
اگر برای مدیریت دیتابیسهای برداری هزینههای کلان میپردازید، بازی تغییر کرده است. تصور کنید ۱۰۰ میلیون بردار را تنها با ۳۵۰ دلار در ماه مدیریت کنید.
این ادعا متعلق به OpenData Vector است؛ موتور جستجویی که در ۱۴ مه ۲۰۲۶ عرضه شد. این ابزار برخلاف سیستمهای قدیمی، از معماری بدون وضعیت (Stateless) استفاده میکند — شبیه استفاده از یک فایل مشترک در گوگل درایو به جای ذخیره نسخههای جداگانه روی هر کامپیوتر. همانطور که در تحلیلهای قبلی ما دربارهی بهینهسازی هزینههای زیرساختی اشاره کردیم، حذف گرههای پیچیده، کلید کاهش هزینههاست.
به نقل از مستندات این پروژه، سیستم بر پایه SlateDB ساخته شده و برای حفظ سرعت در اتصالهای کندِ S3، از سه سازوکار استفاده میکند:
- نمایهسازی IVF: از یک ایندکس فایل معکوس برای دستهبندی دادهها استفاده میکند تا از پرشهای کند بین گرهها جلوگیری کند.
- فشردهسازی LIRE: یک مدل «فقط-افزودنی» دارد تا بهروزرسانیها بدون نیاز به چرخههای گرانقیمت خواندن-تغییر-نوشتن انجام شوند.
- وضعیت اشتراکی: هر گره دسترسی کامل به دادههای S3 دارد و نیازی به ارتباط با گرههای دیگر نیست.
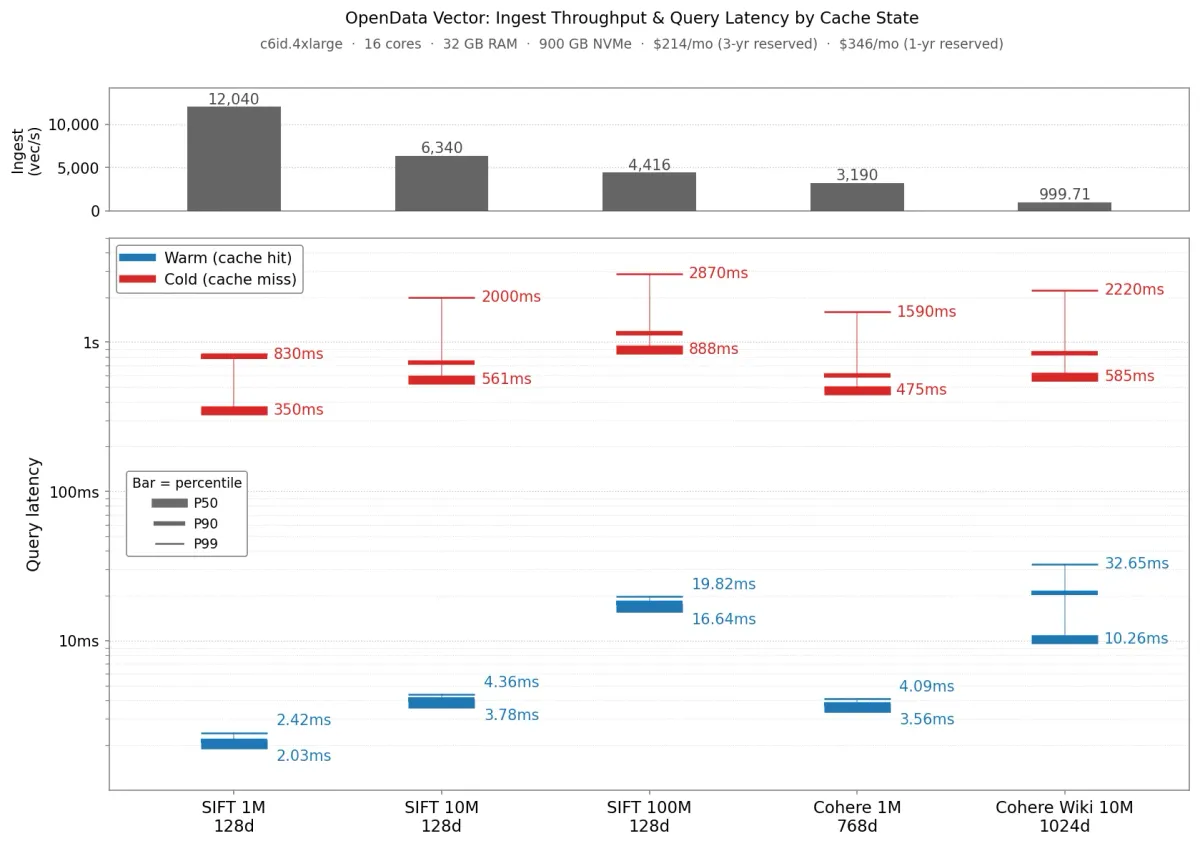
طبق گزارش تیم توسعه، در بنچمارکهای اجرا شده روی گره c6id.4xlarge، پاسخهای سریع (Warm) در کمتر از ۱۰ میلیثانیه بازگشتند. حتی پاسخهای کند (Cold) که نیاز به دریافت داده از S3 داشتند، زیر یک ثانیه زمان بردند. همچنین این سیستم توانست بین ۱,۰۰۰ تا ۱۲,۰۰۰ بردار معنایی (Embedding) — مثل کارت معرفی عددی برای هر واژه که میگوید این کلمه «همسایهی» چه کلمات دیگری است — را در ثانیه بنویسد.
این تغییر، «مالیات فروشنده» را حذف میکند. به باور ما، دیگر نیازی نیست برای خدمات مدیریتشده، چندین برابر قیمت سختافزار هزینه کنید. اکنون میتوانید یک سیستم جستجوی صنعتی را روی یک پاد تنها در کوبرنتیز اجرا کنید، بدون اینکه نگران از دست رفتن دادهها باشید.
گام بعدی شما
- بررسی مستندات MIT این پروژه برای جایگزینی دیتابیسهای گرانقیمت
- دنبال کردن آپدیتهای مربوط به جستجوی متنی (Full-text search) برای تبدیل ابزار به یک دیتابیس همهمنظوره
- تست سرعت کوئریهای Cold در محیط S3 برای ارزیابی تأخیر
اما داستان کاهش حجم دادهها با کوانتیزاسیون حتی جذابتر است — به تحلیل ما دربارهی مدلهای کوچک مراجعه کنید.



گفتگو