
اگر امروز در حال تنظیم دقیق یک مدل متنباز هستید، احتمالاً بهصورت پیشفرض از LoRA استفاده میکنید؛ اما ممکن است بخش بزرگی از عملکرد مدل را نادیده گرفته باشید. Hugging Face تحلیل جامع جدیدی منتشر کرد که نشان میدهد چندین جایگزین برای روش «تطبیق رتبه پایین»، در هر دو معیار بهرهوری حافظه و دقت تست، بهطور کامل بر LoRA غلبه میکنند.
تنظیم دقیق (Fine-tuning) — شبیه وقتی به یک پزشک عمومی، تخصص پوست میدهیم تا روی یک حوزه خاص خبره شود — بهشدت حافظهبر است. بهطور کلی، شما به حافظهای نیاز دارید که بتواند کل مدل را چندین بار در خود جای دهد. در حالی که کوانتیزاسیون اثر حافظه را کم میکند، مدلهای کوانتیزه شده را نمیتوان مستقیماً آموزش داد. برای حل این مشکل، تنظیم دقیق با بهرهوری پارامتر (PEFT) ظهور کرد تا توسعهدهندگان بتوانند مدلها را تنها با بخشی از سختافزار آموزش دهند.
همانطور که در تحلیلهای قبلی ما دربارهی بهینهسازی مدلهای محلی اشاره کردیم، دسترسی به سختافزارهای محدود، اهمیت روشهای PEFT را دوچندان میکند. این روشها مزایای حیاتی دارند:
- اندازه بسیار کوچک چکپوینتها: تنها تعداد کمی از پارامترها ذخیره میشوند.
- مقاومت در برابر فراموشی فاجعهبار: حفظ بهتر دانش مدل پایه.
- چند-مستاجری: امکان ارائه چندین مدل تنظیمشده مختلف از یک مدل پایه واحد.
کتابخانه PEFT در Hugging Face بسیاری از این تکنیکها را پشت یک API واحد پیاده کرده است. این ابزار با اکوسیستمهای Transformers و Diffusers ادغام شده است. همچنین از روشهای مختلف کوانتیزاسیون پشتیبانی میکند تا دسترسی کاربران با سختافزار محدود تسهیل شود. PEFT یک نقطه شروع قدرتمند است، چه در حال تنظیم دقیق روی دادههای اختصاصی باشید و چه در حال تحقیق روی یک روش PEFT کاملاً جدید.
در حالی که دهها تکنیک PEFT وجود دارد، LoRA به استاندارد صنعت تبدیل شده است. این روش با افزودن تعداد کمی پارامتر روی مدل پایه و منجمد کردن وزنهای اصلی عمل میکند و تنها آن پارامترهای اندک را آموزش میدهد. طبق دادههای داخلی Hugging Face، محبوبیت این روش خیرهکننده است.
به گزارش Hugging Face، در بررسی ۲۰,۸۳۴ کارت مدل که تنها از یک روش PEFT استفاده کرده بودند، ۲۰,۵۰۹ مورد (۹۸.۴٪) از LoRA بهره میبردند. در چکپوینتهای تولید تصویر نیز ۷,۱۱۱ مورد از ۱۰,۰۰۰ مورد (۹۵٪) LoRA بودند. سایر روشهای شناسایی شده در این مجموعه شامل LoCon (۳۶۳ مورد) و DoRA (۱۱ مورد) بودند که مورد اخیر را میتوان نوعی گونه از LoRA دانست.
در گیتهاب نیز جستوجوی قطعهکد from peft import <PEFT CONFIG> نشان داد که ۷۱.۳٪ نتایج مربوط به LoRA است. ردههای بعدی را LoHa (۳.۷٪) و AdaLoRA (۳.۵٪) کسب کردند.
این تسلط ممکن است خود-تقویتکننده باشد؛ چرا که LoRA زودتر دیده شد، آموزشهای بیشتری داشت و در بستههای نرمافزاری پاییندستی پشتیبانی بهتری شد. با این حال، بسیاری از پژوهشگران ادعا میکنند روشهای جدیدشان «LoRA را شکست میدهد». Hugging Face هشدار میدهد که این ادعاها اغلب سوگیرانه هستند. تنها در کتابخانه PEFT بیش از ۴۰ تکنیک متمایز پیاده شده است (و اگر گونههای خاص را هم بشماریم، تعداد بیشتر است).
پژوهشگران برای توجیه مقالات جدید تحت فشارند و این منجر به سوگیری میشود؛ مثلاً زمان کمتری برای تنظیم baseline (یعنی همان LoRA) صرف میکنند تا روش پیشنهادی خودشان برتر به نظر برسد. طبق مطالعهای در arxiv.org/abs/2602.04998، صرفاً با تنظیم نرخ یادگیری میتوان LoRA را به سطح تکنیکهای بهظاهر برتر رساند.
سایر پیچیدگیها عبارتند از:
- بنچمارکهای ناسازگار: هر مقاله مجموعهدادهها و تکنیکهای مقایسهای متفاوتی انتخاب میکند.
- تکرارپذیری: کدها اغلب در دسترس نیستند یا اجرای آنها دشوار است.
- فقدان استانداردسازی: هیچ مجموعه شرایط جهانی برای مقایسه روشهای PEFT وجود ندارد.
برای ارائه دیدگاهی عینی، تیم Hugging Face یک بنچمارک استاندارد با مدلهای پایه، مجموعهدادهها، کدهای آموزش/ارزیابی و سختافزارهای یکسان طراحی کرد. تمرکز آنها بر دو وظیفه بود: استدلال ریاضی برای LLMها و یادگیری مفهوم (یک «عروسک گربه») برای تولید تصویر. تمام نتایج بهگونهای طراحی شدند که روی سختافزارهای مصرفکننده اجرا شوند و افزودن آزمایشهای جدید تنها نیازمند یک پیکربندی PEFT جدید و یک اسکریپت است.
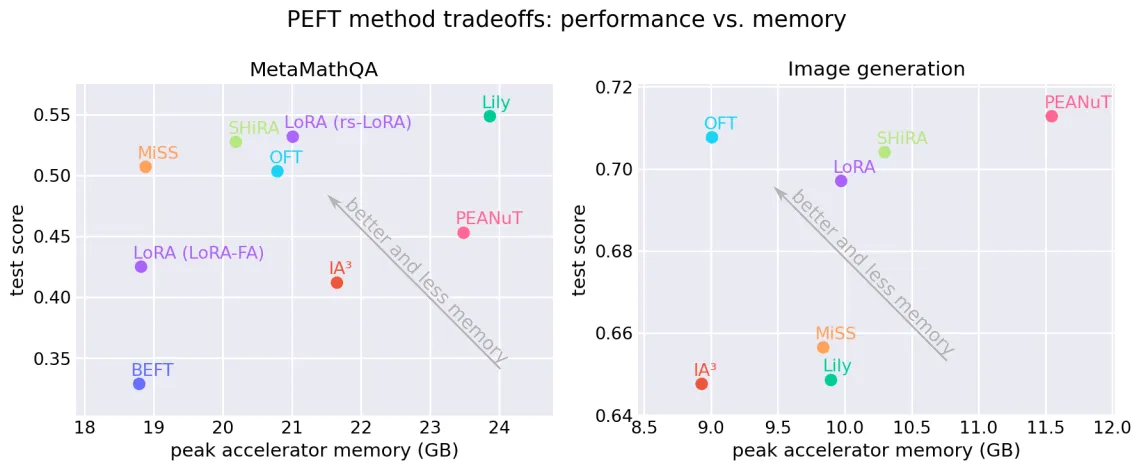
در بنچمارک LLM با استفاده از مدل meta-llama/Llama-3.2-3B روی مجموعهداده GSM8K، تیم اثر متقابل دقت تست و مصرف VRAM را رصد کرد. این آزمون بررسی میکند که آیا یک مدل (که تنظیم دقیق دستورالعمل یا instruction fine-tuned نشده است) میتواند زنجیره تفکر (Chain-of-Thought) — شبیه وقتی شاگرد ریاضی پای تخته بلند بلند فکر میکند تا به جواب برسد — را برای تولید نتایج ریاضی بیاموزد و خروجی را با فرمت مورد انتظار تطبیق دهد یا خیر.
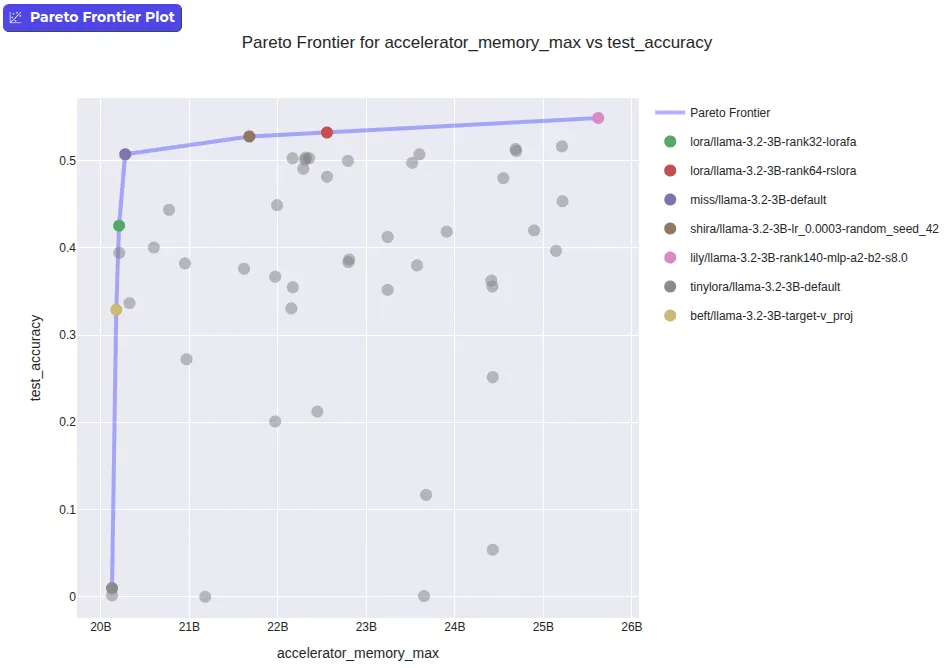
برای تفسیر نتایج، از مفهوم «مرز پارتو» (Pareto Frontier) استفاده شد. تکنیکی روی این مرز است اگر هیچ روش دیگری همزمان در دقت و حافظه از آن بهتر نباشد. اگر دقت بیشتری بخواهید، باید مصرف حافظه بیشتری را بپذیرید و بالعکس.
- LoRA (با مقداردهی اولیه تثبیتشده): با دقت ۵۳.۲٪ و ۲۲.۶ گیگابایت VRAM روی مرز پارتو قرار دارد. این گونه، سهم LoRA را متفاوت از مقداردهی اولیه پیشفرض مقیاسبندی میکند.
- Lily: دقت بالاتری (۵۴.۹٪) دارد اما به حافظه بیشتری (۲۵.۶ گیگابایت) نیاز دارد.
- BEFT: جایگزینی سبکتر است که تنها به ۲۰.۲ گیگابایت حافظه نیاز دارد اما دقت آن ۳۲.۹٪ است.
- LoRA-FA: با استفاده از یک بهینهساز تخصصی که بخشی از وزنهای LoRA را منجمد میکند، نسخهای بهینهتر از LoRA با ۲۰.۲ گیگابایت حافظه ارائه میدهد.
جالب اینجاست که LoRA معمولی (vanilla) عملکرد ضعیفی داشت (۴۸.۱٪ دقت با ۲۲.۵ گیگابایت حافظه)، که نشان میدهد باید از نسخههای تخصصی استفاده کرد.

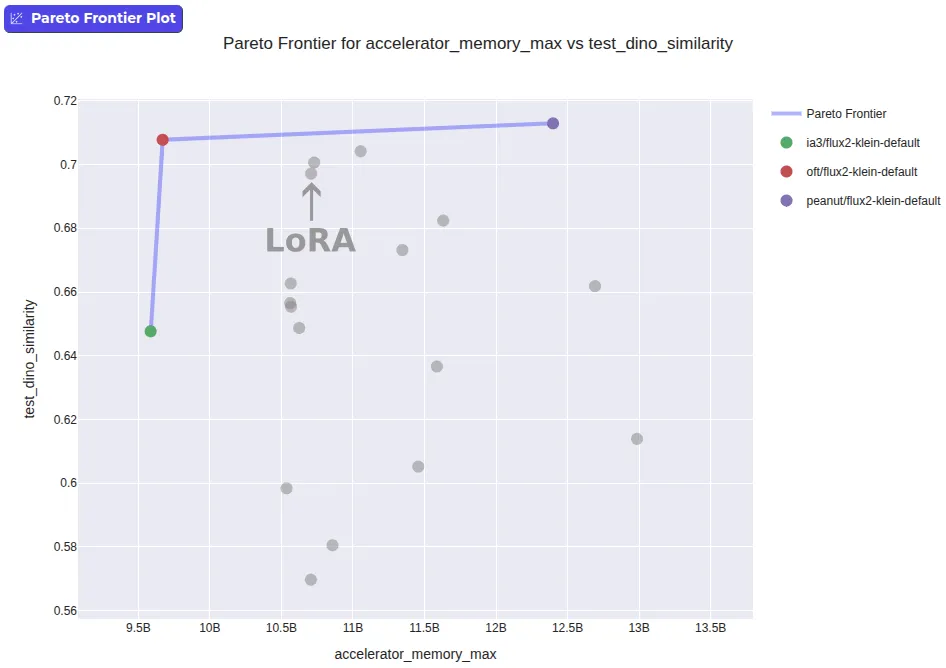
نتایج تولید تصویر با مدل FLUX.2-klein-base-4B قاطعتر بود. هدف یادگیری مفهوم «عروسک گربه» و تعمیم آن به پرامپتهای جدید بود. تیم از «شباهت dino» برای اندازهگیری میزان شباهت تصویر تولید شده به تصاویر یک مجموعهداده تست مجزا استفاده کرد، که در آن مقادیر بالاتر نشاندهنده عملکرد بهتر است.
در این بخش، روش OFT (تنظیم دقیق متعامد) بهطور کامل بر LoRA غلبه کرد. بر اساس دادههای Hugging Face، روش OFT به امتیاز شباهت ۰.۷۰۸ با تنها ۹.۰۱ گیگابایت حافظه رسید، در حالی که LoRA امتیاز ۰.۶۹۷ را با ۹.۹۷ گیگابایت حافظه کسب کرد. چون OFT هم دقیقتر و هم بهینهتر است، LoRA از مرز پارتو خارج شد.
یکی از دلایل تسلط LoRA، ادغام آن در چارچوبهای سرویسدهی مثل vLLM و llama.cpp است. اکثر این ابزارها تنها از چکپوینتهای LoRA پشتیبانی میکنند. برای حل این مشکل، کتابخانه PEFT اکنون امکان تبدیل سایر انواع آداپتورها به فرمت LoRA را فراهم کرده است.
در تست تبدیل آداپتور GraLoRA، امتیاز شباهت تنها تغییر کوچکی داشت (از ۰.۷۰۲ به ۰.۶۹۴ و در موردی دیگر از ۰.۲۶۰ به ۰.۲۶۹). این یعنی توسعهدهندگان میتوانند با روشی برتر آموزش دهند و همچنان از زیرساختهای مبتنی بر LoRA برای استقرار استفاده کنند. اگرچه تبدیل هنوز برای همه تکنیکهای PEFT پیاده نشده، اما تیم قصد دارد پشتیبانی را بر اساس نیاز کاربران گسترش دهد.
جزئیات: انتخاب تکنیک مناسب
علاوه بر دقت و حافظه، تیم پیشنهاد میکند معیارهای دیگر را نیز در نظر بگیرید. بنچمارکها میزان فراموشی/انحراف (drift)، زمان اجرا و اندازه چکپوینت را رصد میکنند تا تصویری عینی ارائه دهند. بسته به نیاز شما، «بهترین» تکنیک میتواند بهطور قابل توجهی تغییر کند.
سختافزار و تبادل عملکرد:
- عملکرد زمان اجرا: برخی تکنیکها اجازه ادغام (merge) آداپتور را میدهند تا سربار زمان اجرا کاهش یابد؛ برخی دیگر این اجازه را نمیدهند.
- اندازه چکپوینت: اگر فضای ذخیرهسازی محدود است، برخی روشهای PEFT بهطور قابل توجهی کوچکتر از بقیه هستند.
- پشتیبانی از کوانتیزاسیون: همه تکنیکها با مدلهای پایه کوانتیزه شده کار نمیکنند، هرچند کتابخانه PEFT فعالانه در حال گسترش این پشتیبانی است.
- مصرف VRAM: نیازهای حافظه پیک بهشدت متفاوت است، همانطور که در فاصله بین BEFT (۲۰.۲ گیگابایت) و Lily (۲۵.۶ گیگابایت) در وظایف LLM دیده شد.
قابلیتهای عملکردی:
- موارد استفاده تخصصی: برای مثال، روش Cartridges بهطور خاص برای فشردهسازی پرامپتهای طولانی توسعه یافته است، قابلیتی که در بنچمارکهای عمومی اندازهگیری نمیشود.
- تغییر لایهها: بسته به تکنیک، تنها انواع خاصی از لایهها قابل تغییر هستند.
- حساسیت به هایپرپارامترها: تیم اشاره میکند که جستوجوی جامع برای یافتن بهترین هایپرپارامترها دشوار است و از جامعه کاربران میخواهد برای بهبود نتایج تکنیکهای خاص، PRهای اصلاحی ارسال کنند.
- معیارهای ارزیابی: برای تولید تصویر، کاربران باید تصاویر نمونه تولید شده را بررسی کنند تا «حس و حال» (vibe) قابلیتهای مدل را فراتر از امتیاز عددی شباهت dino درک کنند.

نتیجهگیری و پیادهسازی
این تغییر دیدگاه به این معناست که برای یک توسعهدهنده، تغییر از LoRA به روشی بالقوه بهتر مانند OFT، اکنون به سادگی تغییر یک خط پیکربندی در کتابخانه PEFT است. برای کسانی که ترجیح میدهند با LoRA بمانند، تیم توصیه میکند گونههایی مانند DoRA، rs-LoRA و LoRA-FA را برای به حداکثر رساندن عملکرد بررسی کنند.
اگر در حال حاضر مدلها را مستقر میکنید، گام بعدی شما باید بازدید از فضای (Space) بنچمارک PEFT باشد تا محدودیتهای سختافزاری خود را با آخرین نتایج مرز پارتو مقایسه کنید. همچنین از جامعه کاربران دعوت شده تا اگر معتقدند هایپرپارامترهای خاصی میتوانند عملکرد یک تکنیک را بهبود بخشند، از طریق PR کمک کنند. تیم همچنین پذیرای ایدههای جدید برای بنچمارکهاست تا تصویر عینیتری از عملکرد PEFT ارائه دهد.
مثال: تغییر از LoRA به OFT با استفاده از PEFT:
from transformers import AutoModelForCausalLM
from peft import OFTConfig, get_peft_model
base_model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-3.2-3B", dtype="bfloat16")
config = OFTConfig(target_modules=["q_proj", "v_proj"])
model = get_peft_model(base_model, config)
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.



گفتگو