تأیید صحت پاسخهای عامل (Agent)های حقوقی بهدلیل نیاز به بررسیهای سختگیرانه، هزینهای سرسامآور دارد. اما LangChain و Harvey راهی برای عبور از این سد هزینهای پیدا کردهاند.
در دنیای حقوق، هر تکلیف باید با بیش از ۵۰ معیار مختلف سنجیده شود. همانطور که در تحلیلهای پیشین ما دربارهی استقرار مدلهای زبانی در محیطهای حساس اشاره کردیم، دقت در اینجا با هزینه مستقیم رابطه دارد. استفاده از مدلهای پیشرو مثل Claude Opus 4.7 بهعنوان داور برای هر یک از این معیارها، گلوگاه بزرگی برای مقیاسپذیری ارزیابیها و همچنین مراحل پسآموزش یادگیری تقویتشده (RL) ایجاد میکند.

به نقل از وبسایت langchain.com، این تیم در اوایل ماه جاری بنچمارک LAB را در ۴۰ تکلیف مختلف در حوزههای مالیاتی، سرمایهگذاری خطرپذیر و ادغام شرکتها (M&A) بررسی کردند. آنها دو استراتژی را مقایسه کردند: امتیازدهی بهتفکیک معیار (یک فراخوانی برای هر مورد) در برابر امتیازدهی دستهای (تمام معیارها در یک فراخوانی). مدلهای مورد آزمایش شامل GPT-5.5، Sonnet 4.6 و DeepSeek-V4-Flash بودند.

بر اساس مستندات این پژوهش، نتایج کلیدی به شرح زیر است:
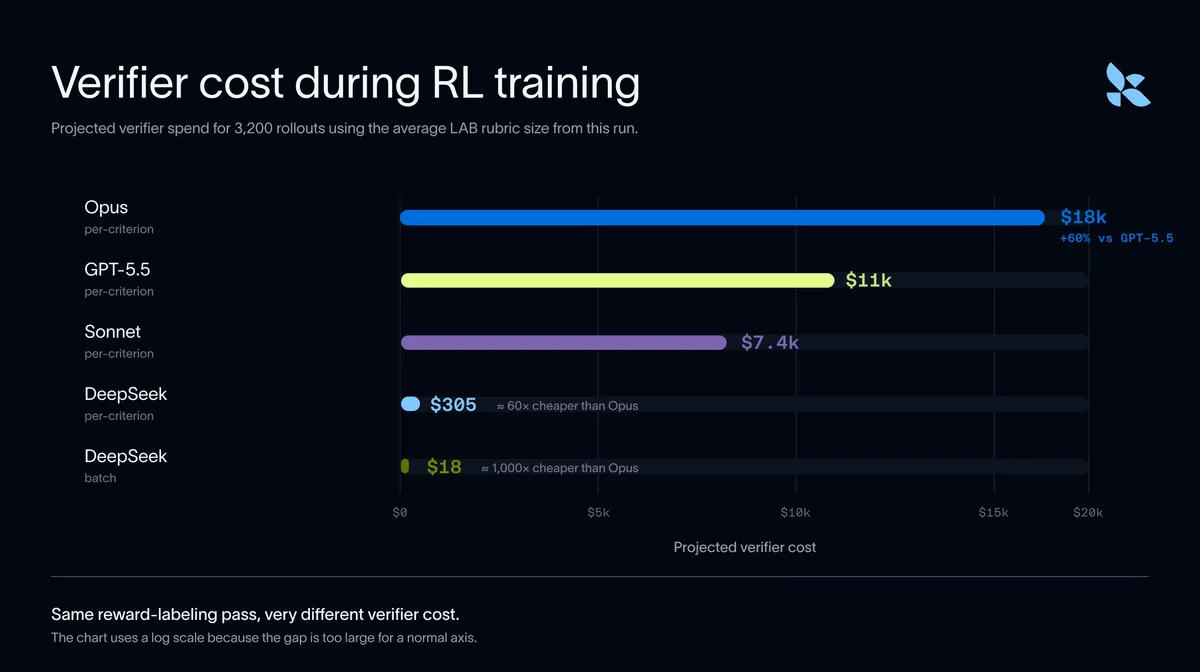
- DeepSeek-V4-Flash بهعنوان جایگزینی با عملکرد بالا و هزینه پایین شناخته شد که در مقیاس بالا، هزینهها را ۶۰ تا ۱۰۰۰ برابر کاهش میدهد.
- تأیید دستهای بهمراتب ارزانتر از فراخوانیهای تفکیکی است، اما نرخ توافق برچسبها در آن پایینتر است.
- مدل Claude Haiku 4.5 بهدلیل نرخ بالای «پذیرفتهای نادرست» (۴۸.۴٪ در حالت تفکیکی)، برای کارهای حقوقی نامناسب تشخیص داده شد؛ به این معنا که این مدل بهکرات پاسخهای غلط را تأیید میکرد. این نرخ بالای خطا در تشخیص صحت، یادآور چالشهای مشابه در ارزیابیهای علمی است؛ چنانکه پیشتر در گزارش SciIntegrity-Bench مشخص شد درصد قابلتوجهی از مدلهای پیشرو در آزمونهای صداقت علمی مردود شدهاند.
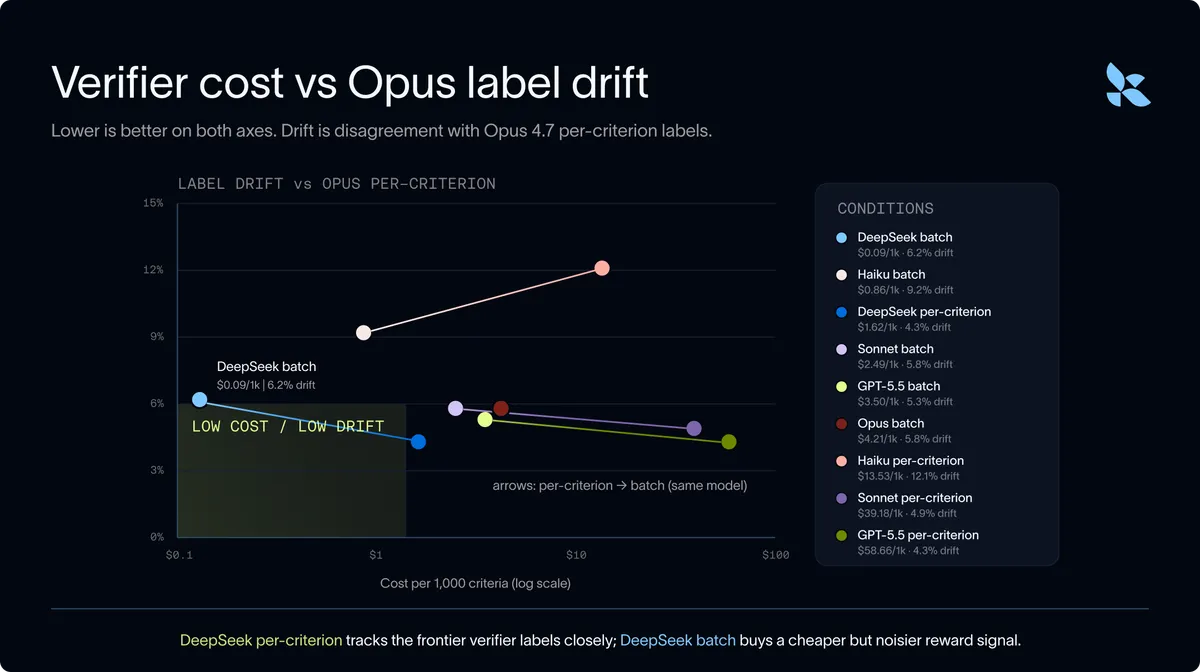
یک اهرم نهایی که آزمایش شد، تنظیم دقیق پرامپت هدف بود. تیم تحقیق با اجبار داور به تجزیه هر معیار به یک چکلیست صریح و دستور به احتیاط در برابر اطلاعات مبهم، توانست نرخ پذیرفتهای نادرست در DeepSeek را در حالت تفکیکی از ۱۰.۷٪ به ۹.۵٪ برساند.
این پژوهش این فرض را که مدلهای بسته پیشرو تنها «استاندارد طلایی» برای تقطیر (Distillation) هستند، به چالش میکشد. از آنجا که Opus و GPT-5.5 در حدود ۴.۳٪ از برچسبها با هم اختلاف دارند، نرخ توافق ۹۵.۷٪ مرز عملی برای سازگاری مدلهای داور است. برای متخصصان، این بدان معناست که هدفگذاری برای تطابق ۱۰۰ درصدی با مدلهای پیشرو غیرواقعی است و تنظیم دقیق (Fine-tuning) مدلهای با وزنهای باز (Open Weights) مسیر بهینهتری برای رسیدن به قابلیت اطمینان است.
گام بعدی شما
- بررسی اثر تنظیم دقیق مدلهای بازمتن روی دادههای حقوقی برای جایگزینی داوران گرانقیمت.
- پیادهسازی استراتژی امتیازدهی دستهای (Batch Scoring) برای کاهش هزینه استنتاج (Inference).
- ارزیابی نرخ پذیرفتهای نادرست در مدلهای کوچکتر پیش از استقرار در محیط عملیاتی.
اما تأثیر این بهینهسازیها بر کیفیت یادگیری تقویتشده در مراحل پسآموزش حتی حیاتیتر است — به تحلیل ما دربارهی معماریهای RL-HF مراجعه کنید.



گفتگو