دوران تکیه بر مجموعههای دادههای عظیم و نویزی رو به پایان است و جای خود را به دادههای هدفمند میدهد. طبق اعلام متا در مقالهای که در ۲۴ ژوئن ۲۰۲۶ منتشر شد، چارچوب Autodata نحوه تولید «درسهای آموزشی» توسط مدلها را بهطور بنیادین تغییر میدهد.
سالهاست صنعت بر افزایش پارامترها و خوشههای GPU تمرکز کرده و به دادهها صرفاً بهعنوان پیشنیازی برای استخراج و فیلتر کردن نگاه میکرد. این چرخش راهبردی، یادآور ادغام عمیقتر هوش مصنوعی در سختافزار است؛ همانطور که در پوشش پیشین ما از عینکهای هوشمند متا (Meta Smart Glasses) دیدیم، این شرکت چگونه قابلیتهای تخصصی روی دستگاه را برای مدلهای درآمدی خود به بهرهبرداری رساند.
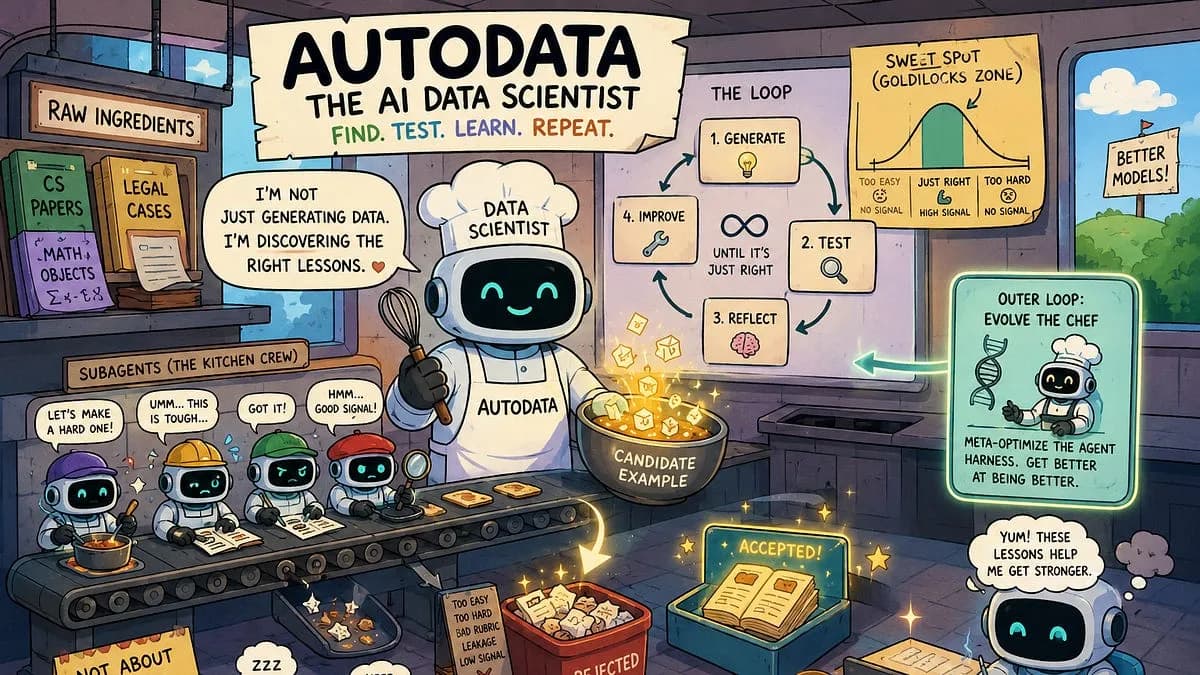
Autodata به جای استفاده از پرامپتهای تکمرحلهای (One-shot) برای تولید دادههای مصنوعی، از یک حلقهٔ پژوهشی کوچک استفاده میکند. بر اساس مستندات این پروژه، سازوکار این سیستم به شرح زیر است:
- تولید عاملمحور: یک عامل (Agent) مجموعهای از نمونههای آموزشی را خلق میکند.
- آزمون و اعتبارسنجی: سیستم این نمونهها را میسنجد تا نقاط شکست را شناسایی کند.
- بهروزرسانی دستورالعمل: عامل تحلیل میکند که چرا برخی نمونهها شکست خوردند و استراتژی تولید را اصلاح میکند.
- بهبود تکرارشونده: این حلقه تا زمانی تکرار میشود که توزیع دادهها برای مدل هدف واقعاً مفید باشد.

به نقل از پژوهشگران متا، این رویکرد با انتقال «هوشِ» سازماندهی دادهها از مهندس انسان به خودِ مدل، مفروضات این حوزه را دگرگون میکند. در واقع، با تبدیل تولید داده به یک آزمایش خود-اصلاحگر، وابستگی به دادههای حجیم و کاهش نویز، جای خود را به نمونههای مصنوعی با سیگنال بالا و تأییدشده توسط عامل میدهد. این رویکرد تکاملی در تولید داده، شباهتهای ساختاری با متدهای نوین استدلالی دارد؛ بهگونهای که مدل انتشار iLLaDA نیز با رویکردی متفاوت در استدلال پایه توانست با مدلهای مطرحی چون Qwen2.5 برابری کند.
این تغییر در معماری آموزش، بهویژه برای نسلهای آینده مدلهای Llama، بهرهوری را به شدت افزایش میدهد. اما نقطه عطف واقعی زمانی رخ میدهد که این حلقه بتواند بهطور خودکار مسیرهای استدلالی پیچیدهای را کشف کند که هنوز توسط انسانها برچسبگذاری نشدهاند.
گام بعدی شما
- بررسی مقالات فنی متا درباره تعامل بین Autodata و مدلهای استدلالی.
- رصد تأثیر این چارچوب بر کاهش نرخ توهم در نسخههای بعدی Llama.
- تحلیل امکان پیادهسازی حلقههای بازخورد مشابه برای دادههای تخصصی در محیطهای بسته.
این تحول در دادهها تنها نیمی از ماجراست؛ اثر این رویکرد بر قوانین مقیاسپذیری در سختافزارهای نسل جدید را در گزارش بعدی بررسی خواهیم کرد.



گفتگو