اگر در حال توسعهی عاملهای سازمانی هستید که با مستندات حجیم دستوپنجه نرم میکنند، سد بزرگی همین امروز فرو ریخت. مدل جدید MiniMax M3 پنجره متنی یک میلیون توکنی را در قالب یک مدل بازمتنی ارائه میدهد؛ قابلیتی که تا پیش از این تنها در مدلهای تجاری و بسته وجود داشت.
مدل زبانی بزرگ (LLM) — مثل کتابخانهداری که میلیاردها صفحه را خوانده و حالا با همان لحن کتابها جواب میدهد — برای پردازش حجم زیاد داده به حافظهای نیاز دارد که به آن پنجره متنی (Context Window) میگویند؛ شبیه به میز کاری که هرچه بزرگتر باشد، ورقهای بیشتری را همزمان پیش روی خود دارد. تا پیش از این، چنین حافظهای تنها در انحصار غولهایی مثل Gemini 3.1 Pro یا GPT-5.5 بود. اما شرکت چینی MiniMax در ۱ ژوئن ۲۰۲۶ با انتشار این مدل، توازن قدرت را تغییر داد و وزنهای باز (Open Weights) — یعنی همان «دستور پخت» مدل که حالا علناً منتشر شده — را در دسترس همگان قرار داد.
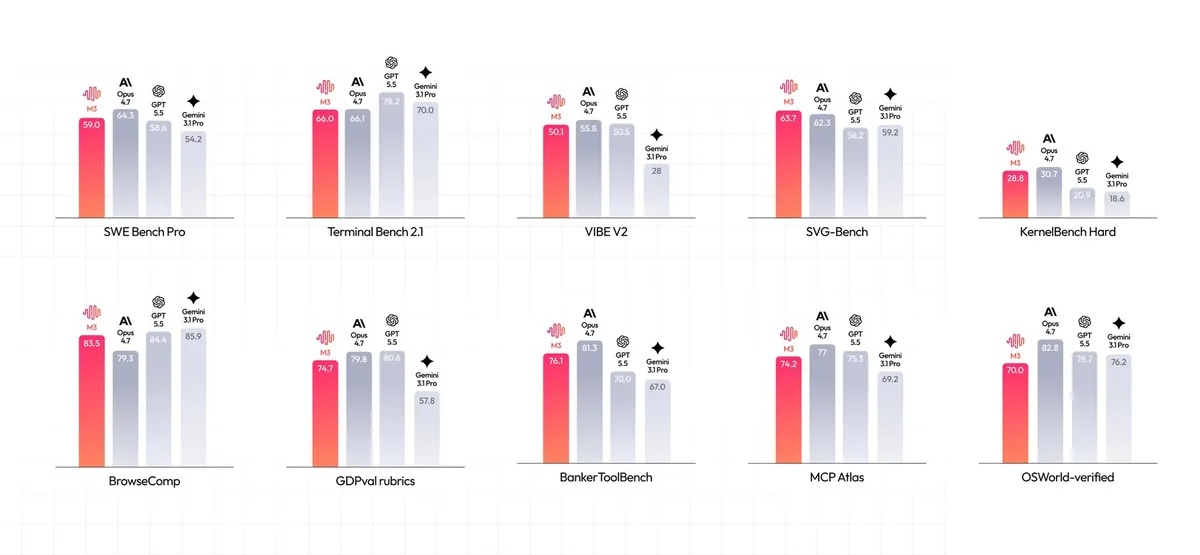
همانطور که در تحلیلهای قبلی ما دربارهی مدلهای استدلالی اشاره کردیم، دسترسی به حافظه بلندمدت، کلید تبدیل یک چتبات ساده به یک عامل هوشمند است. طبق گزارش the-decoder.com، مدل M3 در بنچمارک توسعه نرمافزار SWE-Bench Pro امتیاز ۵۹٪ را کسب کرد. این عدد آن را بالاتر از GPT-5.5 و Gemini 3.1 Pro قرار میدهد و تنها مدل Opus 4.7 است که همچنان پیشتازی میکند.
این مدل برای رسیدن به این سطح از کارایی از مکانیزمی به نام MiniMax Sparse Attention (MSA) استفاده میکند. این فناوری با تقسیم حافظه به بلوکهای کوچک و فیلتر کردن دادههای نامرتبط، سرعت استنتاج (Inference) — لحظهای که مدل واقعاً جواب تولید میکند، شبیه به خودِ آشپزی و نه دورهی آموزش آن — را ۹ برابر سریعتر از نسخههای قبلی کرده است.
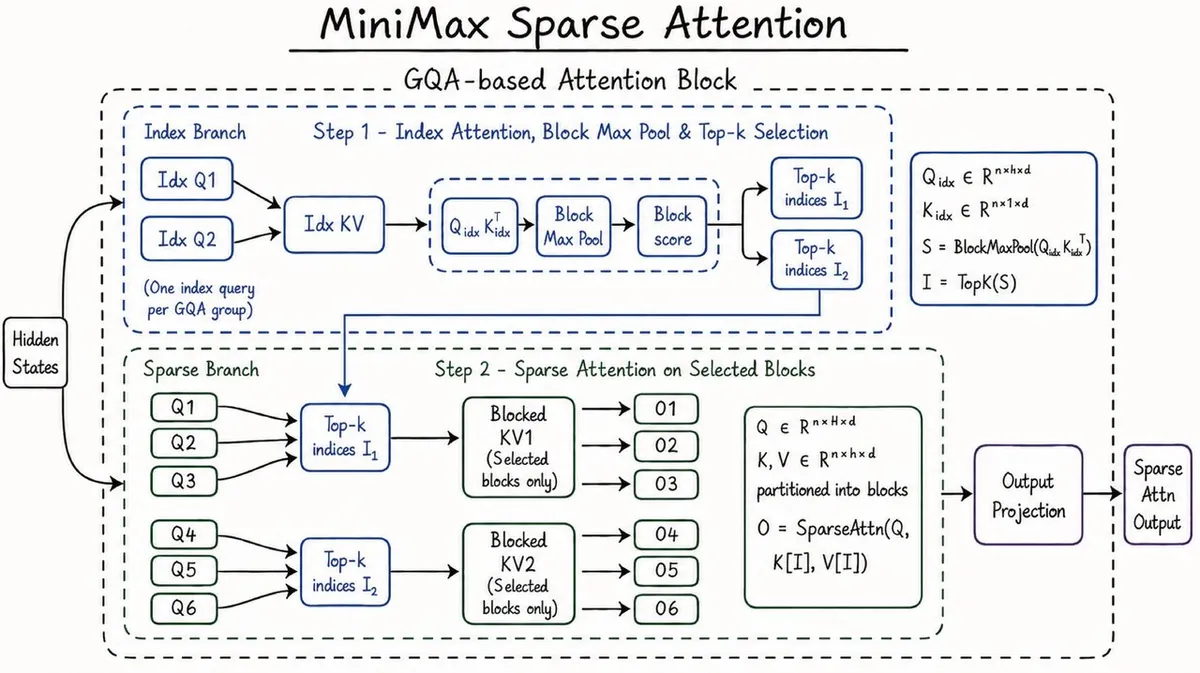
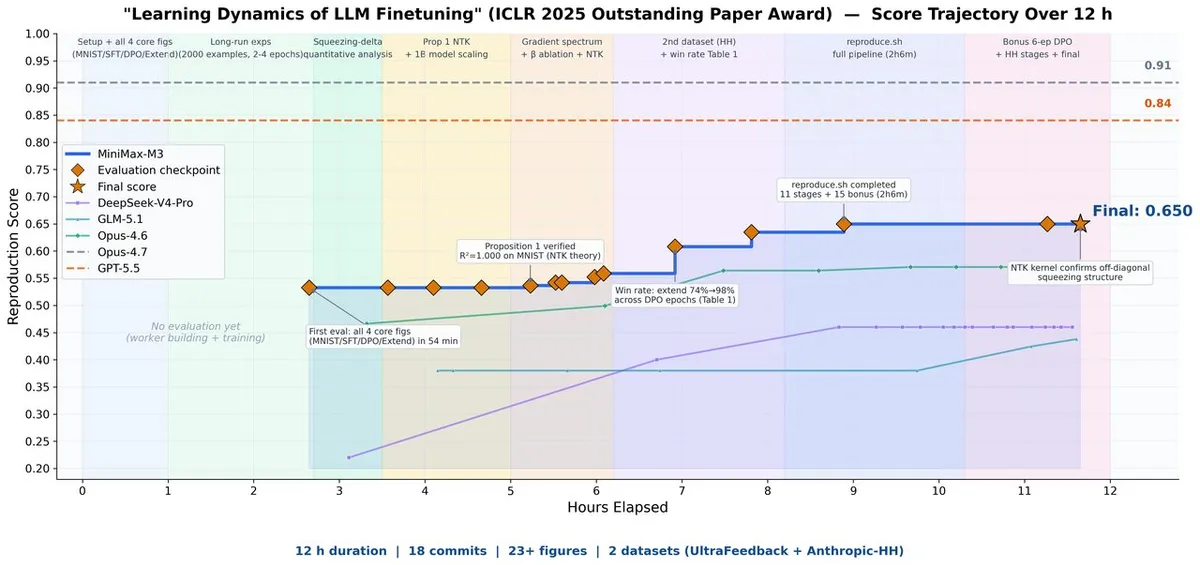
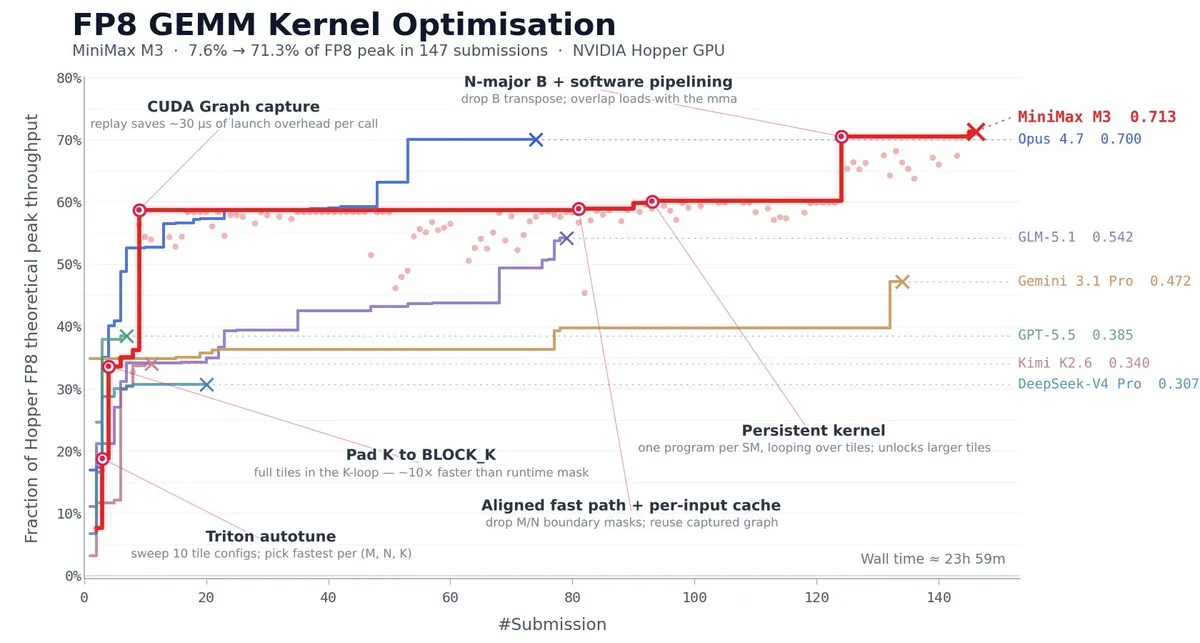
بر اساس مستندات منتشر شده، استقلال عملکرد M3 در سه آزمون سختگیرانه ثابت شده است:
- بازتولید مستقل یک مقاله علمی از ICLR 2025 در مدت ۱۲ ساعت.
- افزایش بهرهوری GPUهای Nvidia Hopper از ۷.۶٪ به ۷۱.۳٪ تنها در ۲۴ ساعت.
- کسب امتیاز ۸۳.۵ در آزمون جستجوی وب BrowseComp و پیشی گرفتن از Opus 4.7.
برای مدیران کسبوکار، این اتفاق به معنای حذف «مالیات انحصار» روی مدلهای حافظهبلند است. دیگر لازم نیست برای پردازش میلیونها توکن از دادههای حساس شرکتی، صرفاً به یک ارائهدهنده آمریکایی اعتماد کنید. این چرخش، جنگ قیمتها را در APIهای حافظهبلند آغاز میکند و انتقال به سمت عاملهای محلی و با کارایی بالا را سرعت میبخشد. این مدل همچنین چندوجهی (Multimodal) است؛ یعنی مثل ما که با چند حس دنیا را میخوانیم، همزمان متن، عکس و صدا را میفهمد.
گام بعدی شما
- در ۱۰ روز آینده، انتشار رسمی وزنهای مدل را در Hugging Face دنبال کنید.
- اگر از سختافزارهای اختصاصی استفاده میکنید، بهینهسازی هسته (Kernel) مدل M3 را برای سختافزار خود تست کنید.
- در صورت استفاده از مدلهای بسته برای کدنویسی، هزینه استنتاج خود را با مدلهای بازمتن مقایسه کنید.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است؛ اثر این مدل بر مصرف انرژی مراکز داده را در گزارش بعدی بررسی خواهیم کرد.



گفتگو