
مدیران داده در سازمانها امروز با یک انتخاب دشوار و بیپرده روبرو هستند: یا با توهمات مدلهای زبانی بزرگ (LLM) که در محیطهای بدون مبنیسازی (Ungrounded) رخ میدهد کنار بیایند، یا ریسک نشت دادههای حساس و محرمانه شرکت به APIهای خارجی را بپذیرند. در ۵ ژوئیه ۲۰۲۶، Snowflake یک نقشه راه جامع برای عبور از این بنبست ارائه کرد تا مدلهای زبانی بزرگ را مستقیماً به داخل محیط امن دادههای سازمانی منتقل کند. این استراتژی اجازه میدهد تا مدلها بدون خروج داده از محیط امن، روی دادههای واقعی سازمان آموزش ببینند یا از آنها استفاده کنند. این رویکردی است که سازمانها برای حفظ حریم خصوصی به آن نیاز دارند و در همین راستا میتوان به ابزارهای متنباز برای استقرار محلی و خصوصی مدلهای هوش مصنوعی اشاره کرد که امنیت دادهها را در محیطهای داخلی تضمین میکنند.
این تغییر بنیادین، یک انبار دادهٔ غیرفعال را به یک «سامانهٔ هوشمند» (System of Intelligence) تبدیل میکند؛ محیطی که در آن رهبران غیرفنی سازمان میتوانند بدون نوشتن حتی یک خط کد SQL، پرسوجوهای پیچیده را روی شماهای دادهای اجرا کنند. اکثر تلاشهای سازمانی برای بهکارگیری هوش مصنوعی شکست میخورند، چون بر پایه پرامپتهای عمومی تکیه میکنند تا ساختار دیتابیس را «حدس» بزنند. در واقع، مدلهای عمومی بدون داشتن زمینه (Context)، نمیتوانند تفاوت بین یک ستون «سود» و یک ستون «درآمد» را در یک دیتابیس خاص درک کنند.
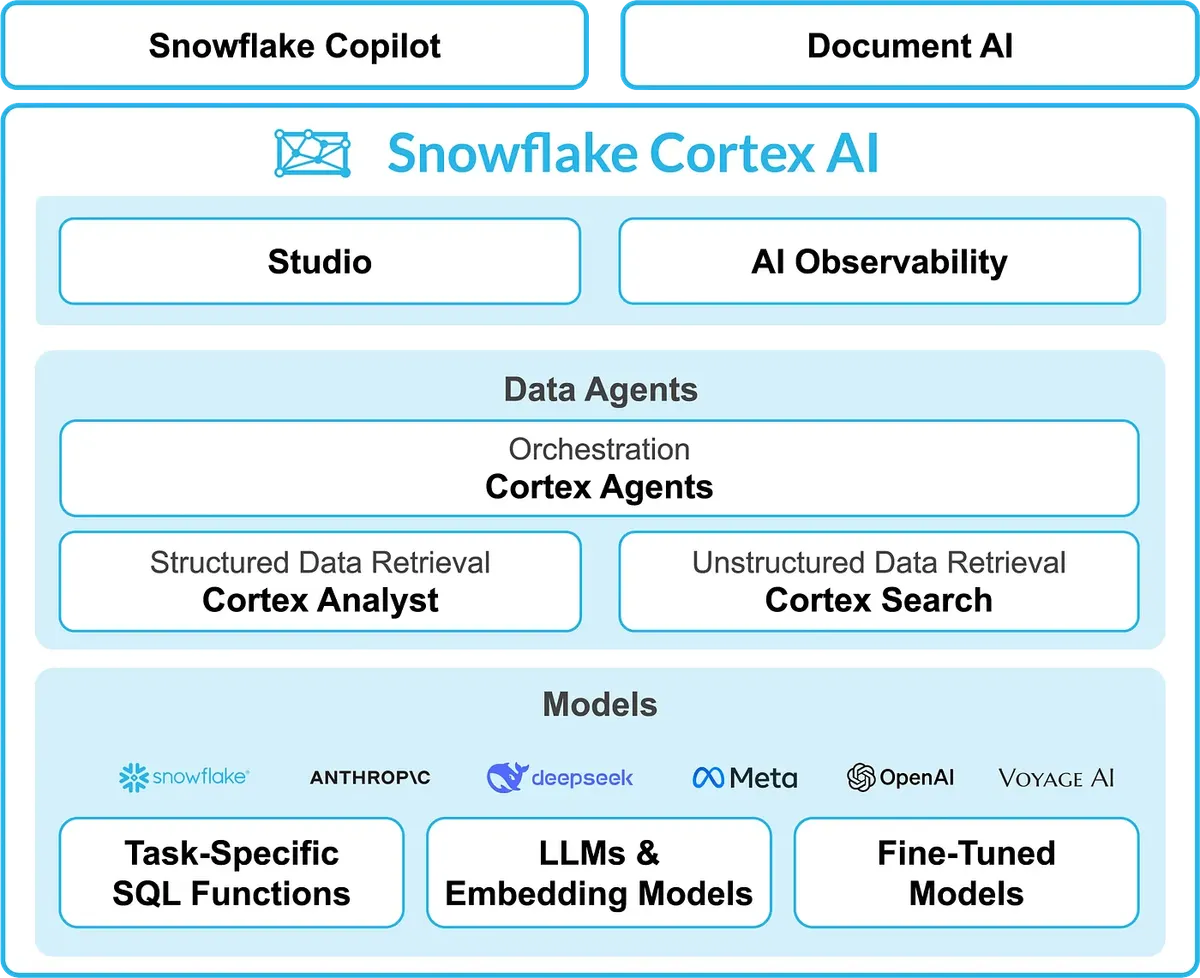
در مقابل، معماری Snowflake Cortex AI وظایف را بر اساس پیچیدگی تفکیک میکند. این ساختار ماژولار تضمین میکند که یک LLM عمومی به جای حدس زدن کورکورانه یک پرسوجو، توسط یک لایهٔ معنایی (Semantic Layer) سختگیرانه هدایت شود که دقیقاً تعریف میکند کسبوکار در واقعیت چگونه عمل میکند و هر مفهوم تجاری به کدام جدول یا ستون در دیتابیس متصل است.
ابزارهای مجموعهی Cortex AI
این اکوسیستم از چندین جزء تخصصی تشکیل شده است که برای انواع مختلف دادهها و نیازهای سازمانی طراحی شدهاند:
- Cortex Analyst: یک موتور تبدیل متن به SQL معنایی است که به عنوان هستهٔ تحلیلهای گفتگو-محور عمل میکند و به کاربران تجاری اجازه میدهد با استفاده از زبان طبیعی از دیتابیسهای ساختاریافته پرسوجو کنند.
- Cortex Agent: یک ارکستراتور برای برنامهریزی چندمرحلهای و اجرای کد است. این ابزار میتواند دستیارهای خودکاری بسازد که قادر به اجرای اسکریپتهای پایتون یا اتصال به برنامههای خارجی باشند تا پیچیدگیهای عملیاتی را مدیریت کنند.
- Document AI: ابزاری برای استخراج دادهها که توسط یادگیری ماشین چندوجهی (Multimodal) پشتیبانی میشود و بهطور خاص برای استخراج نقاط داده از اسناد غیرساختاریافته مانند PDFها و فاکتورها طراحی شده است تا دادههای متنی و بصری را به فرمت ساختاریافته تبدیل کند.
- Cortex Search: یک سرویس جستوجوی کاملاً مدیریتشده با ایندکسگذاری برداری داخلی است که جستوجوهای تقریبی (Fuzzy Search) و تولید بازیابیافزا (RAG) را در سراسر اسناد قادر میسازد و سرعت دسترسی به اطلاعات را افزایش میدهد.
- AI Studio & Observability: یک مرکز متمرکز برای ردیابی و ارزیابی مدلهای هوش مصنوعی است. این بخش عملکرد مدلها را مانیتور کرده، تأخیر در پاسخدهی (Latency) را بررسی میکند و معیارهای دقت را ثبت مینماید تا از کیفیت خروجیها اطمینان حاصل شود.
- Snowflake Copilot: یک دستیار مبتنی بر هوش مصنوعی است که در ورکشیتهای Snowflake تعبیه شده تا به توسعهدهندگان در نوشتن، اصلاح و توضیح پرسوجوهای SQL کمک کند و سرعت کدنویسی را بالا ببرد.
- AI and ML Functions: عملگرهای بدون سرور (Serverless) هستند که مستقیماً در ردیفهای استاندارد SQL قرار گرفتهاند تا وظایفی مانند ترجمه متن، تحلیل احساسات و پیشبینی (Forecasting) را بهصورت لحظهای خودکار کنند.
- Models: یک رجیستری امن از مدلهای بنیادی پیشرو با وزنهای باز (Open Weights) است که دسترسی به مدلهای زبانی پیشرفته را در محیط امنیتی Snowflake فراهم میکند تا کاربر نیازی به انتقال داده به خارج از محیط شرکت نداشته باشد.
مهندسی یک عامل مبنیسازیشده
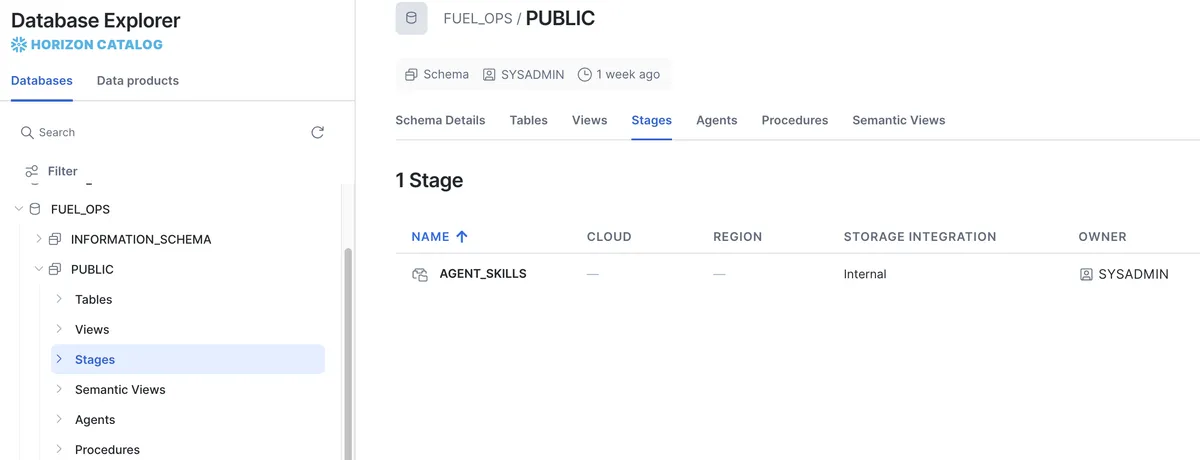
ساخت یک عامل (Agent) خودمختار نیازمند تغییر رویکرد از «تطبیق الگو» به یک «حلقهٔ استدلال» (Reasoning Loop) است. طبق راهنمای dev.to، این فرآیند با مقداردهی اولیه یک دایرکتوری داخلی (Internal Stage) مطابق با استانداردهای حاکمیتی، مانند @FUEL_OPS.PUBLIC.AGENT_SKILLS آغاز میشود تا تمامی پیکربندیهای معنایی و داراییهای مهارت (Skill Assets) در آن ذخیره شوند. این مرحله برای اطمینان از اینکه عامل به منابع درست دسترسی دارد، حیاتی است. در واقع تبدیل مهارتها به ساختارهایی کدگونه برای مقیاسپذیری ضروری است، مشابه آنچه در رویکرد iFLYTEK برای انتقال کنترل عاملهای AI به کدهای ماژولار مشاهده میکنیم.
این محیط با تعریف انبار پردازشی فعال (Active Compute Warehouse) و زمینههای نقش (Role Contexts) در یک ورکشیت تنظیم میگردد. این کار باعث میشود که هر عملیات توسط عامل، با مجوزهای درست و منابع پردازشی مناسب اجرا شود.
استقرار لایهٔ معنایی
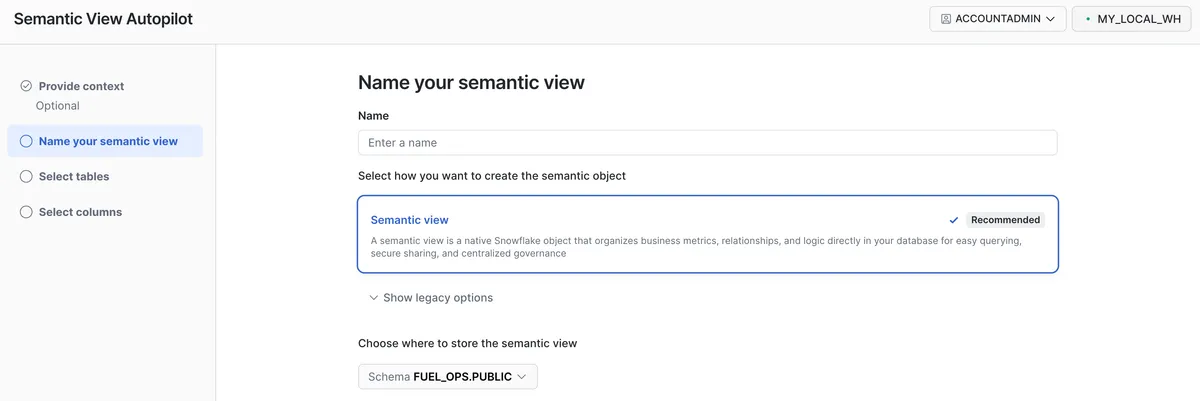
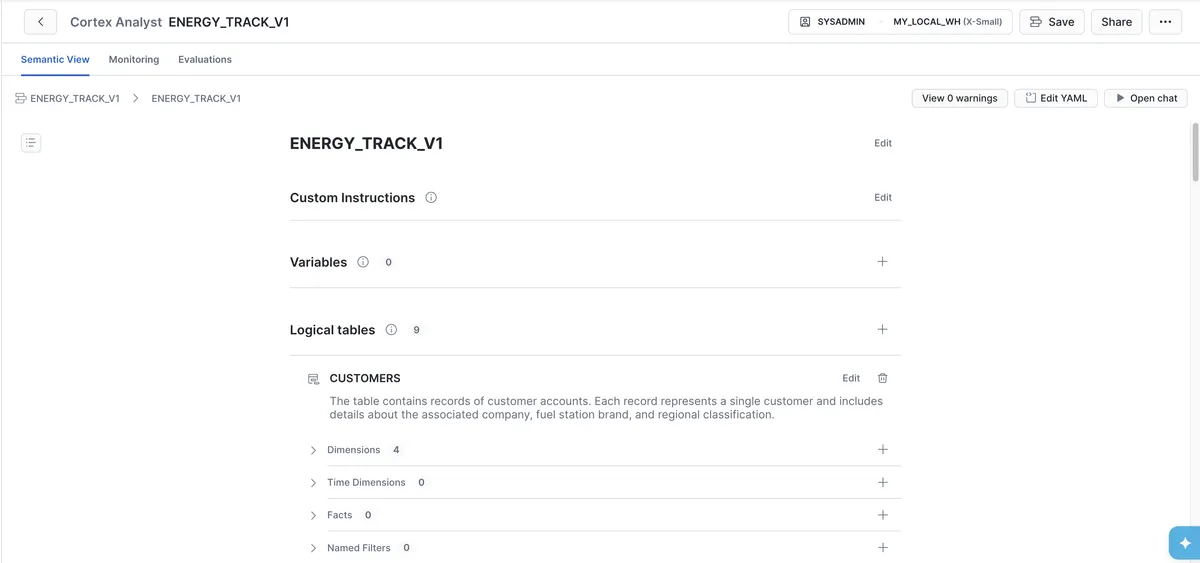
بحرانیترین مرحله، ایجاد مبنیسازی (Grounding) برای دادههای ساختاریافته است. توسعهدهندگان با استفاده از Cortex Analyst (که از طریق بخش AI & ML در کنسول Snowsight یا AI Studio قابل دسترسی است)، جداول فیزیکی را به ستونهای دقیق، مترادفهای سطح ستون (Column-level Synonyms) و روابط صریح دیتابیس مپ میکنند. این کار باعث میشود مدل بفهمد مثلاً عبارت «مشتریان فعال» در واقع به کدام ستون در جدول CUSTOMERS اشاره دارد.
برای تیزتر کردن دقت، اپراتورها میتوانند «پرسوجوهای تأییدشده» (Verified Queries) را به نمای معنایی اضافه کنند. این قابلیت به توسعهدهنده اجازه میدهد الگوهای SQL پیشتأییدشدهای را ارائه دهد که مدل بتواند به عنوان مرجع از آنها استفاده کند تا تضمین شود خروجی تولید شده کاملاً صحیح است و از خطاهای منطقی در تولید SQL جلوگیری شود.
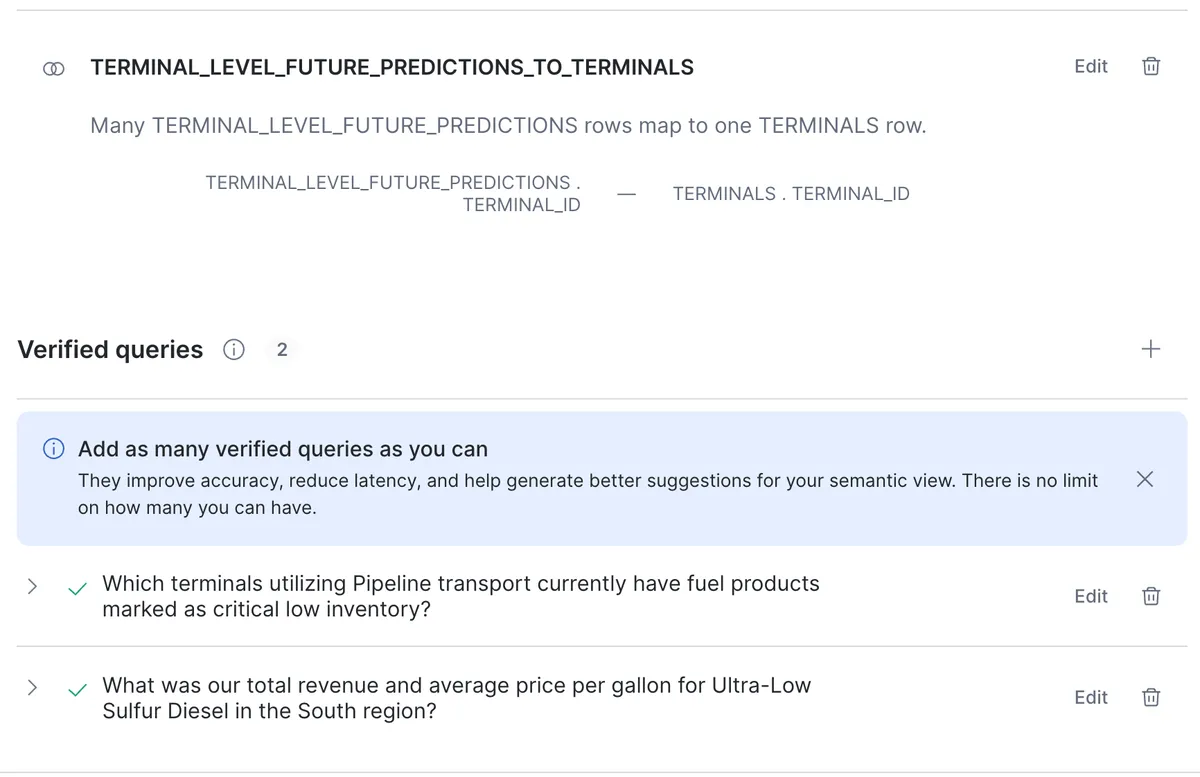
توسعهدهندگان میتوانند این پیکربندیها را از طریق یک فایل YAML در ویرایشگر مورد نظر خود مدیریت کنند. در این فایل، جداول، روابط بین آنها و پرسوجوهای تأییدشده با دقت تعریف میشوند. پس از آمادهسازی، توسعهدهنده پیکربندی را مستقیماً در نمای معنایی جایگذاری میکند. این تنظیمات از طریق بخش بالایی سمت راست رابط کاربری ذخیره شده و به عنوان منبع حقیقت برای عامل عمل میکنند.
راهاندازی و پیکربندی عامل
پس از تنظیم مبنیسازی، شیء Cortex Agent با پیمودن مسیر AI & ML --> Agents در Snowsight ایجاد میشود. توسعهدهندگان رشتههای شناسایی پایه شامل «نام شیء عامل» (Agent Object Name)، «نام نمایشی» (Display Name) و یک دامنه دیتابیس زمینه (context database scope) مانند FUEL_OPS را تخصیص میدهند تا هویت عامل در سیستم تعریف شود.
در پنل پیکربندگی، برای عامل یک شرح (Description) و پرامپتهای پایه تعریف میشود. این پرامپتها به کاربر نهایی کمک میکنند تا هنگام اولین تعامل با عامل در محیط CoWork، بداند عامل چه تواناییهایی دارد و چگونه گفتگوهای مرتبطی را آغاز کند.
در نهایت، عامل به مسیر معنایی .yaml که در مراحل قبلی در Stage ایجاد شده بود، متصل میشود. یک انبار مجازی (Virtual Warehouse) اختصاصی نیز برای مدیریت پردازشهای سنگین تبدیل متن به SQL در پشت صحنه تخصیص مییابد تا تداخلی با سایر عملیات دیتابیس ایجاد نشود.
گسترش قابلیتها
فراتر از پرسوجوهای ساده، کاربران میتوانند ابزارهای سفارشی را با منطقی شبیه به پروتکل زمینهٔ مدل (MCP) متصل کنند. این پروتکل اجازه میدهد تا مدلهای زبانی به ابزارهای خارجی یا توابع داخلی دسترسی داشته باشند. برای مثال، میتوان یک رویه ذخیرهشده (Stored Procedure) ایجاد کرد تا عامل قادر به ارسال اعلانهای ایمیلی باشد.
در سناریوی توزیع سوخت، رویهای مانند SEND_PUMP_FAILURE_EMAIL میتواند پیکربندی شود تا با استفاده از یک یکپارچهساز اعلان (my_email_int)، تیمهای تعمیر و نگهداری را در مورد خرابیهای بحرانی پمپ در پایانههای خاص با ارسال ایمیل هشدار دهد.
برای گسترش بیشتر منطق، توسعهدهندگان میتوانند از مهارتهای سفارشی (Custom Skills) استفاده کنند. این کار شامل آپلود یک اسکریپت اجرایی، مانند format_export.py به همراه یک لفاف Markdown آموزشی (SKILL.md) در یک دایرکتوری Stage است. این فایل Markdown به مدل توضیح میدهد که چه زمانی و چگونه از این اسکریپت استفاده کند. این قابلیت اجازه میدهد عامل پیش از بازگرداندن دادهها به کاربر، فرمتبندی تخصصی روی پاسخهای جدولی اعمال کرده و آنها را به شکل گزارشهای خوانا درآورد.
برای یکپارچهسازی خارجی، کانکتورهای MCP قابل برقراری هستند. Snowflake کانکتورهای MCP داخلی را ارائه میدهد و همچنین امکان افزودن کانکتورهای سفارشی از طریق منوی تنظیمات را فراهم کرده است. این امر به عامل اجازه میدهد از طریق یک پروفایل اتصال امن (CUSTOM MCP SERVER) به مخازن ابزار خارجی یا پلتفرمهای SaaS متصل شده و دادهها یا دستورات را بین آنها جابجا کند.
استقرار و حاکمیت
عاملها با کلیک بر روی دکمه Save/Publish در بوم Agent Studio نهایی میشوند. سپس از طریق داشبورد Snowflake CoWork یا پنل چت جانبی CoCo مستقر میگردند. کاربران میتوانند عامل خود را از یک منوی کشویی انتخاب کرده، پرامپتهای زبان طبیعی را ارسال کنند و از ابزار «Show Trace» برای حسابرسی (Audit) مسیر منطقی طی شده توسط عامل استفاده کنند تا بفهمند مدل چگونه به آن پاسخ خاص رسیده است.
مدیریت دسترسی از طریق کنترل دسترسی مبتنی بر نقش (RBAC) انجام میشود تا امنیت دادهها تضمین شود. برای نمونه، یک SECURITYADMIN میتواند دستورات زیر را برای اعطای امن مجوزها اجرا کند:
GRANT EXECUTE ON AGENT FUEL_OPS.PUBLIC.NEXUS_ENERGY_AGENT TO ROLE ENERGY_ANALYST_ROLE;(اجازه اجرای عامل)GRANT USAGE ON DATABASE FUEL_OPS TO ROLE ENERGY_ANALYST_ROLE;(اجازه استفاده از دیتابیس)GRANT USAGE ON SCHEMA FUEL_OPS.PUBLIC TO ROLE ENERGY_ANALYST_ROLE;(اجازه استفاده از اسکیما)GRANT READ ON STAGE FUEL_OPS.PUBLIC.AGENT_SKILLS TO ROLE ENERGY_ANALYST_ROLE;(اجازه خواندن فایلهای مهارت)
تحلیل: از انبار داده به سامانهٔ هوشمند
این معماری نشاندهنده یک تغییر بنیادین در پارادایم «تبدیل متن به SQL» است. اسنوفلیک با انتقال تعریف معنایی (لایه YAML) به هستهی پلتفرم، در واقع یک «دیکشنری مشترک شرکتی» ایجاد میکند که عاملهای هوش مصنوعی ملزم به پیروی از آن هستند. این رویکرد، بار مهندسی پرامپت را از دوش کاربر نهایی برداشته و آن را بر عهده معمار داده میگذارد که میداند دادهها دقیقاً چه معنایی دارند.
با استفاده از یک مجموعه داده نمونه از حوزه توزیع سوخت و انرژی — شامل پایانههای ذخیرهسازی سوخت و معیارهای مصرف منطقهای — روشن میشود که «تحلیلگر AI» دیگر یک چتبات ساده نیست که احتمالاً نام یک ستون را توهم بزند یا اشتباه حدس بزند، بلکه یک رابط تحت حاکمیت (Governed Interface) است که خروجیهایش قابل پیشبینی و تکرارپذیر است.
ادغام توابع ML به عاملها اجازه میدهد از توصیف گذشته به پیشبینی روندهای آینده حرکت کنند. بهطور خاص، تابع FORECAST میتواند برای پیشبینی مقادیر آتی معیارها بر اساس روندهای گذشته در دادههای سری زمانی استفاده شود. توسعهدهندگان میتوانند یک مدل پیشبینی را آموزش دهند، دادههای پیشبینی را تولید کرده و آنها را در یک جدول ذخیره کنند تا به پرسشهای پیشبینانه کاربران (مثلاً: «مصرف سوخت ماه آینده در منطقه شمال چقدر خواهد بود؟») پاسخ دهند.
برای پیشرفت بیشتر، توسعهدهندگان باید ساخت برنامههای سفارشی Streamlit را با استفاده از همین نماهای معنایی بررسی کنند. این کار به آنها اجازه میدهد تا کنترل کاملی بر رابط کاربری (UI)، نحوه استقرار و تجربه نمایش بصری دادهها داشته باشند و اپلیکیشنهای تحلیلی پیشرفتهای بسازند.



گفتگو