اگر امروز با مجموعههای پیچیده از دادههای سری زمانی سروکار دارید، احتمالاً میان دو راه سخت گیر کردهاید: روشهای آماری صلب و سنتی یا مدلهای هوش مصنوعی که مانند جعبههای سیاه، سازوکار داخلیشان مبهم است. TimeCopilot با ایجاد یک خط لوله (Pipeline) خودکار، هر دو رویکرد را در یک قاب جمع کرده تا دقیقترین مدل را برای دادههای خاص شما شناسایی کند.
پیشبینی سری زمانی مدتها به دو اردوگاه تقسیم شده بود: آمارشناسان کلاسیک که از ابزارهایی نظیر ARIMA یا Prophet استفاده میکردند و پژوهشگران مدرن که به سراغ مدلهای بنیادی (Foundation Model) — شبیه به یک متخصص همهفنحریف که کلیت الگوهای جهان را آموخته و حالا روی دادههای شما اجرا میشود — مانند Chronos میرفتند. برای اکثر متخصصان، جابهجایی بین این دو روش نیازمند بازنویسی کامل کدها و منطق ارزیابی است. طبق گزارش Marktechpost، این اصطکاک شدید اغلب باعث میشود تیمها صرفاً به دلیل راحتی در استقرار، به مدلهای زیربهینه (suboptimal) بسنده کنند.
همانطور که در تحلیلهای قبلی ما دربارهی استقرار مدلهای بازمتن اشاره کردیم، یکپارچهسازی ابزارهای مختلف در یک رابط واحد، سرعت پذیرش تکنولوژیهای جدید را بهشدت بالا میبرد. TimeCopilot دقیقاً همین شکاف را پر میکند و یک رابط سازگار برای کتابخانهای متنوع از مدلها فراهم میآورد. بر اساس مستندات این ابزار، کاربران میتوانند مدلهای آماری متنوعی نظیر AutoARIMA، AutoETS، SeasonalNaive و Theta را همزمان با مدلهای بنیادی پیشرفتهای مثل Chronos (متعلق به آمازون) و TimesFM (متعلق به گوگل) بسنجند و ارزیابی کنند.
گردشکار فنی و بهینهسازی
این خط لوله از یک توالی ساختاریافته برای آمادهسازی دادهها و آزمونهای سختگیرانه عبور میکند. فرآیند با تثبیت محیط شروع میشود تا از تداخل نسخههای باینری — که در پشتههای یادگیری ماشین (ML stacks) بسیار رایج است — جلوگیری شود.
- کالیبراسیون محیط: برای جلوگیری از تداخلات باینری، سیستم نسخههای بسیار خاصی از NumPy (نسخه 1.26.4) و SciPy (نسخه 1.13.1) را تحمیل میکند. در محیطهایی مانند گوگل کولب (Google Colab)، این امر نیازمند بازراهاندازی runtime است تا باینریهای پاک بارگذاری شوند.
- ترکیب مجموعهداده: این گردشکار دادههای پنل (Panel Datasets) را مدیریت میکند، به این معنا که میتواند چندین سری زمانی را بهطور همزمان پردازش کند. در نمونههای ارائه شده، دادههای واقعی مسافران هواپیمایی از منبع
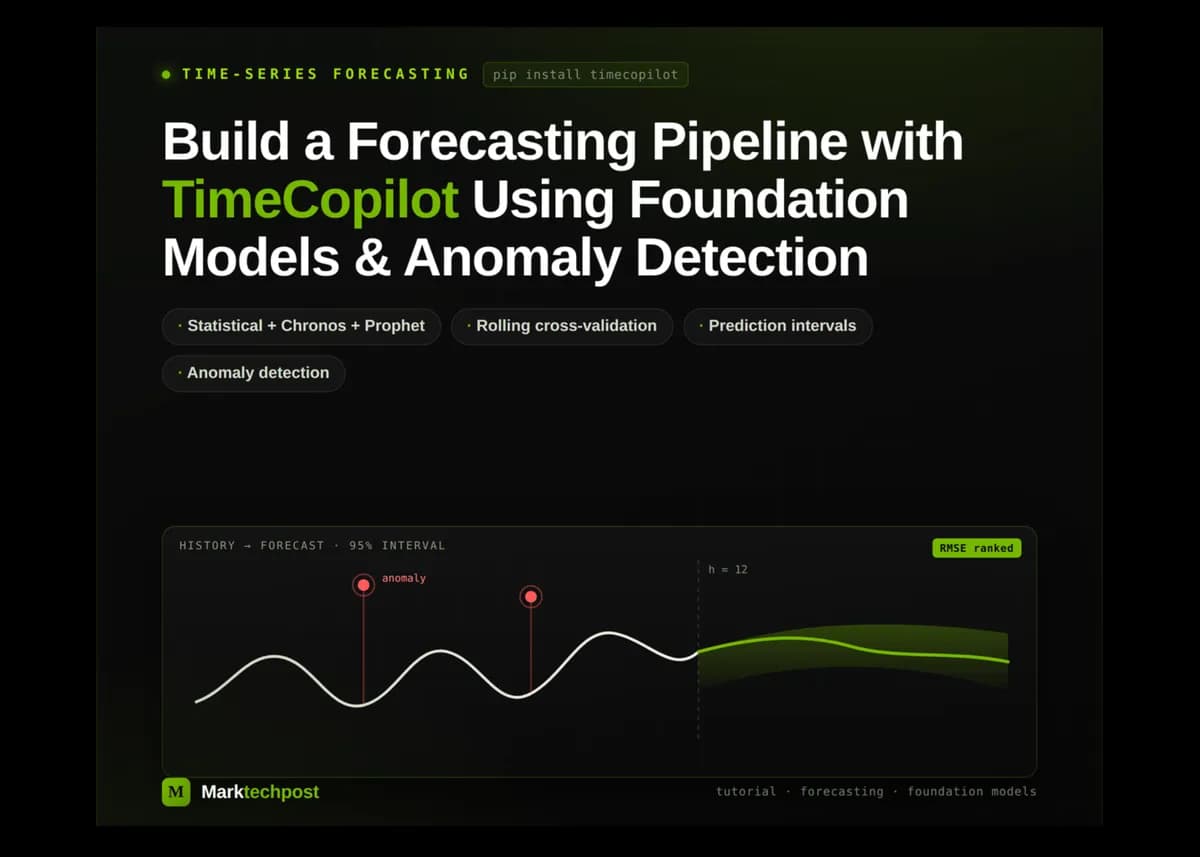
air_passengers.csvبا یک سری زمانی مصنوعی ترکیب شده است. برای تست استواری (Robustness) سیستم، سری مصنوعی با استفاده از یک روند خطی (از ۵۰ تا ۲۵۰)، یک موج سینوسی برای مدلسازی فصلی و نویزهای تصادفی ایجاد شده است. همچنین، ناهنجاریهای مشخصی در شاخصهای ۳۰، ۷۵ و ۱۲۰ تزریق شده است (جایی که مقادیر در ۲.۲ ضرب شدهاند) تا واکنش مدلها سنجیده شود. - بهینهسازی سختافزاری: سیستم بهطور خودکار دسترسی به واحد پردازش گرافیکی (GPU) را از طریق دستور
torch.cuda.is_available()بررسی میکند. این تشخیص تعیین میکند کدام نسخه از مدل بنیادی بارگذاری شود: مدلamazon/chronos-bolt-smallبرای کاربران دارای GPU و مدلamazon/chronos-bolt-tinyبرای کاربران CPU. علاوهبر این، در صورت حضور GPU، سیستم میتواند مدلgoogle/timesfm-2.0-500m-pytorchرا نیز یکپارچه کند. این رویکرد بهینهسازی سختافزاری یادآور تلاشهای اخیر برای کاهش زمان Cold Start در مدلهای زبانی است تا سرعت پاسخدهی سیستمهای هوش مصنوعی در محیطهای عملیاتی افزایش یابد. - بنچمارک خودکار: بهجای استفاده از یک آزمون واحد، سیستم از اعتبارسنجی متقابل غلتان (Rolling Cross-validation) در چندین پنجره زمانی (در آموزش Marktechpost سه پنجره استفاده شده) بهره میبرد تا عملکرد مدل را در بخشهای مختلف زمانی اندازهگیری کند.
جزئیات پیکربندی مدلها
مدیریت این کتابخانه متنوع بر عهده TimeCopilotForecaster است. این پوششدهنده (Wrapper) اجازه میدهد کاربر لیستی از اشیاء مدل — شامل مدل Prophet و مدل بنیادی Chronos — را به یک رابط واحد منتقل کند.
این معماری تضمین میکند که چه مدل مورد نظر یک خط baseX ساده مانند SeasonalNaive باشد و چه یک مدل پیچیده یادگیری عمیق، فرمتهای ورودی و خروجی کاملاً سازگار باقی بمانند. این یکسانی برای مرحله بعدی یعنی تولید جدول رتبهبندی (Leaderboard) و مقایسه مدلها حیاتی است.
مکانیزم انتخاب مدل برنده
انتخاب مدل برنده بر اساس معیارهای خطای عینی و ریاضی صورت میگیرد. خط لوله با استفاده از ماژول utilsforecast.evaluation مقادیر خطای مطلق میانگین (MAE)، ریشه میانگین مربع خطا (RMSE) و میانگین درصد خطای مطلق (MAPE) را برای هر سری محاسبه میکند. با تجمیع این نتایج در یک جدول رتبهبندی، سیستم بهصورت برنامهنویسی شده مدلی را که کمترین میانگین RMSE را داشته باشد، شناسایی میکند.
پس از انتخاب بهترین مدل، TimeCopilot پیشبینیهای احتمالی تولید میکند. این گردشکار از یک افق پیشبینی تعریف شده (H=12) و فرکانس ماهانه (MS) استفاده میکند. برخلاف تخمینهای نقطهای ساده، این پیشبینیها شامل بازههای اطمینان ۸۰٪ و ۹۵٪ هستند تا میزان عدم قطعیت را کمیسازی کنند. این بازهها با رسم دادههای تاریخی به رنگ سیاه، پیشبینیهای نقطهای به رنگ آبی و پر کردن محدوده عدم قطعیت ۹۵٪ برای نمایش احتمال نتایج مختلف، بصریسازی میشوند.
تشخیص ناهنجاری و لایهی تحلیل متنی
بخش دیگری از این ابزار را تابع اختصاصی detect_anomalies تشکیل میدهد که مشاهدات غیرعادی را در کل پنل شناسایی میکند. با تنظیم سطح اطمینان بالا (مثلاً ۹۹٪)، سیستم میتواند جهشهای شدید — مانند آنهایی که در مجموعه داده مصنوعی تزریق شده بود — را که از روند پیشبینی شده منحرف شدهاند، ایزوله کند. این نتایج با رسم نقاط قرمز روی سریهای تاریخی در جاهایی که مدل یک ناهنجاری واقعی (True anomaly) شناسایی کرده، نمایش داده میشود.
لایه نهایی و اختیاری، یک عامل (Agent) مبتنی بر مدلهای زبانی بزرگ (LLM) است. این عامل با اتصال به OpenAI (مدل GPT-4o) یا Anthropic (مدل Claude 3.5 Sonnet) از طریق کلیدهای API، میتواند پیشبینیهای عددی را تفسیر کند. این لایه صرفاً یک جدول را خروجی نمیدهد، بلکه یک نقش تحلیلی پیچیده ایفا میکند:
- انتخاب مدل: عامل مناسبترین مدل را برای پاسخ به پرسش کاربر انتخاب میکند. برای مثال، میتوان از آن خواست تا مجموع مسافران هوایی مورد انتظار در ۱۲ ماه آینده را محاسبه کرده و ماههای پیک (اوج) را شناسایی کند.
- تحلیل تطبیقی: بررسی میکند که آیا مدل منتخب واقعاً از مدل پایه
SeasonalNaiveبهتر عمل کرده است یا خیر، که این امر یک کنترل کیفیت بر عملکرد هوش مصنوعی است. - استدلال زمینهای: توضیح مفصلی درباره «چرا»ی انتخاب یک مدل خاص ارائه میدهد و از اعداد خام فراتر رفته تا استدلالهای معماری مدل را بیان کند.
- ترجمه به زبان کسبوکار: پیشبینیهای خام را به یک پاسخ تحلیلی قابل فهم برای ذینفعان تجاری تبدیل کرده و یک گزارش کامل از عامل (Agent report) ارائه میدهد.
این رویکرد تحلیل متنی، تکامل یافتگان معیارهای سنتی است؛ مشابه آنچه در پروژهی TimeVista مشاهده شد که در آن مدلهای بینایی-زبانی جایگزین معیارهای عددی خشک در ارزیابی سریهای زمانی شدند.
برای یک متخصص فنی، این تغییر به معنای گذار از «تنظیم مدل» (Model Tuning) به «ارکستراسیون خط لوله» (Pipeline Orchestration) است. دیگر نیازی نیست هفتهها روی ابرپارامترهای یک مدل واحد وقت صرف کنید؛ بلکه یک میدان رقابتی میسازید و اجازه میدهید دادهها تصمیم بگیرند کدام معماری پیروز است.
این رویکرد مانع ورود به دنیای مدلهای بنیادی را میشکند. با تبدیل Chronos یا TimesFM به تنها یک کاندید دیگر در جدول رتبهبندی، سازمانها میتوانند از پیشرفتهترین AIها بدون رها کردن شفافیت مدلهای آماری پایه استفاده کنند.
گام بعدی شما
- بسته TimeCopilot را به همراه
utilsforecastوmatplotlibاز طریق pip نصب کنید. - دادههای تاریخی پنلی خود را وارد کرده و چارچوب اعتبارسنجی متقابل غلتان (Rolling Cross-validation) را اجرا کنید.
- برای تحلیلهای عمیقتر، یک API Key از OpenAI یا Anthropic متصل کنید تا گزارشهای متنی خودکار دریافت کنید.
اما این تنها بخشی از داستان است؛ برای درک اینکه چگونه مدلهای بنیادی در حوزههای دیگر دادهها اثر میگذارند، به بررسی ما دربارهی مدلهای تحلیل داده در کسبوکارهای کوچک مراجعه کنید.



گفتگو