
تصور کنید یک دستیار هوشمند دارید که ساعتها بدون وقفه، خطاهای API یا هزینههای سرسامآور، روی یک پروژه پیچیده کدنویسی کار کند. اگر هنوز فکر میکنید برای اجرای عاملهای پیشرفته به ابرهای عظیم گوگل یا مایکروسافت نیاز دارید، باید بدانید که قواعد بازی تغییر کرده است.
در دنیای امروز، شکاف میان مدلهای تجاری بسته و مدلهای وزنهای باز (Open Weights) — تشبیه روزمره: یعنی «دستور پخت» مدل علناً منتشر شده، نه فقط غذای آماده — در حال بسته شدن است. در حالی که مدلهای تریلیونی هنوز در «دوهای سرعت» یا همان پاسخهای تکمرحلهای برنده هستند، اما توانایی میزبانی یک مدل استدلالی (Reasoning Model) — تشبیه روزمره: مدلی که قبل از جواب، یک قدم درنگ میکند و فکر میکند — مثل شطرنجبازی که چند حرکت جلوتر را میبیند — روی سختافزار شخصی، اقتصادِ کارهای خودکار را دگرگون میکند.
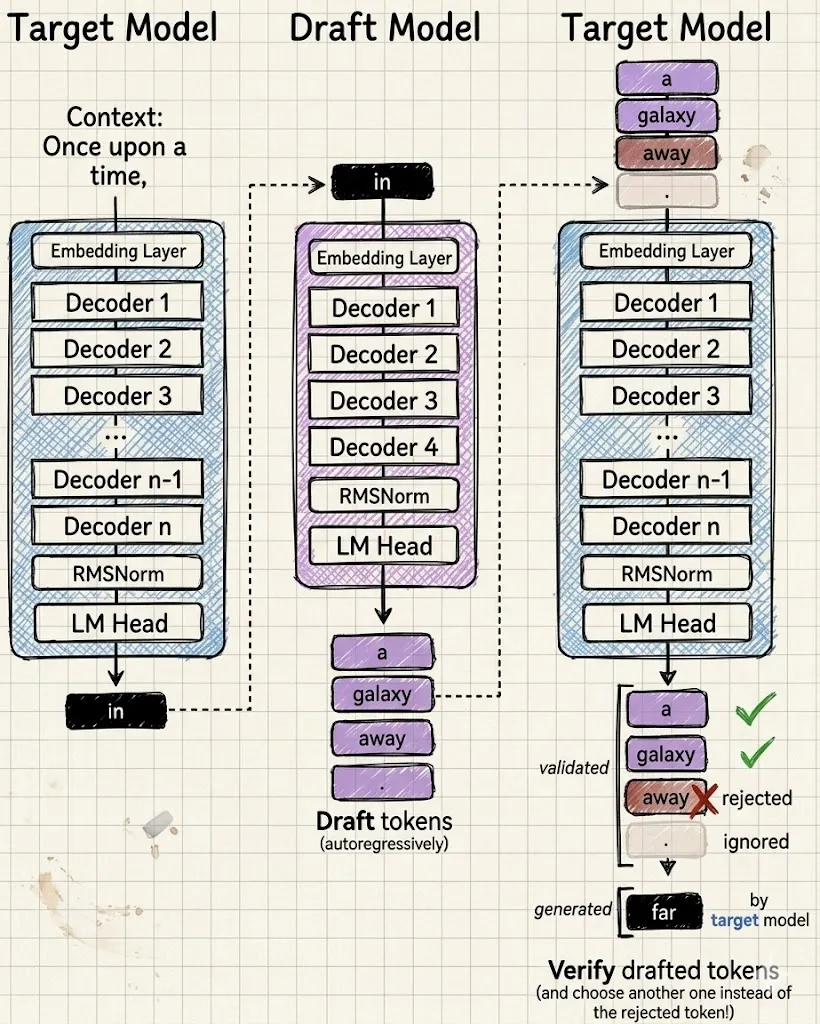
همانطور که در تحلیل قبلی ما دربارهی امنیت مدلهای بازمتن اشاره کردیم، مالکیت سختافزاری ریسک قطع شدن سرویسها و اتمام سهمیه (Quota) را حذف میکند. به نقل از یک گزارش فنی در ۸ مه ۲۰۲۶ در وبسایت dev.to، رمز این موفقیت در تکنولوژی پیشبینی چند-توکنی (Multi-Token Prediction یا MTP) نهفته است. در این سازوکار، مدل بهجای پیشبینی یک کلمه، چندین توکن آینده را بهطور همزمان حدس میزند. این یعنی یک مدل کوچک ۰.۵ میلیارد پارامتری بهعنوان «پیشنویس»، توالیها را پیشنهاد میدهد و مدل اصلی Gemma 4 31B آنها را در یک گذر موازی تأیید میکند.
برای مدیریت این حجم از داده، ابزار vLLM از قابلیت PagedAttention استفاده میکند تا از تکهتکه شدن حافظه VRAM جلوگیری کند. جزئیات فنی این معماری روی سختافزارهایی مثل RTX 5090 به شرح زیر است:
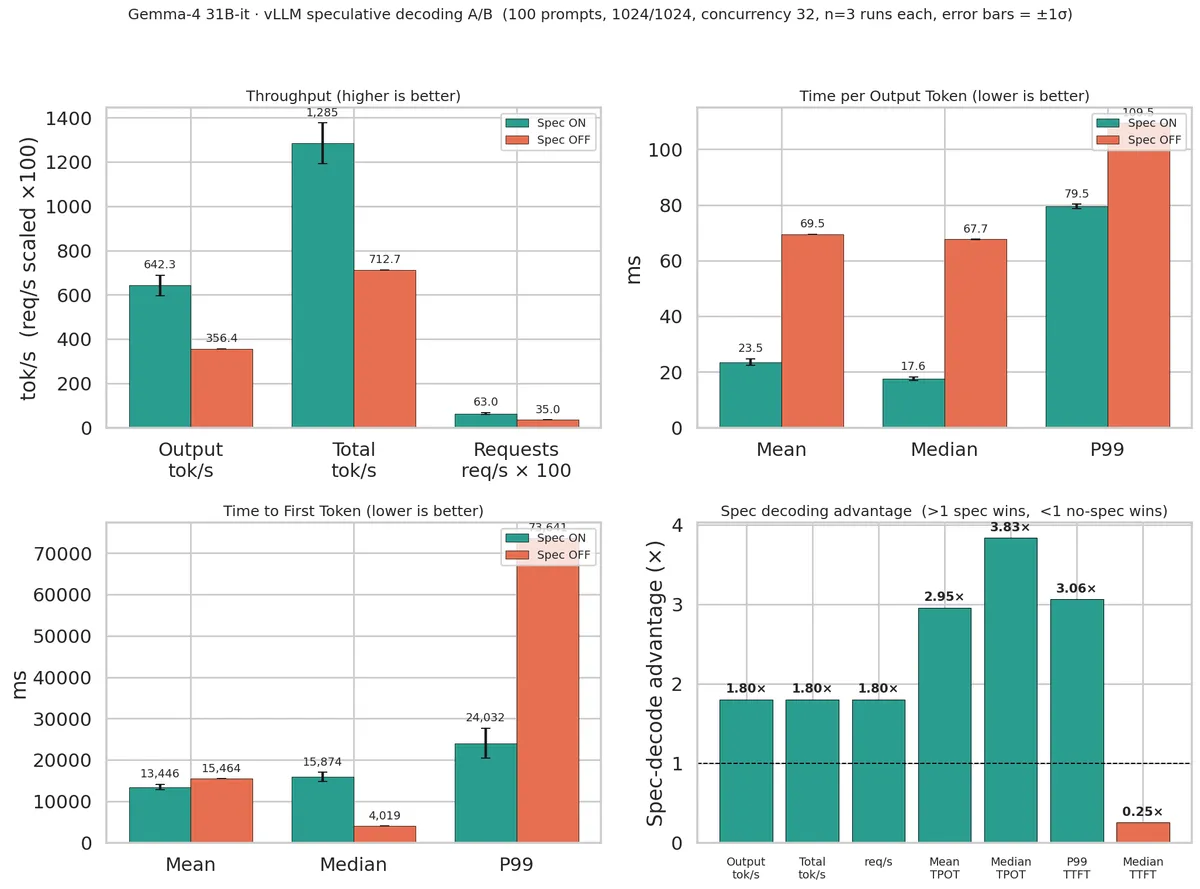
- استفاده از کوانتایزیشن (Quantization) NVFP4 — تشبیه روزمره: مثل فشرده کردن یک لباس حجیم در ساک سفر بدون اینکه شکل کلیاش خراب شود — برای کاهش حجم مدل به حدود ۱۹ گیگابایت.
- افزایش سرعت استنتاج (Inference) — تشبیه روزمره: لحظهای که مدل واقعاً جواب تولید میکند — مثل خودِ آشپزی، نه دورهی آموزش آشپز — تا ۲.۴ برابر در متون کوتاه.
- پشتیبانی از پنجرههای متنی تا ۱۲۸ هزار توکن، هرچند سرعت در متون بسیار طولانی کاهش مییابد.
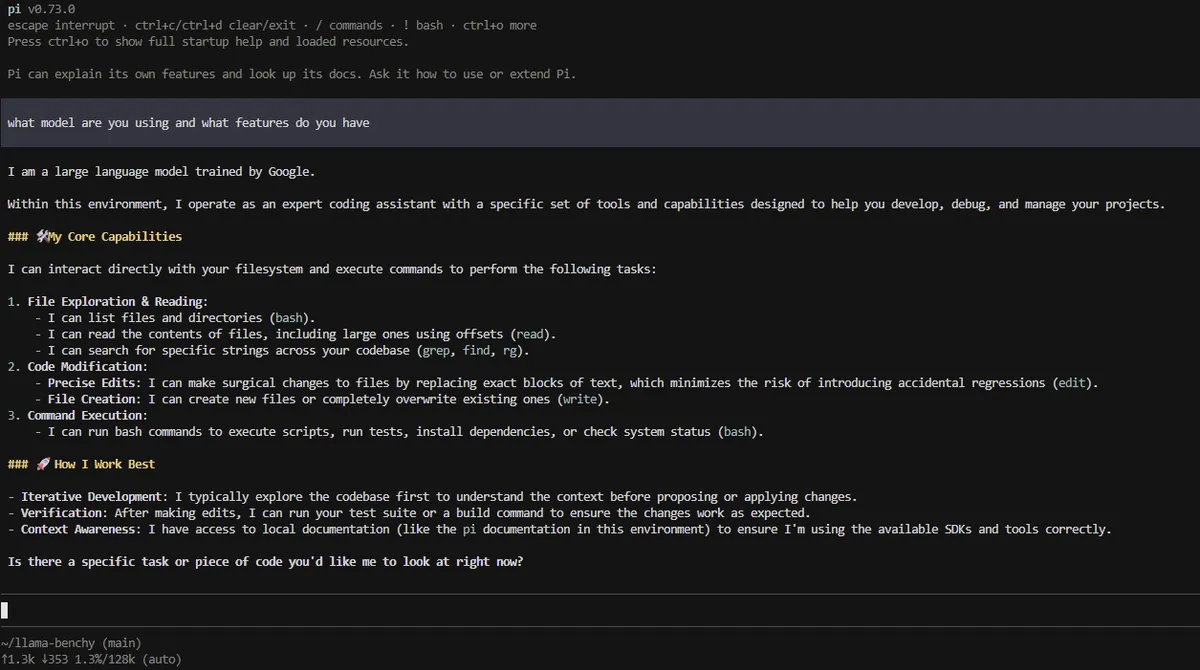
این ساختار باعث میشود «مغز» (موتور استنتاج) از «خلبان» (لایه سازماندهنده مثل عامل Pi) جدا شود. نتیجه این است که یک عامل (Agent) میتواند تمام شب را صرف خواندن صدها صفحه مستندات کند، چرا که هزینه شکست، تنها کمی برق مصرفی است، نه اعتبار دلاری API.
این گذار به معنای دستیابی به «حاکمیت محاسباتی» برای توسعهدهندگان است؛ جایی که پایداری سیستم محلی بر برتری جزئیِ هوشِ مدلهای ابری غلبه میکند. اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.
گام بعدی شما
- اگر از GPUهای سری ۴۰ یا ۵۰ انویدیا استفاده میکنید، ترکیب vLLM و Gemma 4 31B را برای اتوماسیونهای طولانیمدت تست کنید.
- پیش از استقرار، میانگین عمق متن (Context Depth) خود را بسنجید؛ MTP برای متون زیر ۵۰ هزار توکن فوقالعاده است اما در متون بسیار حجیم، روشهای سنتی پایدارترند.
- برای کاهش مصرف حافظه، حتماً از نسخههای کوانتایز شده NVFP4 استفاده کنید.



گفتگو