
مدلهای بازگشتی احتمالاً راهی یافتهاند تا بدون تحمل هزینههای محاسباتی عظیم، با قدرت بازیابی اطلاعات در ترنسفورمرها برابری کنند. طبق تحلیل فنی منتشرشده در ۳۰ ژوئن ۲۰۲۶ و با حمایت مالی Paradigm، تعامد ماتریس حافظه در mLSTM توانایی این مدل را در بازیابی اطلاعات از توالیهای نویزی بهطور چشمگیری افزایش میدهد.
در حالی که ترنسفورمر (Transformer) از مکانیسم توجه کوادراتیک استفاده میکند تا توکنها دسترسی مستقیم به موارد پیشین داشته باشند، شبکههای عصبی بازگشتی (RNN) همواره با چالش بازیابی تداعی (Associative Recall یا AR) دستوپنجه نرم کردهاند. برای کاربردهای حساس مانند یادگیری تقویتی با افق بلند — مانند مدلهای Dreamer — هزینهی محاسباتی توجه کامل اغلب غیرقابل تحمل است. این موضوع نیاز مبرمی به RNNهایی ایجاد میکند که بتوانند جفتهای کلید-مقدار خاص را با وجود نویزهای مزاحم (Interleaved Distractor Noise) به خاطر بسپارند.
درک بازیابی تداعی
همانطور که در تحلیلهای پیشین ما دربارهی معماریهای جایگزین ترنسفورمر اشاره کردیم، جستوجو برای مدلهایی با حافظه کارآمدتر، اولویت اصلی پژوهشگران است. اما ابتدا باید مفهوم بازیابی تداعی را بررسی کنیم. بازیابی خالص، همانطور که در محکهای سادهای مثل MQAR اندازهگیری میشود، تنها یک نقطه شروع است؛ چرا که محیطهای واقعی معمولاً دارای گذارهای نویزی هستند. پژوهشگران برای تست این موضوع، از بازیابی تداعی نویزی (Noisy Associative Recall یا NAR) استفاده کردند.
به نقل از مستندات این پروژه، در یک تسک NAR تولیدشده توسط ژنراتور MAD، مدل ممکن است توالیای مانند "0 9 3 10 12 13 15 14 0 9 5 8 2 9" را ببیند. در این مثال، کلید ۰ به مقدار ۹ و کلید ۳ به مقدار ۱۰ متصل است. سیستم از محدودههای توکن مجزا برای کلیدها، مقادیر و عوامل مزاحم استفاده میکند؛ برای نمونه، اگر کلیدها در بازه ۰ تا ۵ باشند، توکنهای ۱۲ تا ۱۵ به عنوان عوامل مزاحم (distractors) عمل میکنند. یک مدل موفق باید بتواند مقدار ۹ را در جایگاه دهم پیشبینی کند، بدین معنا که نگاشت اولیه ۰ $\rightarrow$ ۹ را به خاطر بیاورد و در عین حال نویزهای میانگیر را نادیده بگیرد.
الهام از Muon
پژوهشگران برای حل این چالش از Muon الهام گرفتند؛ بهینهسازی که در مدلسازی زبان بسیار موفق است. Muon با تعامد تکانهها (Momenta)، مانند یک متعادلکننده برای جهتهای نمایشیافته عمل میکند. این مکانیسم مانع از آن میشود که چند جهت قدرتمند بر بهروزرسانیها غلبه کنند و در عوض، جهتهای ضعیفتر را تقویت میکند.
بر اساس بررسی منابع متعدد، تحقیقات اخیر نشان میدهد که Muon بهویژه در یادگیری حافظهی تداعی در لبههای توزیع (Tail-end associative memory learning)، از Adam پیشی میگیرد. تئوری این است که این متعادلسازی مانع از آن میشود که خاطرات ضعیفتر توسط خاطرات قویتر «بیرون راندن» یا سرکوب شوند. تیم تحقیق در این رویکرد جدید آزمایش کرد که آیا تعامد ماتریس حافظه در mLSTM طی فرآیند خواندن (Readout) نیز اثر مشابهی در بهبود عملکرد NAR دارد یا خیر.
پیادهسازی فنی
در مرحله پیادهسازی فنی، نسخهی تعامدیافته با مدل پایه (Baseline) در پیشبینی توکن بعدی روی نمونههای نویزی MAD مقایسه شد. برای حفظ عملکرد، مجموعهای از محدودیتهای خاص اعمال شد:
- نرمالسازی از طریق نرم فروبنیوس ( Frobenius norm) با مقدار eps = 1e-6.
- اجرای پنج تکرار نیوتن-شولتز (Newton-Schulz) برای دستیابی به تعامد.
- اجازه به جریان گرادیان (Gradient flow) در طول این فرآیند.
- نکته کلیدی و حیاتی: حافظه تعامدیافته به وضعیت (State) مدل بازگردانده نشد، زیرا این کار باعث افت عملکرد میشد. بنابراین، تعامد تنها برای عملیات خواندن (Readouts) استفاده شد.

تنظیمات آزمایشگاهی
برای آموزش و ارزیابی، تیم از تنظیم frac_noise برابر با ۰.۸ در مجموعه MAD noisy-recall استفاده کرد. پارامترهای آموزش بهشدت کنترل شدند تا نتایج قابل اتکا باشند:
- بهینهساز: AdamW با مقادیر (betas = 0.9, 0.999 و weight_decay = 0.01).
- مدت زمان: ۲,۰۰۰ گام با اندازه دسته (batch size) ۶۴.
- نرخ یادگیری: در چهار حالت 3e-4، 1e-3، 3e-3 و 1e-2 برای هر تنظیمات مورد بررسی قرار گرفت.
- دادهها: در هر گام دستههای جدیدی تولید شدند و برای هر آزمایش، یک مجموعه اعتبارسنجی (Validation set) ثابت و مجزا در نظر گرفته شد.
عملکرد در بنچمارکها
نتایج حاصل از مجموعه MAD نشان داد که نسخه تعامدیافته در تمام رژیمهای تست، مدل پایه را شکست داد. این جهش در قابلیت اطمینان (Seds با موفقیت بالای ۸۰٪) بهطور خیرهکنندهای مشهود بود:
- واژگان ۸۰، طول ۱۰۲۴: مدل تعامدیافته به صحت ۹۸.۵٪ رسید (۲۳ از ۲۴ سید)، در حالی که مدل پایه با ۸۳.۳٪ (۱۹ از ۲۴ سید) عقب ماند.
- واژگان ۸۰، طول ۷۶۸: مدل تعامدیافته صحت ۹۱.۷٪ (۲۲ از ۲۴ سید) را کسب کرد در مقابل ۷۵.۹٪ (۱۳ از ۲۴ سید) برای مدل پایه.
- واژگان ۸۰، طول ۵۱۲: مدل تعامدیافته به ۸۷.۵٪ (۲۰ از ۲۴ سید) رسید در مقابل ۶۹.۱٪ (۱۷ از ۲۴ سید) برای مدل پایه.
- واژگان ۹۶، طول ۷۶۸: مدل تعامدیافته به صحت ۶۲.۴٪ (۱۴ از ۲۴ سید) دست یافت، در حالی که مدل پایه تنها ۲۲.۰٪ (۴ از ۲۴ سید) بود.
- واژگان ۹۶، طول ۱۰۲۴: مدل تعامدیافته صحت ۶۸.۵٪ (۱۶ از ۲۴ سید) را ثبت کرد در مقابل ۲۳.۱٪ (۴ از ۲۴ سید) برای مدل پایه، که نشاندهنده دلتای مثبت ۴۵.۴٪ است.
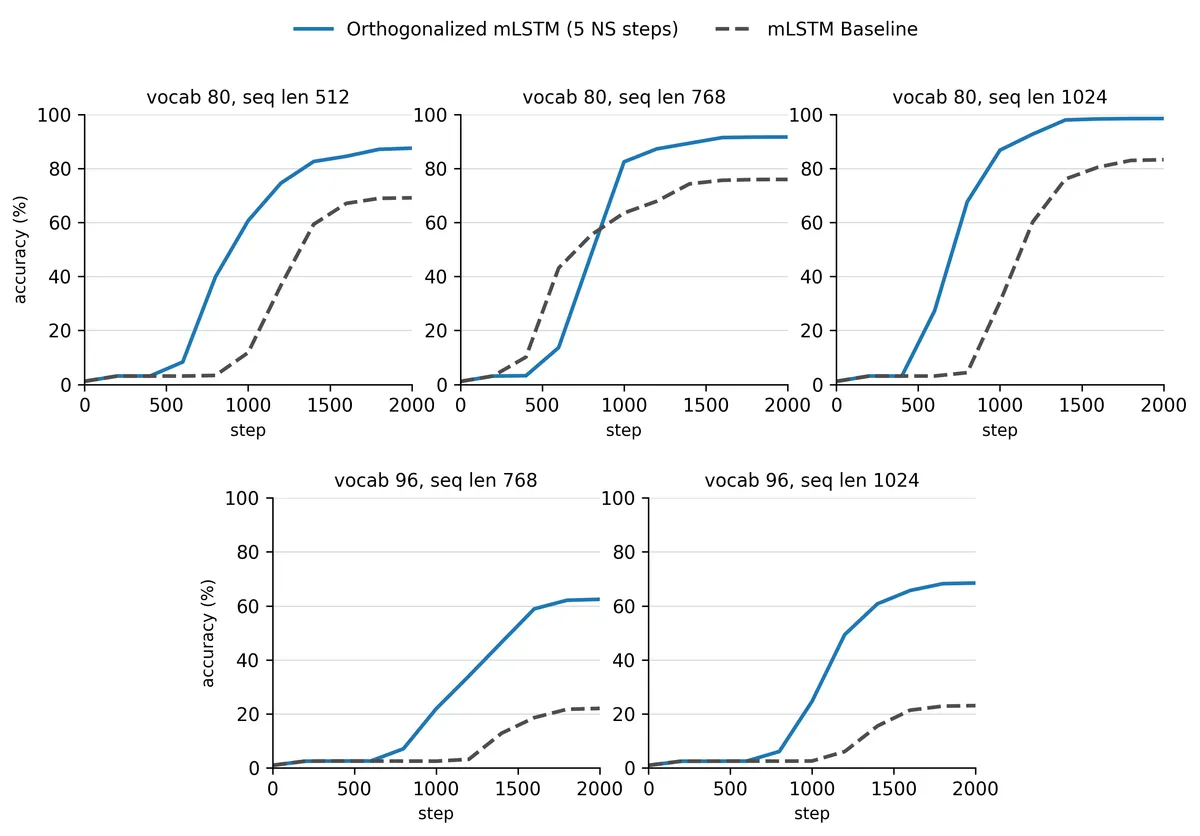
این نتایج فرض قدیمی را که «حافظه ماتریسی خالص برای بازیابیهای پیچیده کافی است» تغییر میدهد. مشاهده میشود که شکاف عملکردی با سختتر شدن تسکها (بهویژه در رژیم واژگان ۹۶) عمیقتر میشود. این امر بیانگر آن است که تعامد بیشترین کمک را زمانی میکند که mLSTMهای معمولی در آستانه شکست هستند و مدل را از وضعیت شکست کامل به عملکردی بهطور قابلتوجه مطمئن میرساند.
محدودیتها و سبک-سنگینها
این مداخله، بهبودهای عملکردی را در تعداد پارامترهای ثابت ایجاد میکند: ۷۷,۷۱۶ پارامتر برای واژگان ۸۰ و ۸۰,۷۴۰ پارامتر برای واژگان ۹۶. با این حال، پژوهشگران هشدار میدهند که این نتایج در رژیم مدلهای کوچک و روی تسکهای ساختگی (Synthetic) بهدست آمده است.
هزینه اصلی این روش، محاسباتی است؛ تکرارهای نیوتن-شولتز نیازمند عملیات اعشاری (FLOPs) اضافی هستند و زمان اجرای واقعی (Wall-clock time) را افزایش میدهند. اینکه آیا این دستاوردهای ساختگی به بنچمارکهای دنیای واقعی برای مدلهای در مقیاس بزرگتر ترجمه میشوند یا خیر، پرسش کلیدی و بازِ پیشروی این حوزه است.
گام بعدی شما
- اگر روی مدلهای بازگشتی برای پردازش توالیهای طولانی کار میکنید، پیادهسازی لایهی تعامد در مرحله readout را آزمایش کنید.
- بررسی کنید که آیا جایگزینی Adam با Muon در پروژههایتان، نرخ یادگیری حافظات تکنمونهای را بهبود میبخشد یا خیر.
- منتظر گزارشهای مربوط به استقرار این متد در مدلهای با پارامتر بیشتر برای بررسی مقیاسپذیری باشید.
اما تأثیر این رویکرد بر کاهش مصرف حافظه در لبه (Edge) حتی حیاتیتر است؛ در تحلیلهای آینده به بررسی بهینهسازیهای سختافزاری برای این مدلها خواهیم پرداخت.



گفتگو