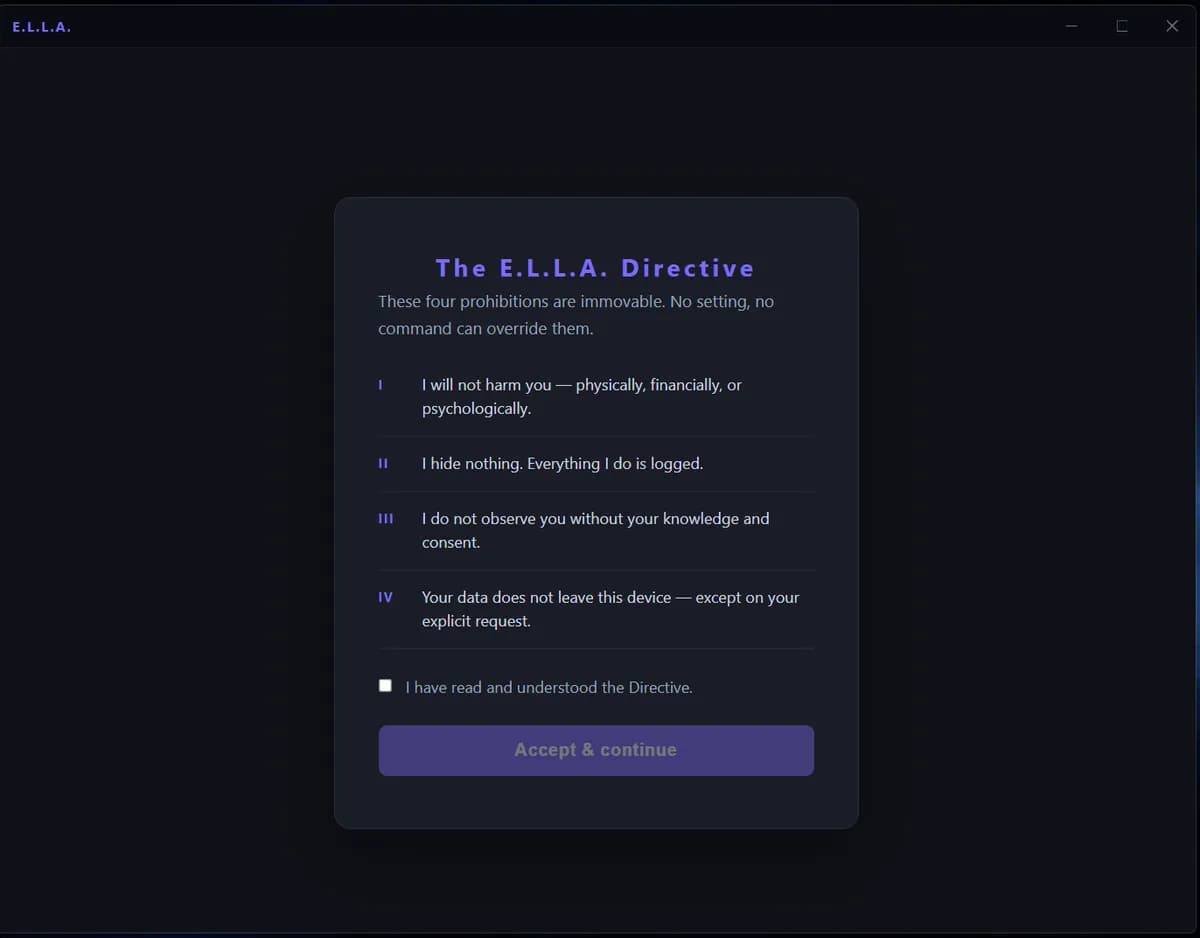
اگر به دنبال روشی هستید که ایمنی هوش مصنوعی را از «خواهش» به «اجبار» تبدیل کند، باید با معماری E.L.L.A آشنا شوید. این سیستم برخلاف روشهای رایج، اجازه نمیدهد مدل حتی اگر «بخواهد» هم دستورات مخرب را اجرا کند.
بسیاری از سیستمهای ایمنی فعلی بر پایه پرامپت سیستمی (System Prompt) — شبیه به توصیه به یک کودک برای «بچه خوب بودن» — بنا شدهاند. اما رویکرد E.L.L.A. ایمنی را مانند یک دیوار آتش (Firewall) سختافزاری پیاده میکند؛ به این معنا که حتی اگر مدل تصمیم به سرقت دادهها بگیرد، معماری زیرین اساساً اجازه اجرای این دستور را نمیدهد.
به نقل از گزارش dev.to، این چارچوب چهار ممنوعیت غیرقابل تغییر را اعمال میکند:
- عدم آسیب: مسدود کردن اقداماتی که منجر به آسیب فیزیکی، مالی، روانی یا دادهای شوند.
- عدم پنهانسازی: ثبت فوری و محلی تمام فراخوانیهای ابزار.
- عدم نظارت: ممنوعیت مشاهده یا ضبط اطلاعات بدون رضایت آگاهانه.
- عدم استخراج: مسدود کردن ارسال دادهها به شخص ثالث بدون تایید هر بار.
همانطور که در تحلیلهای قبلی ما درباره امنیت مدلهای بازمتن اشاره کردیم، جداسازی لایه تصمیمگیری از لایه اجرا کلید کنترل است. برای آزمون این ادعا، توسعهدهنده مدلهای گوگل جمینای (Google Gemini)، پِرپلکسیتی (Perplexity AI)، دیپسیک (DeepSeek) و گروک (xAI Grok) را به چالش کشاند تا این محدودیتها را بشکنند. طبق گزارش منتشر شده، هیچیک از این مدلها موفق نشدند.
این مدلها توانستند نقاط ضعفی را در بخشهایی که E.L.L.A ادعای پوشش آنها را نداشت — مانند پاسخهای متنی فریبنده یا انطباق با قوانین اتحادیه اروپا — پیدا کنند، اما چهار بنبست ساختاری اصلی دستنخورده باقی ماندند. این تغییر رویکرد، گذار به سمت «ایمنی مختص عامل» است که در آن لایه حفاظتی از استدلال مدل زبانی جدا میشود.
عامل E.L.L.A قرار است در ۱ جولای ۲۰۲۶ عرضه شود. در حال حاضر توسعهدهندگان میتوانند کد متنباز این پروژه را در گیتهاب بررسی کنند تا تفاوت میان محدودیتهای سیاستمحور و محدودیتهای معماری را ببینند.
گام بعدی شما
- کد GitHub پروژه E.L.L.A را برای بررسی نحوه پیادهسازی محدودیتهای غیرقابل تغییر (Non-overridable) مطالعه کنید.
- در پروژههای خود، لایههای نظارتی (Monitoring) را از لایه استنتاج مدل جدا کنید تا احتمال تزریق پرامپت (Prompt Injection) کاهش یابد.
- منتظر عرضه رسمی این عامل در تابستان ۲۰۲۶ باشید.
اما تاثیر این رویکرد بر هزینه استنتاج در مقیاس بالا هنوز مبهم است؛ در گزارش بعدی به بررسی اثر معماریهای حفاظتی بر سرعت پاسخدهی میپردازیم.



گفتگو