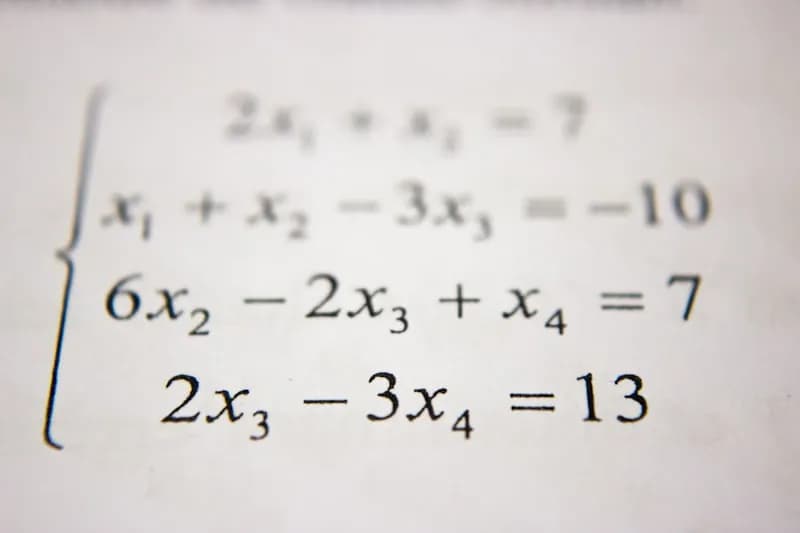
تصور کنید باید هزاران نقطه داده را بدون داشتن هیچ نقشهای گروهبندی کنید؛ این دقیقاً سختترین چالش در یادگیری بدون نظارت است. در ۲ ژوئیه ۲۰۲۶، پلتفرم PixelBank توضیح داد که چگونه خوشهبندی سلسلهمراتبی (Hierarchical Clustering) با ساخت یک سلسلهمراتب تودرتو از خوشهها، روابط پنهان دادهها را آشکار میکند. این الگوریتم، به عنوان نوعی از الگوریتمهای یادگیری ماشین بدون نظارت، اشیاء مشابه را بر اساس ویژگیهایشان در خوشههایی گروهبندی میکند. این فرآیند برای شناسایی الگوها و روابط در مجموعههای داده، بدون داشتن دانش قبلی از برچسبهای کلاسها، ضروری و حیاتی است.
بسیاری از ابزارهای خوشهبندی از شما میخواهند تعداد گروهها یا خوشهها را از پیش حدس بزنید، که این موضوع اغلب منجر به نتایج منحرف شده و نادرست میشود. خوشهبندی سلسلهمراتبی این حدسوگمان را کاملاً حذف میکند. این روش بهویژه زمانی بسیار مؤثر است که تعداد خوشهها نامعلوم باشد یا زمانی که خوشهها دارای تراکمهای متفاوتی باشند. هدف اصلی در اینجا، ساخت یک سلسلهمراتب از خوشهها است که یا از طریق ادغام خوشههای کوچکتر در خوشههای بزرگتر و یا از طریق تقسیم خوشههای بزرگتر به خوشههای کوچکتر به دست میآید.
شجرهنامهای را تصور کنید، اما برای نقاط داده. بهجای اینکه هر مورد را به زور در یکی از ۵ دستهبندی یا سطل قرار دهیم، این روش نشان میدهد که چگونه یک گروه کوچک از موارد مشابه، ابتدا با هم ترکیب شده و سپس به یک گروه بزرگتر میپیوندند و این روند تا رسیدن به مجموعههای وسیعتر ادامه مییابد. این نمایش بصری به تحلیلگران اجازه میدهد تا «تکامل» شباهت دادهها را مشاهده کنند. این قابلیت بهویژه در تحلیل داده (Data Analysis) و کاوکاو داده (Data Mining) مفید است، جایی که هدف اصلی، استخراج بینشها و الگوها از مجموعههای داده بزرگ و پیچیده است.
سازوکارهای گروهبندی
طبق راهنمای PixelBank، این فرآیند بر دو ستون فنی بسیار حیاتی استوار است:
- معیارهای فاصله (Distance Metrics): این معیارها شباهت بین دو شیء را اندازهگیری میکنند. رایجترین آنها فاصله اقلیدسی (Euclidean Distance) و شباهت کسینوسی (Cosine Similarity) هستند. شباهت کسینوسی به صورت فرمول $sim(a, b) = (a \cdot b / |a| |b|)$ تعریف میشود که در آن $a$ و $b$ دو بردار و $|a|$ و $|b|$ اندازه یا بزرگی آنها هستند. این روش به دلیل تمرکز بر زاویه بین بردارها بهجای اندازه آنها، استاندارد طلایی برای تحلیل متن (Text Analysis) و تحلیل تصویر (Image Analysis) محسوب میشود.
- معیارهای پیوند (Linkage Criteria): این معیارها تعیین میکنند که خوشهها چگونه ادغام یا تقسیم شوند. انتخاب معیار پیوند به کاربرد خاص و ویژگیهای دادهها بستگی دارد. رایجترین معیارهای مورد استفاده عبارتند از:
- پیوند تکگانه (Single Linkage)
- پیوند کامل (Complete Linkage)
- پیوند میانگین (Average Linkage)
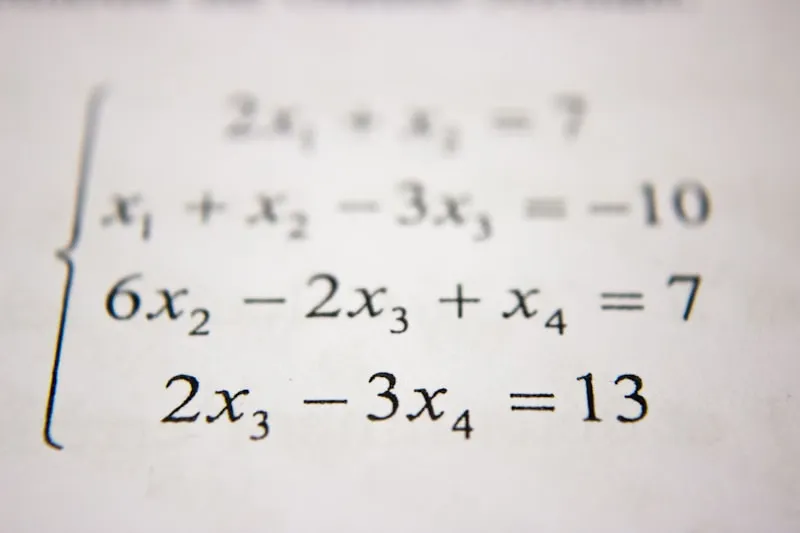
پیادهسازی در دنیای واقعی
این تکنیک صرفاً یک موضوع تئوری نیست، بلکه موتور محرک چندین کاربرد صنعتی با ریسک و اهمیت بالا است:
- بخشبندی مشتریان (Customer Segmentation): کسبوکارها مشتریان خود را بر اساس ویژگیهای دموگرافیک و رفتاری گروهبندی میکنند. این کار به شرکتها اجازه میدهد تا استراتژیهای بازاریابی خود را برای بخشهای خاصی از مشتریان سفارشیسازی کرده و تجربه کلی مشتری را بهبود بخشند.
- تحلیل بیان ژن (Gene Expression Analysis): پژوهشگران از خوشهبندی سلسلهمراتبی برای شناسایی گروههایی از ژنها استفاده میکنند که در نمونههای مختلف بهطور همزمان بیان (co-expressed) میشوند. این امر به درک فرآیندهای بیولوژیکی زمینهای و شناسایی نشانگرهای زیستی (biomarkers) بالقوه برای بیماریها کمک میکند.
- قطعهبندی تصویر (Image Segmentation): این الگوریتم تصاویر را به مناطقی با بافت و رنگ مشابه تقسیم میکند. این مرحله یک پیشنیاز ضروری برای برنامههای تشخیص اشیا (Object Detection) و درک صحنه (Scene Understanding) است.
علاوه بر تحلیل نهایی، این روش به عنوان یک گام پیشپردازش برای سایر الگوریتمها مانند طبقهبندی (Classification) و رگرسیون (Regression) عمل میکند. در واقع بهینهسازی این مراحل پیشپردازش میتواند مشابه رویکرد بهینهسازی مشترک در تولید دادههای جدولی، سرعت و دقت استخراج الگوهای پیچیده را بهطور چشمگیری افزایش دهد. مهندسان میتوانند با خوشهبندی اولیه دادهها، ابعاد فضای ویژگی را کاهش داده و در نتیجه عملکرد الگوریتمهای بعدی را بهطور قابل توجهی تقویت کنند.
شناسایی ناهنجاریها
یکی از کاربردیترین استفادههای این سلسلهمراتب، تشخیص ناهنجاری (Anomaly Detection) است. چون الگوریتم تمام روابط را ترسیم میکند، دادههای پرت (Outliers) به عنوان شاخههای تکافتادهای ظاهر میشوند که تا آخرین مراحل فرآیند، از ادغام با خوشههای بزرگتر سرباز میزنند. این ویژگی، آن را به ابزاری قدرتمند برای کاربردهایی نظیر شناسایی کلاهبرداری (Fraud Detection) تبدیل میکند.
در یک محیط تشخیص کلاهبرداری، تراکنشی که در هیچ «خوشه رفتاری» تثبیتشدهای جای نمیگیرد، بلافاصله در سلسلهمراتب بصری متمایز شده و سیگنالی از یک رخنه امنیتی بالقوه ارسال میکند. با شناسایی این دادههای پرت، متخصصان میتوانند ناهنجاریهایی را ایزوله کنند که احتمالاً توسط الگوریتمهایی که دادهها را به زور در گروههایی با اندازه پیشفرض قرار میدهند، نادیده گرفته میشدند.
ارزیابی کیفیت خوشهها
برای اطمینان از اینکه گروههای ایجاد شده معنادار هستند، متخصصان از معیارهای ارزیابی خاصی برای سنجش کیفیت خوشه استفاده میکنند. این معیارها برای تعیین تعداد بهینه خوشهها و کیفیت کلی الگوریتم خوشهبندی ضروری هستند.
- ضریب سیلوئت (The Silhouette Coefficient): این یک ابزار ارزیابی اولیه است. این ضریب به صورت $sil(i) = (b(i) - a(i)) / \max(a(i), b(i))$ محاسبه میشود. در این فرمول، $a(i)$ میانگین فاصله بین نقطه $i$-ام و تمام نقاط دیگر در همان خوشه است و $b(i)$ میانگین فاصله بین نقطه $i$-ام و تمام نقاط در نزدیکترین خوشه بعدی است.
- شاخص کالینسکی-هاراباز (Calinski-Harabasz Index): این شاخص معیار کلیدی دیگری است که برای کمک به تعیین نقطه بهینه «برش» سلسلهمراتب جهت تصمیمگیری درباره تعداد نهایی خوشهها به کار میرود.
مسئله طولانیترین زیرتوالی مشترک (LCS)
به موازات خوشهبندی، PixelBank مسئله طولانیترین زیرتوالی مشترک (Longest Common Subsequence) را به عنوان یکی از سنگبناهای برنامهنویسی پویا (Dynamic Programming) برجسته میکند. این مسئله با درجه سختی متوسط که در مجموعه مشهور «Blind 75» قرار دارد، شامل دو رشته متنی است که هدف، یافتن طول بلندترین زیرتوالی مشترک بین آنهاست. یک زیرتوالی، ترتیب نسبی نویسهها را حفظ میکند اما لزومی ندارد که نویسهها حتماً پشتسرهم یا متوالی (contiguous) باشند.
این منطق ریاضی، قدرتبخش چندین کاربرد واقعی است:
- سکانسبندی ژن (Gene Sequencing): LCS برای مقایسه توالیهای DNA موجودات مختلف جهت شناسایی الگوهای مشترک استفاده میشود.
- ویرایش متن (Text Editing): این الگوریتم به ابزارها اجازه میدهد تا نسخههای مختلف یک سند را مقایسه کرده و تغییرات خاص اعمال شده را شناسایی کنند.
- مقایسه دادهها (Data Comparison): این روش به عنوان یک ابزار بنیادی برای مقایسه رشتههای داده ساختاریافته عمل میکند.
برای حل مسئله LCS، فرد باید درک کند که یک زیرتوالی از طریق حذف برخی المانها بدون تغییر ترتیب المانهای باقیمانده به دست میآید. راه حل این مسئله شامل برنامهنویسی پویا است؛ یعنی شکستن مسائل پیچیده به زیرمسئلههای کوچکتر و حل هر یک از آنها تنها یک بار.
جزئیات پیادهسازی LCS
برای پیادهسازی یک راه حل بهینه، از یک آرایه دوبعدی یا ماتریس برای ذخیره طولهای زیرتوالیهای مشترک استفاده میشود:
- ابعاد ماتریس: اندازه ماتریس $(m+1) \times (n+1)$ است، که در آن $m$ و $n$ طول دو رشته ورودی هستند. سطر و ستون اضافی برای مدیریت حالتهای مرزی (edge cases) که در آن یکی از رشتهها تهی است، در نظر گرفته شدهاند.
- فرآیند: ماتریس با مقایسه نویسههای دو رشته، با شروع از حالتهای پایه، پر میشود.
- رابطه بازگشتی (Recurrence Relation): کلید حل مسئله، رابطه بازگشتی است که نحوه پر کردن هر سلول را بر اساس مقادیر سلولهای قبلی توصیف میکند. طول به این صورت تعریف میشود: $LCS(i, j) = \text{length of the longest common subsequence of the first } i \text{ characters of string 1 and the first } j \text{ characters of string 2}$.
مقیاسپذیری با مطالعههای موردی
برای پر کردن شکاف بین این الگوریتمها و محیط تولید (Production)، PixelBank یک بخش «Spotlight ویژگی» را روی مطالعههای موردی یادگیری ماشین (ML Case Studies) ارائه میدهد. این بخشها بینشهای طراحی سیستم در دنیای واقعی را از رهبران صنعت مانند Stripe، Netflix، Uber و Google فراهم میکنند. این قابلیت بهطور خاص برای دانشجویان، مهندسان و پژوهشگران طراحی شده تا نگاهی نادر به استراتژیهای مورد استفاده در شرکتهای برتر بیندازند.
با مطالعه این موارد، کاربران میتوانند بیاموزند که چگونه بر چالشهای رایج یادگیری ماشین غلبه کنند، از جمله:
- پیشپردازش دادهها: نحوه پاکسازی و آمادهسازی مجموعههای عظیم داده برای آموزش مدل.
- انتخاب مدل (Model Selection): انتخاب معماری مناسب برای یک مسئله خاص.
- تنظیم ابرپارامترها (Hyperparameter Tuning): بهینهسازی عملکرد مدل از طریق تنظیمات سیستماتیک.
به عنوان مثال، یک دانشمند داده میتواند تحلیل کند که چگونه نتفلیکس توصیه محتوای شخصیسازی شده را مدیریت میکند تا تکنیکهای جدیدی برای ادغام دادهها (Data Integration)، آموزش مدل و استقرار مدل (Model Deployment) کشف کند. به همین ترتیب، مطالعه سیستم پیشبینی تقاضای مبتنی بر ML در اوبر، نقشهای برای مدلسازی پیشبین در محیطهای با مقیاس بالا ارائه میدهد.
یکپارچگی و بینش
این رویکرد نشان میدهد که تسلط بر ریاضیات زیربنایی خوشهبندی و برنامهنویسی پویا، تنها راه پیادهسازی سیستمهای سطح بالایی است که رهبران صنعت از آنها استفاده میکنند. همانطور که گفته میشود: دانش = بینش $\times$ تجربه. با ترکیب عمق فنی خوشهبندی و تجربات موجود در مطالعههای موردی صنعتی، متخصصان میتوانند کشفیات جدیدی را در مجموعههای داده خود باز کنند.
در حالی که K-Means و DBSCAN جایگزینهای محبوبی هستند که در فصل گستردهتر خوشهبندی پوشش داده شدهاند، رویکرد سلسلهمراتبی همچنان بهترین راه برای درک روابط ساختاری درون یک مجموعه داده، پیش از اعمال مدلهای سختگیرانه است. اگر شما یک خط لوله (Pipeline) یادگیری ماشین در مقیاس تولید مدیریت میکنید، باید ارزیابی کنید که آیا روش خوشهبندی فعلی شما، فرصتهای شناسایی دادههای پرت را که یک نقشه سلسلهمراتبی میتوانست آشکار کند، از دست میدهد یا خیر.
گام بعدی شما
- دادههای خود را با ضریب سیلوئت ارزیابی کنید تا تعداد بهینه خوشهها را بدون حدس زدن بیابید.
- در پروژههای تشخیص کلاهبرداری، به جای مدلهای دستهبندی سخت، از شاخههای تکافتاده در خوشهبندی سلسلهمراتبی برای شناسایی ناهنجاریها استفاده کنید.
- برای بهینهسازی مقایسه رشتههای داده در دیتابیس، الگوریتم LCS را جایگزین مقایسههای ساده متنی کنید.
اما داستان سختافزاری این تحولات حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.



گفتگو