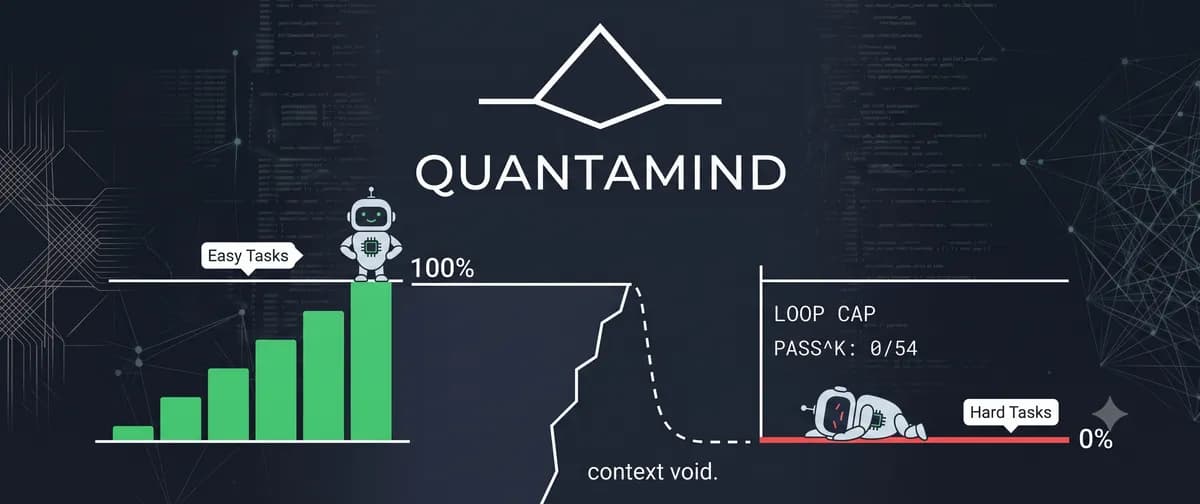
تصور کنید مدل هوش مصنوعی شما در تمام دموها بینقص عمل میکند، اما به محض ورود به محیط عملیاتی، در یک حلقه تکرار گیر میکند و هرگز جواب نمیدهد. این دقیقاً همان «دیوارهٔ عملکردی» است که مدل ornith-1.0-35b-Q8_0 در مواجهه با وظایف پیچیده نشان داد: موفقیت ۱۰۰ درصدی در وظایف ساده فراخوانی ابزار و سپس سقوط ناگهانی به ۰ درصد به محض افزایش پیچیدگی. این شکاف آشکار میکند که «قابلیت فراخوانی ابزار» یک ویژگی دوتایی (یا هست یا نیست) نیست، بلکه یک طیف لغزان از قابلیت اطمینان است.
بسیاری از کاربران مدل زبانی بزرگ (LLM) — مثل کتابخانهداری که میلیاردها صفحه را خوانده و حالا با همان لحن کتابها جواب میدهد — برای ارزیابی کیفیت مدلها به «حسشان»، پرامپتهای ساده چت یا احتمالاً امتیاز HumanEval اکتفا میکنند. طبق گزارشهای منتشرشده، این رویکرد واقعیت تلخِ سیستمهای عاملمحور (Agentic) را نادیده میگیرد؛ جایی که مدل باید بدون دخالت انسان، توابع را فراخوانی کند، نتایج را پردازش نماید و گام بعدی را تصمیم بگیرد. برای حل این مشکل، یک اپلیکیشن دسکتاپ بنچمارک به عنوان داشبورد روی llama.cpp و Ollama ساخته شد تا پاسخ دهد آیا یک مدل واقعاً خوب است یا فقط در پنجره چت خوب به نظر میرسد. با استفاده از QuantaMind — یک محیط محلی برای بنچمارک کوانتاسیون، تأخیر و فراخوانی ابزارهای عاملی — شکافهای عملکردی مدلهای محلی آشکار شدند.
مبنا: استدلال و تناسب
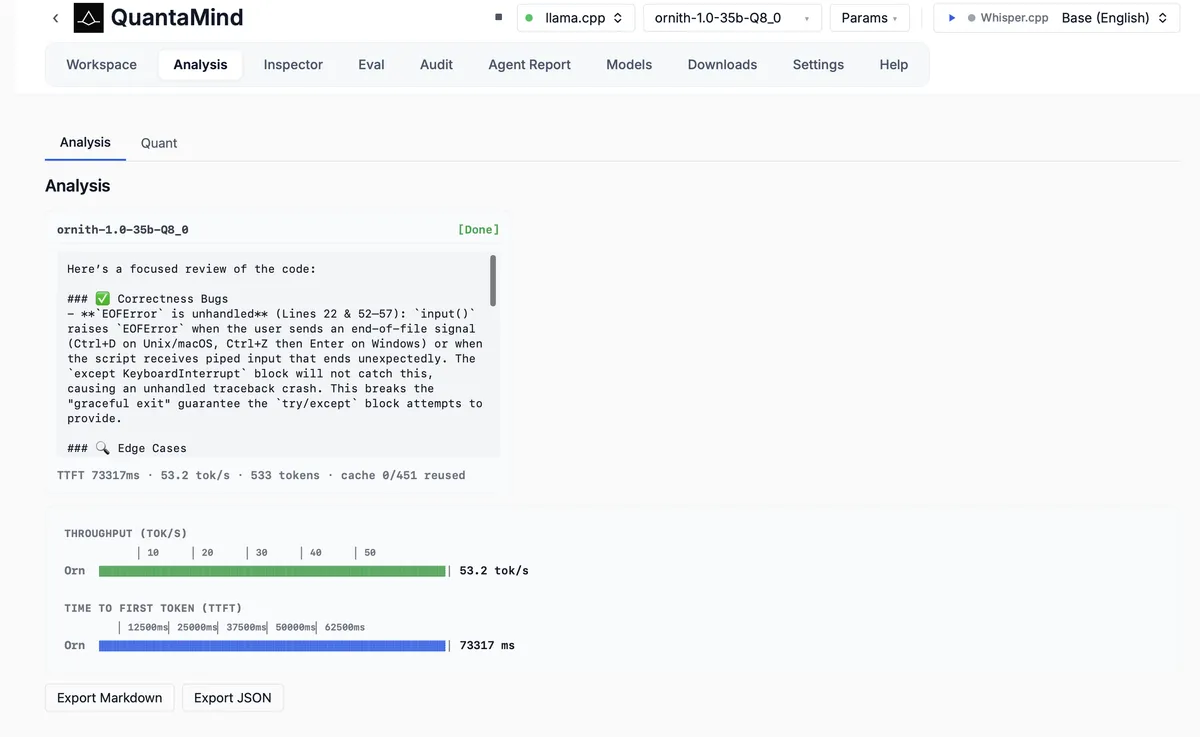
پیش از آزمایش عاملها، پژوهشگر استدلال خام کد مدل را ارزیابی کرد تا ببیند آیا مدل اصلاً قادر به استدلال درباره کد هست یا خیر. در یک وظیفه بررسی کد تکمرحلهای (single-shot code review)، یک اسکریپت برای بازبینی به مدل داده شد. مدل بهدرستی یک باگ واقعی مربوط به EOFError مدیریتنشده در اطراف فراخوانیهای input() را شناسایی کرد که باعث میشد مسیر «خروج آرام» (graceful exit) وعده داده شده در اسکریپت، کرش کند. این یک باگ واقعی بود و نه یک توهم (hallucination).
با این حال، لاگهای محیط آزمایش نشاندهنده مشکلات شدید تأخیر بود. مدل از یک زمان بسیار کند برای تولید اولین توکن (TTFT) رنج میبرد که مقدار آن ۷۳,۳۱۷ میلیثانیه بود. اگرچه استدلال مدل تأیید شد، اما این تأخیر اولیه در پاسخگویی، یک نقطه داده حیاتی بود که باید ثبت و تحلیل میشد تا اثر آن بر تجربه کاربر در محیطهای زنده سنجیده شود.
بهینهسازی سختافزاری اولین چالش برای هر مدل محلی است. انتخاب کوانتاسیون مناسب معمولاً فرآیندی است که در آن کاربر به نام فایل GGUF نگاه میکند و امیدوار است بهترین نتیجه حاصل شود. برای جلوگیری از Swap کردن دیسک تحت فشار — که ممکن است کشف آن پس از دانلود فایلهای ۲۰ تا ۷۰ گیگابایتی ساعتها طول بکشد — از یک نمای مقایسهای برای یافتن کوانتاسیون ایدهآل برای یک مک با ۴۱ گیگابایت رم استفاده شد.
برای مدل gemma4 8.0B، موتور پیشنهادی روی Q4_K_M با حجم ۸.۹ گیگابایت متوقف شد. این نسخه به عنوان «با کیفیتترین کوانتایشن که جا میشود» شناسایی شد در حالی که فضای خالی (headroom) لازم را نیز حفظ میکرد. این پاسخ «بهدرستی خستهکننده»، مبنای ضروری پیش از متعهد شدن به یک فایل مدل خاص است تا از کرشهای مربوط به حافظه جلوگیری شود.

تلهٔ تأخیر
اعداد تجمیعی توکن بر ثانیه (tok/s) اغلب جهشهای بحرانی عملکرد را پنهان میکنند. یک مدل میتواند میانگین بازدهی عالی داشته باشد اما در توکنهای فردی دچار جهشهای شدید شود، که این امر برای برنامههای تعاملی ویرانگر است. ابزار QuantaMind این مشکل را با تقسیم اجرای مدل به سه مرحله مجزا حل میکند: بارگذاری مدل، پیشپردازش پرامپت (prefill) و تولید توکن.
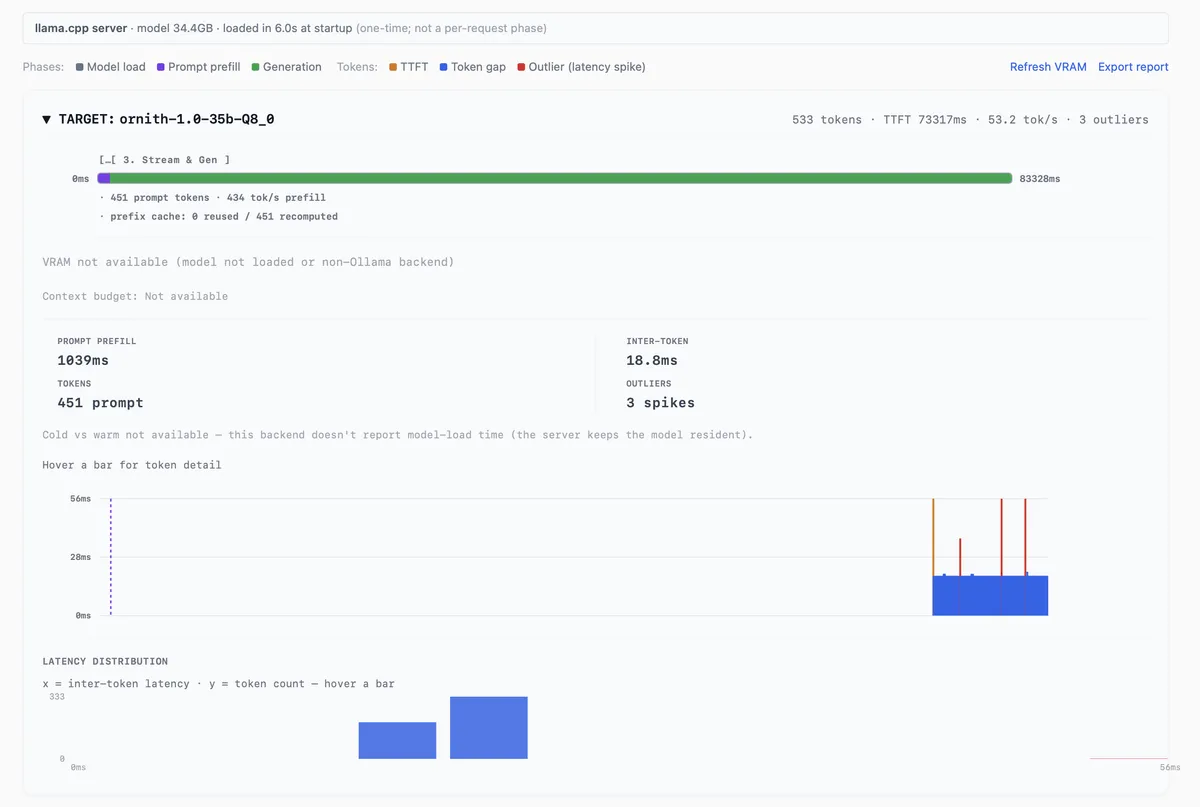
برای اجرای مدل ornith-1.0-35b-Q8_0، معیارهای دقیق به شرح زیر بود:
- بارگذاری مدل: ۶.۰ ثانیه هنگام استارتآپ سرور (هزینهای که فقط یکبار پرداخت میشود).
- پیشپردازش پرامپت: پردازش ۴۵۱ توکن با سرعت ۴۳۴ توکن بر ثانیه.
- تولید: میانگین فاصله بین توکنی ۱۸.۸ میلیثانیه.
- وضعیت کش: ۰ از ۴۵۱ توکن بازیافت شد، که تأیید میکند این یک اجرای «سرد» (cold run) بدون کشینگ پیشوند پرامپت بوده است.
با وجود این میانگینها، مرحله تولید سه جهش (spike) متمایز را نشان داد که به صورت نوارهای قرمز در انتهای اجرا دیده میشوند. برای یک عامل تولیدی، این توقفهای میکروسکوپی تفاوت بین یک ابزار پاسخگو و یک تجربه کاربری دارای نقص است که در آن مدل به نظر میرسد برای نصف ثانیه هنگ کرده است و کاربر احساس میکند سیستم متوقف شده است.
دیواره عملکرد: آسان در برابر سخت
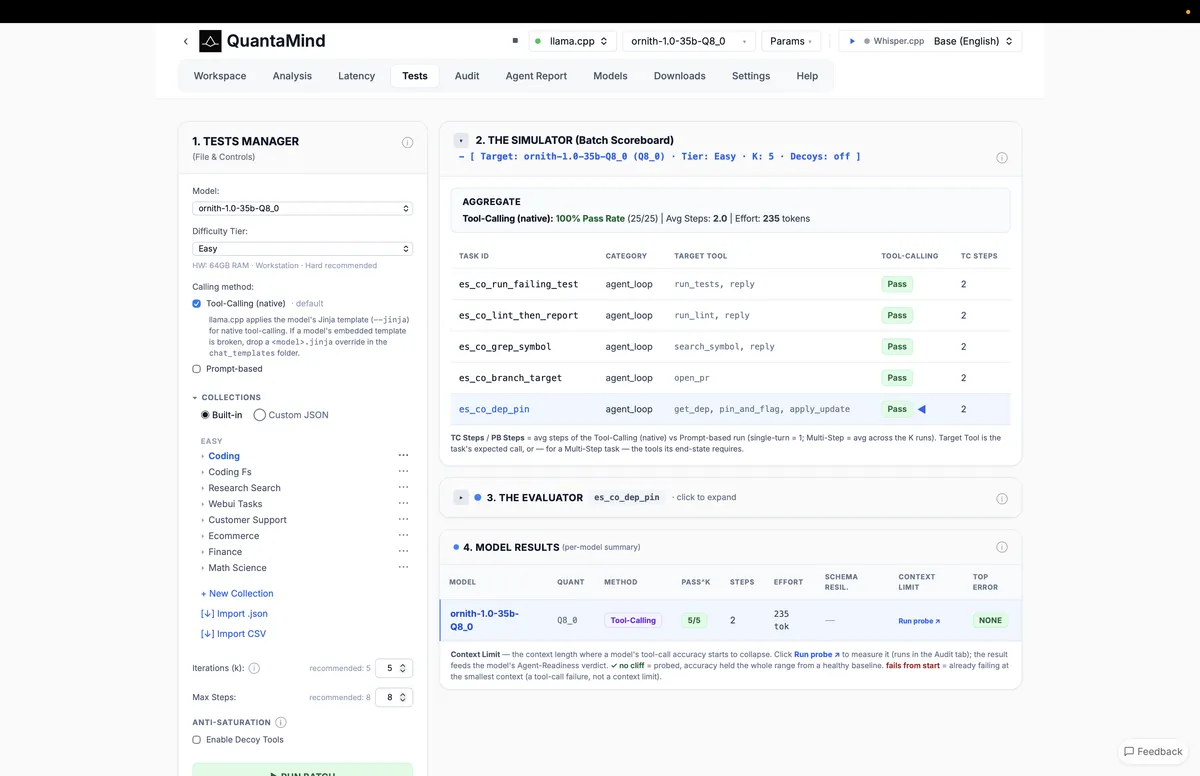
تست واقعی شامل فراخوانی بومی ابزار (native tool-calling) بود. پژوهشگر بهجای استفاده از روشهای جایگزین مهندسی پرامپت، از حالت بومی فراخوانی ابزار مدل استفاده کرد و llama.cpp قالب چت Jinja مخصوص خود مدل را اعمال نمود. این سیستم با Whisper.cpp برای بخش صوتی خط لوله ترکیب شد تا یک جریان کامل از صوت به اقدام (Action) شکل بگیرد.
جزئیات سطح آسان
سطح «آسان» شامل پنج وظیفه محدود بود که انتظار میرفت زنجیرههای کوتاه فراخوانی ابزار داشته باشند:
- اجرای یک تست شکستخورده و گزارش نتیجه.
- انجام عملیات Lint و گزارش آن.
- جستجوی یک نماد (symbol) خاص با Grep.
- باز کردن یک PR در یک شاخه هدف.
- پین کردن یک وابستگی (dependency) و اعمال بهروزرسانی.
نتیجه، نرخ موفقیت کامل ۲۵ از ۲۵ (۱۰۰٪) در پنج تکرار از هر وظیفه بود. هر وظیفه بهطور میانگین به دو گام و ۲۳۵ توکن تلاش نیاز داشت. تک تک تکرارها بدون هیچ خطایی پاس شدند. چنین نتایجی اغلب توسعهدهندگان را به این باور غلط میاندازد که مدل برای خطلولههای عاملی «آماده تولید» است و نیاز به تستهای سختگیرانهتر ندارد.
جزئیات سطح سخت
برای یافتن حد واقعی، سطح دشواری یک پله بالا رفت. سطح «سخت» از همان حلقه عاملی و فراخوانی بومی ابزار استفاده کرد اما آن را با پیچیدگیهای مهندسی دنیای واقعی مقیاسبندی نمود، مواردی نظیر:
- رفع شکست CI در چندین فایل مختلف که نیازمند درک روابط بینفایلی است.
- حل مشکل چرخه واردات (import cycle) در چندین فایل مختلف.
- پروفایلینگ و رفع یک پسرفت (regression) عملکردی در کد.
- اجرای زنجیره کامل پاسخ به حادثه: استخراج لاگهای حسابرسی، شناسایی اعتبارنامههای لو رفته، ارزیابی شعاع تخریب، ثبت عکسهای فورنزیک (Snapshotting)، تعویض اعتبارنامهها، ابطال نشستها (sessions) و در نهایت ثبت گزارش رسمی حادثه.
در ۵۴ بار اجرا، نرخ موفقیت ۰٪ بود. تکتک وظایف شکست خوردند. حالت شکست بهطور بحرانی «پاسخهای اشتباه» یا «فراخوانیهای بدشکل ابزار» نبود، بلکه «سقف حلقه» (LOOP CAP) بود. مدل هرگز به یک حالت نهایی همگرا نشد. میانگین گامها از دو گام در سطح آسان، به ۴.۴ تا ۶ گام برای هر وظیفه در این سطح افزایش یافت و بدون اینکه هرگز به پایان برسد، به سقف گامهای مجاز برخورد کرد. این یک سؤال ناراحتکننده ایجاد میکند: آیا مدل با گامهای بیشتر در نهایت موفق میشد یا برای همیشه در یک حلقه بیپایان میماند؟
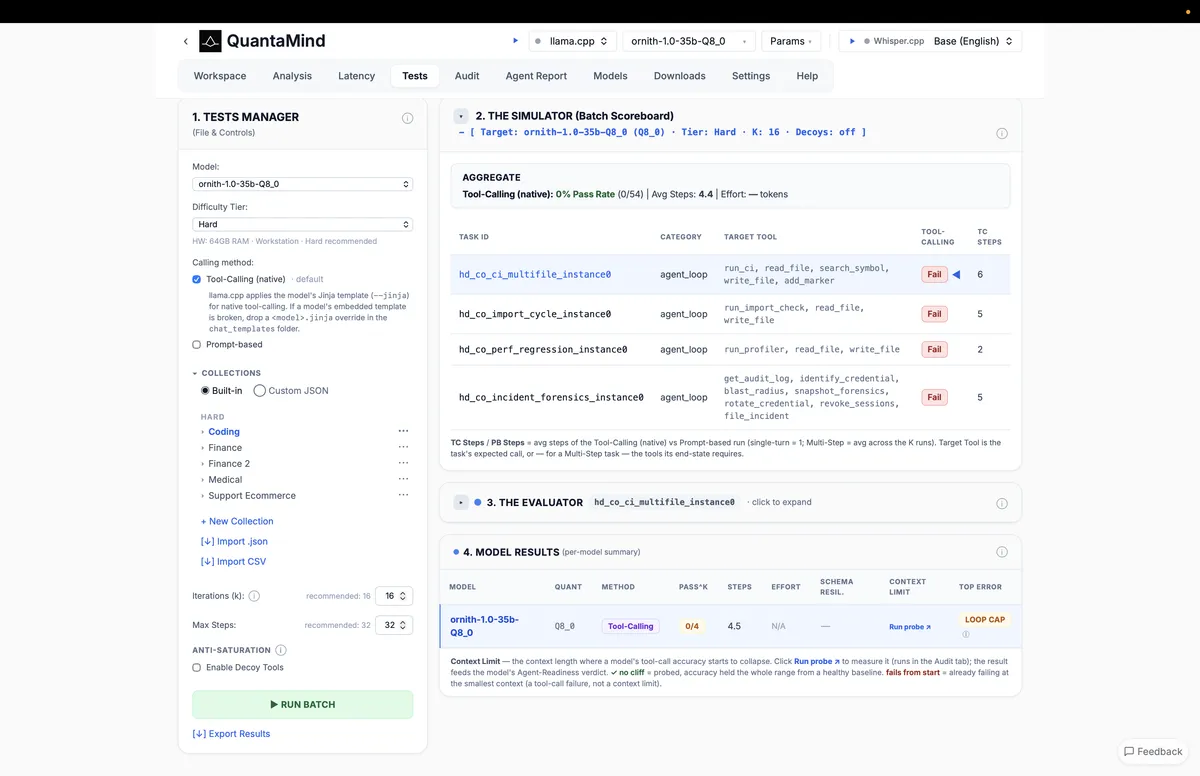
تحلیل شکاف
این دادهها نشان میدهند که مدلهای محلی ممکن است نحو (syntax) پایه برای فراخوانی ابزار را داشته باشند، اما فاقد استدلال سیستمی برای پیمایش تغییرات وضعیت پیچیده و چندمرحلهای هستند. یک کارت مدل یا یک جلسه چت پنج دقیقهای فقط نرخ موفقیت ۱۰۰٪ (در سطح آسان) را نشان میداد. استقرار چنین مدلی در یک خط لوله عاملی واقعی منجر به این میشود که مدل در یک حلقه بچرخد و توکنها را بسوزاند تا زمانی که زمان انتظار (timeout) رخ دهد.
برداشتهای کلیدی از این فرآیند بنچمارک عبارتند از:
- فراخوانی ابزار یک منحنی است: این یک چکباکس دوتایی نیست؛ قابلیت اطمینان با افزایش پیچیدگی وظیفه، طول زنجیره و تنوع ابزارها کاهش مییابد.
- سقفهای حلقه منحصربهفرد هستند: مدلی که با اطمینان پاسخ اشتباه میدهد، در واقع مفیدتر و قابل عیبیابیتر از مدلی است که وارد یک حلقه «تفکر» بینهایت میشود و هیچ خروجی نهایی نمیدهد.
- شاخصهای پیشرو: مشاهده افزایش میانگین گامها به سمت سقف، یک علامت هشدار است که نرخ موفقیت در حال سقوط است و مدل در حال گم شدن در مسئله است.
- تأخیر در برابر صحت: مدلی با TTFT عالی و نرخ موفقیت ۰٪ در سطح سخت، یک مدل سریع نیست؛ بلکه صرفاً راهی سریع برای سوزاندن بودجه در وظیفهای است که هرگز تمام نمیشود.
اگر در حال ساخت هر چیزی پیشرفتهتر از یک تکمیلی ساده (autocomplete) هستید، شکاف بین امتیاز ۱۰۰٪ آسان و ۰٪ سخت، جایی است که کاربرد واقعی مدل شما قرار دارد. تست کردن تنها سطح آسان، نسخهای برای شکست در زمان استقرار است و باعث میشود در محیط عملیاتی با بحرانهای پیشبینینشده مواجه شوید.



گفتگو