
هنوز هم فکر میکنید مدلهای بزرگتر لزوماً باهوشترند؟ تصور کنید مدلی با ۸ میلیارد پارامتر، عملکرد مدلهای چهار برابر بزرگتر از خود را در هم بکوبد.
در ۳۰ آوریل ۲۰۲۶، شرکت IBM از خانوادهی مدلهای Granite 4.1 پردهبرداری کرد و ثابت کرد که یک مدل زبانی کوچک (Small Language Model - SLM) متراکم میتواند معماریهای بسیار حجیمتر را کنار بزند.
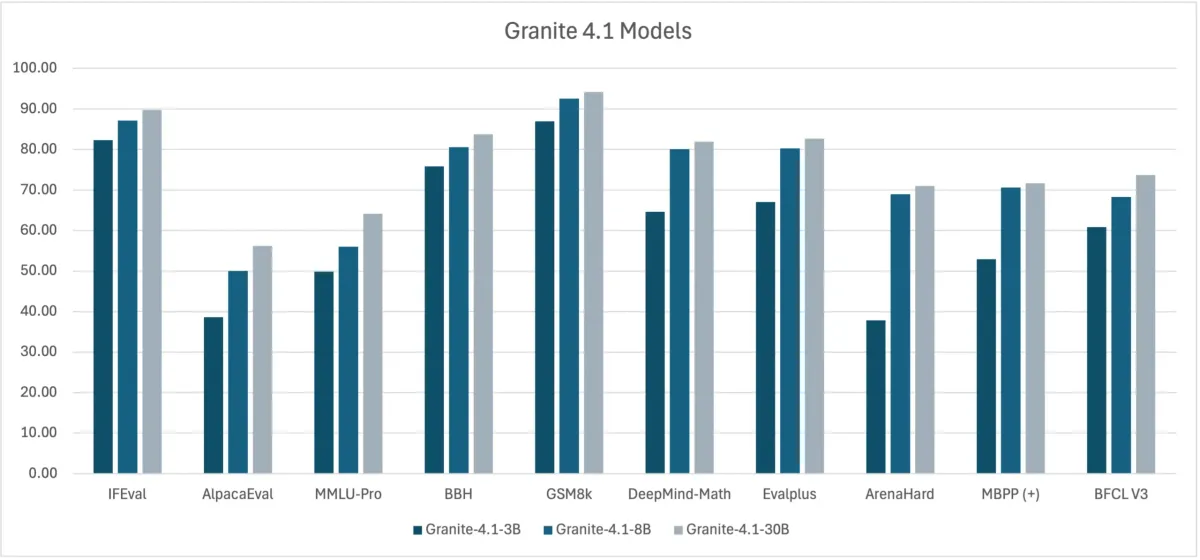
به نقل از firethering.com، مدل ۸ میلیاردی (8B) در بنچمارک ArenaHard امتیاز ۶۹.۰ را کسب کرد و توانست مدل Granite 4.0-H-Small را که یک مدل ۳۲ میلیاردی با معماری مخلوط خبرگان (Mixture of Experts - MoE) بود، شکست دهد. این برتری در زمینهی استفاده از ابزار (Tool Use) نیز مشهود است؛ جایی که مدل 8B با امتیاز ۶۸.۳ در BFCL V3، مدل 32B MoE با امتیاز ۶۴.۷ را پشت سر گذاشت.
طبق اعلام IBM، کلید این موفقیت نه در افزایش مقیاس، بلکه در وسواس روی کیفیت دادهها بوده است. این مدلها در ۵ مرحلهی مجزا و با استفاده از ۱۵ تریلیون توکن آموزش دیدهاند و مسیر یادگیری آنها از دادههای عمومی وب به سمت دادههای متراکم ریاضی و کد تغییر کرده است. برای حذف توهم (Hallucination)، IBM از یک سیستم فیلترینگ مبتنی بر «مدل به عنوان داور» (LLM-as-Judge) استفاده کرد تا هر نمونهای که حاوی محاسبات غلط یا اطلاعات نادرست بود، حذف شود.
همانطور که در تحلیلهای پیشین ما دربارهی قوانین مقیاسپذیری (Scaling Laws) اشاره کردیم، تمرکز بر کیفیت دادهها در حال جایگزینی رویکرد صرفاً کمی است. فرآیند آموزش Granite 4.1 شامل یک خط لولهی چهار مرحلهای یادگیری تقویتشده (Reinforcement Learning - RL) بود:
- آموزش مشترک در ۹ دامنه برای جلوگیری از فراموشی فاجعهبار.
- همراستاسازی (Alignment) از طریق RLHF برای بهبود تعاملات چت.
- کالیبراسیون دانش و هویت.
- یک اجرای اختصاصی RL ریاضی برای بازیابی تواناییهای استدلالی از دست رفته.
برای کاربران سازمانی، مدل 30B با امتیاز ۷۳.۷ در BFCL V3، مدل Gemma-4-31B را شکست داده است. همچنین مدل 3B گزینهای ایدهآل برای رایانش لبه (Edge Computing) است و توانسته Qwen3-8B را در بنچمارکهای ابزاری پشت سر بگذارد. IBM همچنین پنجرهی بافت (Context Window) را برای نسخههای 8B و 30B به ۵۱۲ هزار توکن افزایش داد.
این مدلها با مجوز Apache 2.0 منتشر شدهاند و از طریق Ollama، vLLM یا APIهای IBM قابل بهرهبرداری هستند. اما این تحول در مدلهای متراکم، تنها بخشی از یک بازی بزرگتر است؛ اثر این رویکرد بر آیندهی مدلهای MoE را در گزارش بعدی بررسی خواهیم کرد.
گام بعدی شما
- مدلهای Granite 4.1 را از طریق Ollama برای وظایف استدلالی تست کنید.
- عملکرد مدل 8B را در سناریوهای Tool Calling با مدلهای بزرگتر مقایسه کنید.
- مستندات مجوز Apache 2.0 را برای ادغام تجاری در پروژههای خود بررسی کنید.



گفتگو