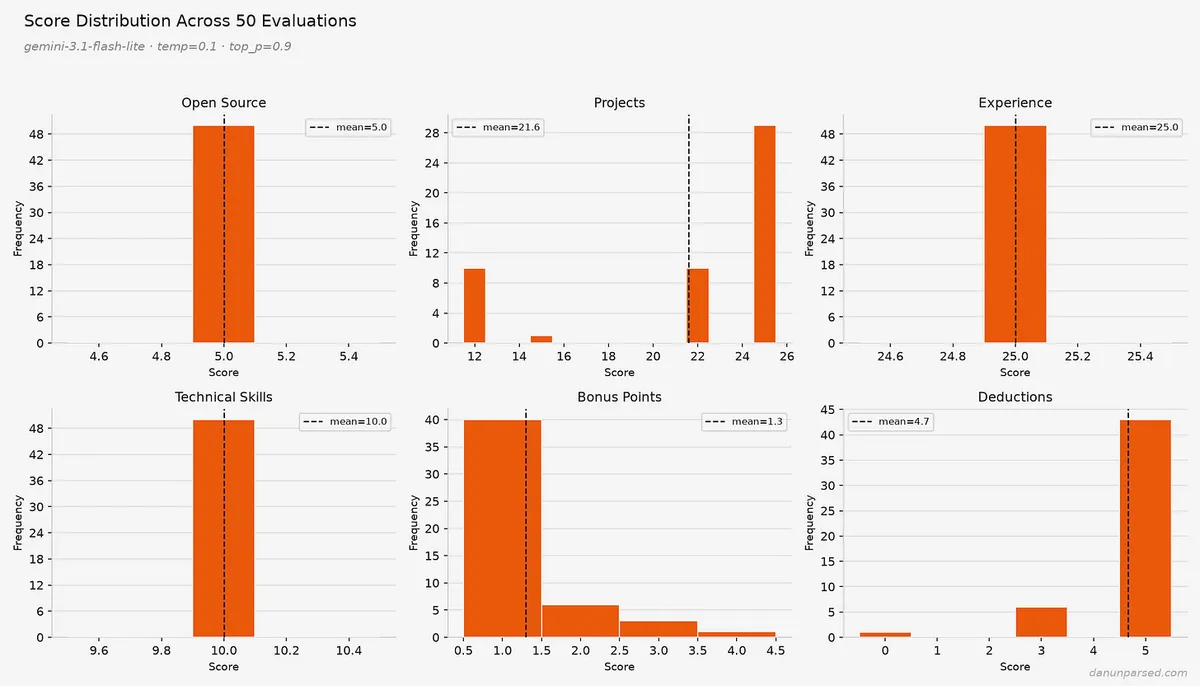
این اتفاق به این دلیل رخ میدهد که سیستم فاقد یک معیار (Rubric) دقیق یا «لنگرهای سنجشی» برای تفکیک ارشدیت است. پرامپت (Prompt) این بخش تنها دو خط است. بدون ارائه مثالها یا لنگرهایی که تعریف کنند چه چیزی نمره ۱۵ یا ۲۵ میگیرد، مدل صرفاً یک «بررسی کلی» یا Vibe-check انجام میدهد که نمیتواند تخصص سطح بالا را از تجربه ابتدایی تشخیص دهد.
نقصهای طراحی و ریسکها
این ناپایداری یک باگ نیست که با تنظیم دقیق (Fine-tuning) — که شبیه تخصص دادن به یک پزشک عمومی در یک رشته خاص است — حل شود، بلکه یک نقص طراحی است. وقتی ۶۵٪ نمره به بخشهایی (متنباز و پروژهها) اختصاص یابد که مدلهای زبانی در قضاوت عینی آنها مشکل دارند، عمق تجربه حرفهای که در گیتهاب نیست، کاملاً نادیده گرفته میشود.
علاوه بر این، یک اصلاحیه در ۲۸ ژوئن اشاره کرد که در قالب resume_evaluation_criteria.jinja در خط اول صراحتاً به «کارآموز نرمافزار» (Software Intern) اشاره شده است، اما این موضوع در هیچ جای دیگر مستند نشده است. با این حال، همین قالب همزمان به نقشهای مؤسس (Founder) یا مهندسان مراحل اولیه امتیاز پاداش میدهد. حتی با وجود یک پرامپت صریح برای مهندس ارشد (Senior SWE)، ابعاد نمرهگذاری نسبت به جایگاه شغلی بیتفاوت (Agnostic) باقی میمانند.
برای مهندسان و مدیران منابع انسانی، این بدان معناست که غربالگری با AI ممکن است بهجای کیفیت، «شانس» را فیلتر کند. ابزاری که نمیتواند پیچیدگی پروژه یا ارشدیت را تشخیص دهد، یک فیلتر نیست؛ بلکه یک تولیدکننده عدد تصادفی است که نقش دروازهبان را بازی میکند. کسانی که بر خط لولههای استخدام نظارت دارند باید به سمت استفاده از LLMها برای استخراج دادههای ساختاریافته و تایید چکلیستها حرکت کنند، در حالی که قضاوت کیفی تجربه را در دستان انسانها نگه دارند.
گام بعدی شما
- اگر از ابزارهای Agentic برای غربالگری استفاده میکنید، نمرات را در چند دور اجرا (Iterative execution) تست کنید تا میزان واریانس را بسنجید.
- مدلهای زبانی را فقط برای استخراج دادههای ساختاریافته و چکلیستها به کار ببرید و قضاوت کیفی را به انسانها بسپارید.
- برای کاهش نوسان، از تکنیکهای Few-shot prompting و ارائه نمونههای دقیق از نمرات (Rubrics) استفاده کنید.
اما تأثیر این ناپایداری بر عدالت در استخدام، تنها بخشی از داستان است؛ در تحلیل ما دربارهی سوگیریهای الگوریتمی در مدلهای استدلالی، ابعاد تاریکتری از این روند را بررسی کردیم.



گفتگو