
اگر برای آموزش مدلهای پیشبینی توالی زمان زیادی صرف میکنید، احتمالاً مشکل شما معماری مدل نیست، بلکه تنظیم نادرست نرخ یادگیری است. در ۲ ژوئیه ۲۰۲۶، یک تحلیل فنی نشان داد که با تغییر نرخ یادگیری از ۰.۰۰۱ به ۰.۱، یک مدل LSTM سادهشده میتواند با سرعت بسیار بیشتری به وزنها و بایاسهای هدف برسد.
برای توسعهدهندگان، مدلهای حافظه کوتاهمدت بلندمدت (LSTM) — شبیه به کسی است که یاد میگیرد کدام تکههای یک داستان طولانی را به خاطر بسپارد و کدام را فراموش کند — به دلیل مکانیزمهای داخلی گیتینگ، اغلب مانند یک «جعبه سیاه» مبهم به نظر میرسند. برای سادهسازی این موضوع، در این پیادهسازی از nn.LSTM() در PyTorch و ابزار Lightning AI استفاده شده تا کدهای تکراری حذف شوند و مدل تنها به عنوان مؤلفهای عمل کند که توالیها را پردازش کرده و به یک پیشبینی واحد تبدیل میکند.
زمینه و پیادهسازی
بر اساس مستندات آموزشی dev.to، هسته این پیادهسازی بر یک متد سفارشی forward() متکی است. فرآیند با تغییر شکل ورودی از طریق input.view(len(input), 1) آغاز میشود. این عملیات تضمین میکند که برای هر نقطه داده، دقیقاً یک ردیف و یک ستون وجود داشته باشد؛ چرا که هر نقطه داده در این مدل تنها شامل یک ویژگی (Feature) است.
همانطور که در تحلیلهای مربوط به بهینهسازی مدلهای بازمتن اشاره شد، مدیریت جریان دادهها در لایههای پنهان حیاتی است. در اینجا ورودی تغییر شکلیافته به LSTM ارسال شده و خروجی در متغیر lstm_out ذخیره میشود. این متغیر حاوی مقادیر حافظه کوتاهمدتی است که توسط هر واحد در حین پردازش توالی تولید میشود. در مثال ارائه شده، توالی شامل چهار مقدار ورودی است؛ بنابراین LSTM چهار بار باز (unroll) شده و lstm_out چهار خروجی را در خود نگه میدارد. درک این ساختارهای توالی، اساس بسیاری از مدلهای پیچیدهتر است؛ برای مثال، مکانیسم توجه در مدلهای زبانی جدیدتر به گونهای طراحی شده تا نقاط کلیدی توالیها را با دقت بیشتری از مدلهای سنتی رصد کند.
مدل سپس برای تولید پیشبینی، تنها خروجی نهایی توالی را استخراج میکند. این کار با انتخاب آخرین المان با استفاده از شاخص ۱- انجام میشود.
جزئیات فنی
طبق گزارش فنی این پروژه، مشخصات کلیدی خط لوله آموزش عبارت است از:
- بهینهساز (Optimizer): متد
configure_optimizers()بهینهساز Adam را برای مدیریت پارامترها پیاده میکند. این بهینهساز مانند یک ناظر عمل میکند که مسیر حرکت مدل را برای رسیدن به کمترین خطا اصلاح میکند. - نرخ یادگیری (Learning Rate): این نرخ برای مشاهده نحوه همگرایی بهینهساز به وزنهای بهینه، از مقدار پیشفرض ۰.۰۰۱ به ۰.۱ افزایش یافت.
- گام آموزش (Training Step): متد
training_step()میزان زیان (Loss) را با استفاده از فرمول(output_i - label_i)**2محاسبه کرده و پیشرفت مدل را ثبت (Log) میکند. - اپوکها (Epochs): ۳۰۰ چرخه آموزشی از طریق دستور
L.Trainer(max_epochs=300)اجرا گردید. این رویکرد در مقیاسهای بزرگتر با چالشهای متفاوتی روبروست، همانطور که در مقایسهی استراتژیهای آموزش مدلهای زبانی بر سختافزارهای ناهمگن مشاهده میشود. - ثبت وقایع (Logging): مقدار
log_every_n_stepsروی ۲ تنظیم شد. این تنظیم ضروری است زیرا مقدار پیشفرض ۵۰ گام برای یک اجرای آموزشی کوچک بسیار دیر اتفاق میافتد و دادههای کافی ارائه نمیدهد. رصد پیشرفت در تمام این مراحل از طریق TensorBoard انجام شد.

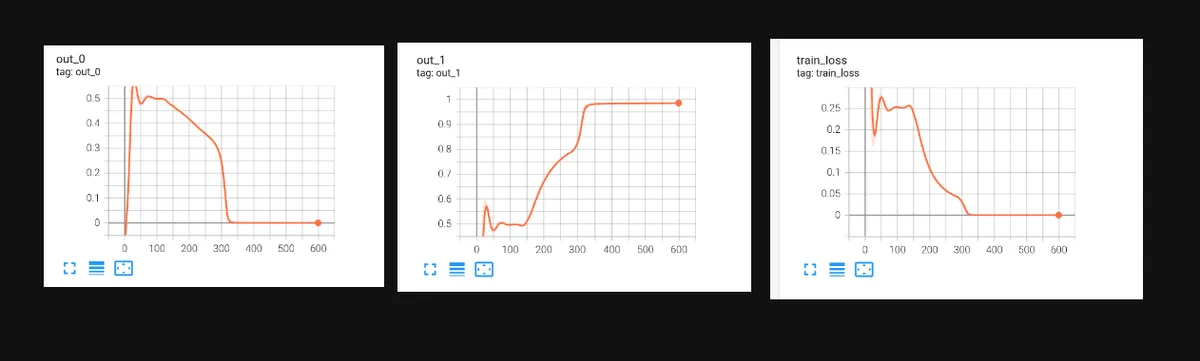
در مرحله آزمایش، مدل پیش از شروع آموزش اجرا شد تا پیشبینیهای اولیه بررسی شوند. برای شرکت A (که مقدار مشاهدهشده آن ۰ بود)، مدل مقدار ۰.۰۱۳۱ را پیشبینی کرد. برای شرکت B (که مقدار مشاهدهشده آن ۱ بود)، مدل مقدار ۰.۰۱۰۲ را پیشبینی نمود. این نتایج که تقریباً یکسان هستند، نشان میدهند که مدل از یک وضعیت آموزشندیده و تصادفی شروع کرده است.
اما پس از ۳۰۰ اپوک اجرای متد trainer.fit()، نتایج بهشدت تغییر کرد. پیشبینی برای شرکت A به ۰.۰۰۰۱ کاهش یافت و پیشبینی برای شرکت B به ۰.۹۸۵۷ رسید. این نتایج تقریباً با اهداف باینری ۰ و ۱ تطبیق کامل داشتند. تحلیل نتایج در TensorBoard آشکار کرد که با همگرایی مدل به سمت پیشبینیهای مطلوب، نمودارهای زیان مسطح شدهاند.
این تغییر ثابت میکند که برای وظایف توالی در مقیاس کوچک، نرخ یادگیری پیشفرض ۰.۰۰۱ اغلب بیش از حد محافظهکارانه است. با افزایش تهاجمی این نرخ به ۰.۱، مدل از گیر افتادن در نقاط بهینه محلی جلوگیری کرده و منحنی زیان را مؤثرتر مسطح میکند. این بهینهسازیهای ساختاری یادآوری میکند که چرا حتی در مدلهای پیشرفتهتر، تنظیمات دقیق ساختاری میتواند بازدهی ارزیابیها را تا چندین برابر تغییر دهد.
برای متخصصان، این به معنای آن است که ابرپارامترهای «استاندارد» ارائه شده توسط کتابخانهها صرفاً نقاط شروع هستند. تغییرات کوچک معماری، مانند انتخاب وضعیت پنهان نهایی یک LSTM و یکپارچهسازی متدهای __init__() ، forward() ، configure_optimizers() و training_step()، میتواند تفاوت بین یک مدل ایستاده و مدلی باشد که نتایج را بهدقت پیشبینی میکند.
گام بعدی شما
- نرخ یادگیری مدلهای فعلی خود را در مقیاسهای مختلف (مثلاً ۱۰ برابر افزایش) آزمایش کنید تا نقطه شکست و همگرایی را بیابید.
- مستندات Lightning AI را برای حذف کدهای تکراری (Boilerplate) در پروژههای PyTorch مطالعه کنید.
- برای مدیریت بهتر دادههای توالی، استفاده از TensorBoard را برای رصد لحظهای نرخ زیان به جریان کاری خود اضافه کنید.
اکنون که پایه LSTM تکمیل شده، گام منطقی بعدی انتقال از توالیهای عددی به متن است. پیشنهاد میکنیم نحوه پیادهسازی بردار معنایی (Word Embeddings) در PyTorch و Lightning AI را برای مدیریت وظایف پردازش زبان طبیعی (NLP) بررسی کنید.



گفتگو