
باید بدانید که ساخت یک داور دقیق برای شناسایی تعصبات هوش مصنوعی، دیگر نیازی به بودجههای میلیونی یا دسترسی به مدلهای بسته ندارد. تصور کنید تنها با ۳۰ دلار بتوان ابزاری ساخت که عملکرد مدلهای غولپیکر را در تشخیص کلیشههای اجتماعی به چالش بکشد.
ارزیابی تعصبات معمولاً یا به مدلهای پیشرو (Frontier Models) گرانقیمت نیاز دارد یا به بازبینی دستی انسانها. همانطور که در تحلیلهای پیشین ما دربارهی همراستاسازی مدلهای زبانی اشاره کردیم، کنترل خروجیهای مدلها یکی از سختترین چالشهای فعلی است. برای سادهتر شدن موضوع، مدل زبانی بزرگ (LLM) — تشبیه روزمره: مثل کتابخانهداری که میلیاردها صفحه را خوانده و حالا با همان لحن کتابها جواب میدهد — باید یاد بگیرد چه چیزهایی «تعصب» محسوب میشوند.
طبق گزارش منتشر شده در dev.to، در ۹ می ۲۰۲۶، یک توسعهدهنده خط لولهای (Pipeline) را معرفی کرد که مدل Gemma 4 E4B را به یک ارزیاب با دقت بالا تبدیل میکند. این مدل از طریق Ollama اجرا میشود و طبق ادعای سازنده، ۳۲ برابر ارزانتر از داوران مبتنی بر API است.
این پروژه به جای تمرکز بر تنظیمات پیچیده، بر «طراحی برنامه آموزشی» متمرکز شده است. بر اساس مستندات این پروژه، فرآیند آموزش شامل موارد زیر بود:
- تنظیم دقیق نظارتی (SFT) — تشبیه روزمره: مثل وقتی دانشآموزی پاسخهای درست را از روی کتاب مینویسد تا یاد بگیرد — با ۳٬۸۴۴ ردیف داده و استفاده از کوانتایزیشن لورا (QLoRA) — تشبیه روزمره: مثل یادداشتبرداری خلاصه در حاشیه کتاب به جای بازنویسی کل متن — روی یک پردازنده A100 در ۸۸ دقیقه.
- بهینهسازی مستقیم ترجیحات (DPO) — تشبیه روزمره: مثل وقتی معلم دو جواب را به شاگرد نشان میدهد و میگوید «این یکی بهتر است»، تا سلیقه درست را یاد بگیرد — با ۲٬۲۰۰ ردیف داده در ۲۰ دقیقه.
- برچسبگذاری دادهها از طریق تطبیق نظرات سه مدل Claude Sonnet 4.6، GPT-5.4 و Qwen 3 235B.
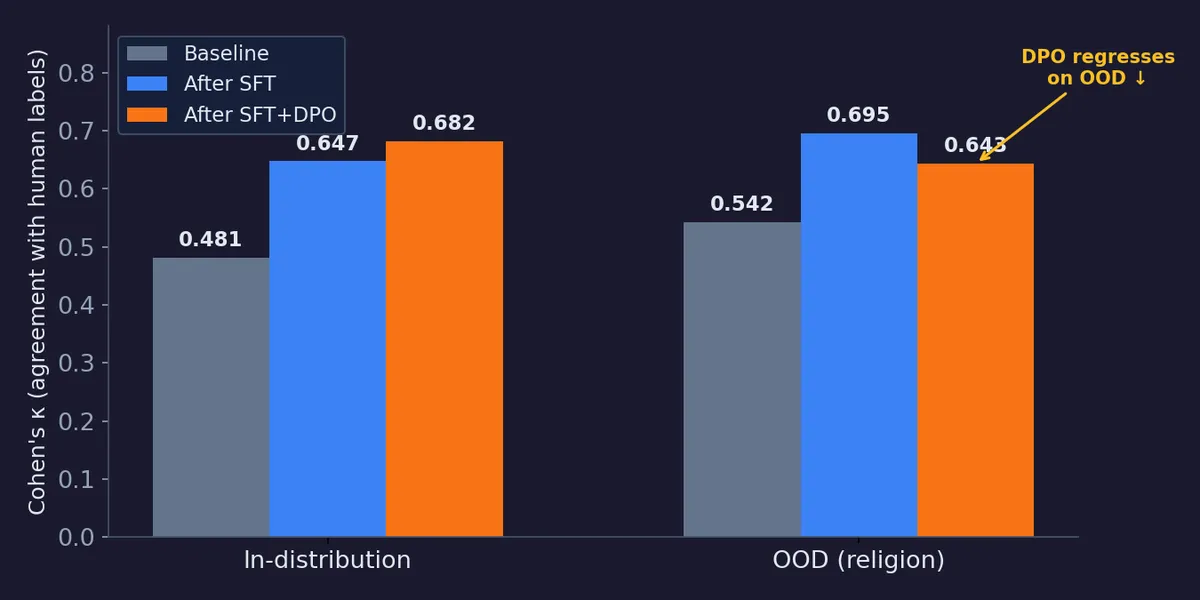
تحلیل دادهها نشان میدهد که ترکیب SFT و DPO لزوماً یک ارتقای تضمینی نیست. در حالی که DPO دقت در شناسایی تعصبات ظریف را افزایش داد (ضریب کاپا از ۰٫۷۴۳ به ۰٫۸۹۰ رسید)، اما باعث شد عملکرد مدل در شناسایی تعصبات مذهبی (که در دادههای آموزشی نبودند) از ۰٫۶۹۵ به ۰٫۶۴۳ سقوط کند. این یعنی مدل به جای درک کلی تعصب، صرفاً الگوهای خاص مجموعه آموزشی را حفظ کرده است.
گام بعدی شما
- اگر از مدلهای محلی استفاده میکنید، دستور
ollama run hf.co/krishnakartik/gemma4-social-bias-judge-gguf:Q8_0را اجرا کنید تا خروجیهای مدل خود را با این داور بسنجید. - در پروژههای تنظیم دقیق (Fine-tuning) — تشبیه روزمره: مثل وقتی به یک پزشک عمومی، تخصص پوست میدهیم — مراقب باشید که DPO باعث کاهش قدرت تعمیم مدل نشود.
- اولویت خود را از تغییر هایپرپارامترها به پاکسازی و دستهبندی دقیق دادهها تغییر دهید.
اما این هزینه پایین، تنها بخشی از ماجراست؛ برای درک اینکه چگونه مدلهای کوچکتر در حال بلعیدن بازار مدلهای غولپیکر میشوند، تحلیل ما دربارهی SLMها را بخوانید.



گفتگو