
تصور کنید دستیاری دارید که بهجای پیشنهاد دادن چند خط کد، کل پروژه شما را میفهمد، مسیر اصلاح باگ را برنامهریزی میکند و تا رسیدن به جواب درست، کد را تست و تصحیح میکند. این دقیقاً همان تفاوت مدلهای کدنویسی سنتی با مدلهای عاملمحور (Agentic) است که اکنون در Ornith-1.0 محقق شده است. کدنویسی عاملمحور در واقع تغییری بنیادین است؛ گذر از مدلهایی که صرفاً قطعهکدهای کوتاه پیشنهاد میدهند به سمت عاملهایی که میتوانند یک اصلاحیه کامل را برنامهریزی کنند، دستورات شل (Shell) را اجرا نمایند و در نهایت صحت کار خود را تأیید کنند.
به نقل از مستندات این پروژه، در ۲۹ ژوئن ۲۰۲۶، خانواده مدلهای Ornith-1.0 منتشر شد تا استانداردهای جدیدی را در کدنویسی خودمختار تعریف کند. در حالی که بیشتر مدلهای متنباز تنها به تکمیل کد محدود هستند و در مواجهه با «داربست» (Scaffold) — یعنی همان گامهای منطقی مورد نیاز برای حل یک باگ پیچیده در سطح مخزن (Repo) — دچار مشکل میشوند، Ornith-1.0 فرآیند برنامهریزی را به عنوان یک مهارت قابل یادگیری میبیند. بزرگترین مدل این خانواده توانسته است به امتیاز ۸۲.۴٪ در بنچمارک SWE-bench Verified دست یابد.
این تفاوت را میتوان به تفاوت میان دانشجویی که چند فرمول را حفظ است و توسعهدهندهای که میداند چگونه یک محیط عملیاتی (Production) را دیباگ کند، تشبیه کرد. اکثر مدلهای هوش مصنوعی امروز از نوع اول هستند؛ اما Ornith-1.0 با بهینهسازی مسیر جستجوی راهکار (Search Trajectory)، هدفش تبدیل شدن به نوع دوم است. همانطور که در تحلیلهای قبلی ما دربارهی امنیت مدلهای بازمتن اشاره کردیم، دسترسی به وزنهای مدل اجازه میدهد تا توسعهدهندگان کنترل دقیقی روی لایههای استدلالی داشته باشند. در Ornith-1.0، برنامهریزی برای حل باگها دیگر یک حدس نیست، بلکه یک مهارت یاد گرفته شده است.
معماری خودبهبهبود
نوآوری اصلی Ornith-1.0 در چارچوب آموزشی خودبهبهبود آن است. طبق اعلام تیم سازنده، آنها بهجای اتکا به مجموعهدادههای ایستا (Static Datasets)، از یادگیری تقویتی (RL) استفاده کردهاند تا دو بخش مجزا را بهطور همزمان بهینه کنند: «اجرای راهکارها» (Solution Rollouts) و «داربست» (Scaffold) که این اجراها را هدایت میکند.
با بهینهسازی این داربست، مدل مسیرهای بهتری را برای حل مسائل کشف میکند. این بدان معناست که مدل صرفاً پاسخ را حدس نمیزند، بلکه بهینهترین راه رسیدن به آن پاسخ را از طریق استدلالهای تکرارشونده (Iterative Reasoning) میآموزد. این مکانیسم باعث میشود مدل در مواجهه با خطاهای احتمالی، مسیر خود را اصلاح کرده و دوباره تلاش کند تا به نتیجه برسد.
خانواده مدلها و انواع نسخهها
مدلهای Ornith-1.0 بر پایه مدلهای بنیادین Gemma 4 و Qwen 3.5 ساخته شدهاند و نقاط قوت این مدلها را به ارث بردهاند، در حالی که لایه عاملمحور (Agentic Layer) به آنها اضافه شده است. DeepReinforce-AI برای ایجاد تعادل بین عملکرد و محدودیتهای سختافزاری، چهار اندازه مختلف ارائه داده است:
- Ornith-1.0-9B: یک مدل متراکم (Dense) برای سیستمهای تک-GPU. این مدل بهگونهای طراحی شده است که روی یک GPU با حافظه ۸۰ گیگابایت جای بگیرد.
- Ornith-1.0-31B: یک گزینه متراکم با اندازه متوسط برای نیازهای میانی.
- Ornith-1.0-35B: مدل ترکیب خبرهها (MoE) — شبیه تیمی از متخصصان که هر سوال به دست متخصص مربوطه سپرده میشود — که برای بهرهوری و سرعت بیشتر طراحی شده است.
- Ornith-1.0-397B: یک مدل عظیم MoE که برای گرههای چند-GPU و با استفاده از موازیسازی تنسور (Tensor Parallelism) طراحی شده است.
برای پشتیبانی از نیازهای مختلف استقرار، چکپوینتها در قالبهای متنوعی عرضه شدهاند. مدل ۹ میلیاردی در قالب bf16 برای تنظیم دقیق (Fine-tuning) و GGUF برای استنتاج محلی در دسترس است. مدلهای MoE (۳۵ و ۳۹۷ میلیاردی) در قالبهای bf16 و FP8 ارائه شدهاند. نسخههای FP8 بهطور خاص طراحی شدهاند تا تقریباً نصف حافظه ویدیویی (VRAM) را در GPUهای سازگار اشغال کنند.
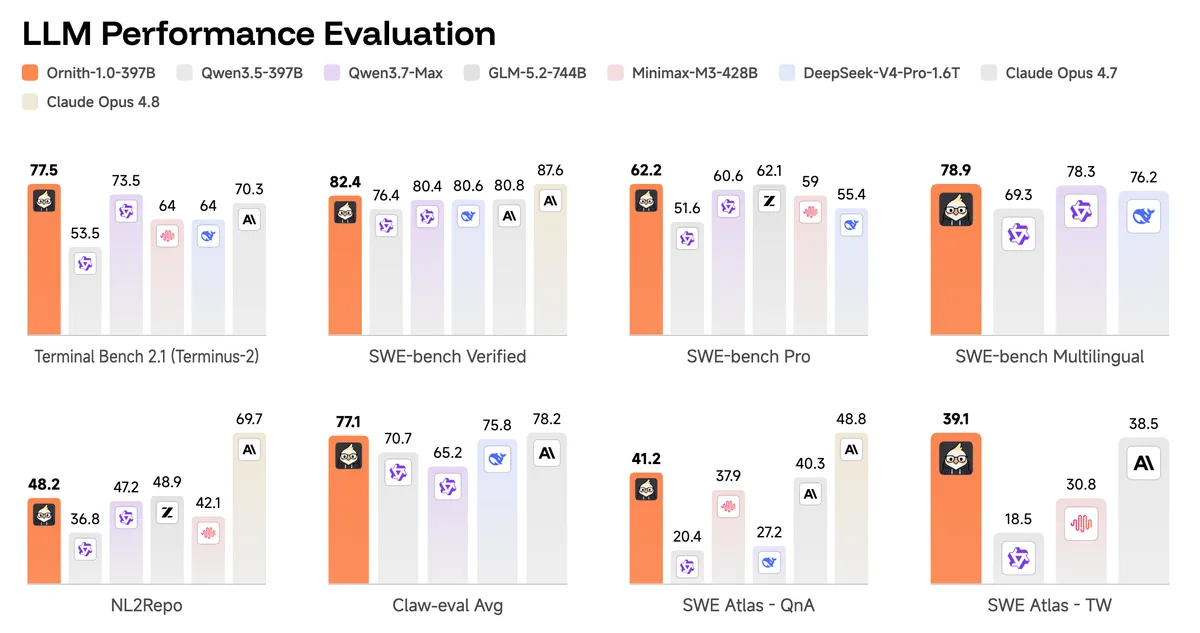
کالبدشکافی عملکرد در بنچمارکها
بر اساس بررسی مستندات گیتهاب، بیشترین پیشرفت در وظایف پیچیده مهندسی نرمافزار مشاهده میشود. هر مدل در برابر مدلهای پایه (Baselines) متناسب با اندازه خود و با استفاده از تنظیمات رمزگشایی (Decoding) یکسان ارزیابی شده است. جزئیات معیارهای عملکردی به شرح زیر است:
- SWE-bench Verified: مدل ۳۹۷ میلیاردی با امتیاز ۸۲.۴٪، بهطور قابلتوجهی از مدل پایه Qwen 3.5-397B (با امتیاز ۷۶.۴٪) و حتی Qwen 3.7-Max (با امتیاز ۸۰.۴٪) پیشی گرفت.
- Terminal-Bench 2.1: در چارچوب Terminus-2، مدل ۳۹۷ میلیاردی به ۷۷.۵٪ رسید (در مقابل ۵۳.۵٪ برای Qwen 3.5-397B). مدل ۳۵ میلیاردی نیز با ۶۴.۲٪ موفق شد امتیاز ۴۱.۴٪ مدل Qwen 3.5-35B را شکست دهد.
- NL2Repo: مدل ۳۹۷ میلیاردی به امتیاز ۴۸.۲٪ دست یافت که نشاندهنده توانایی بالای آن در تبدیل درخواستهای زبان طبیعی به تغییرات در سطح کل مخزن کد است. مدل ۹ میلیاردی نیز با ۲۷.۲٪ در برابر ۱۶.۲٪ مدل Qwen 3.5-9B قرار گرفت.
- Claw-eval: مدل ۳۹۷ میلیاردی با میانگین ۷۷.۱٪، رقبایی مانند GLM-5.2-744B (با ۷۵.۸٪) را پشت سر گذاشت. مدل ۹ میلیاردی نیز میانگین ۶۳.۱٪ را ثبت کرد، در حالی که این رقم برای Qwen 3.5-9B برابر با ۵۳.۲٪ بود.
- SWE Atlas: مدل ۳۹۷ میلیاردی در معیارهای QnA (۴۱.۲٪)، RF (۴۲.۶٪) و TW (۳۹.۱٪) قدرت خود را نشان داد و بهشدت از مدل ۹ میلیاردی (که به ترتیب ۱۷.۹٪، ۱۶.۶٪ و ۱۵.۳٪ کسب کرده بود) برتر بود.
متدولوژی تست و زمینه فنی
برای تضمین دقت، بنچمارکها با پیکربندیهای فنی بسیار خاصی اجرا شدند:
- Terminal-Bench 2.1: ارزیابی از طریق Harbor/Terminus-2 و Claude Code 2.1.126 انجام شد. تنظیمات شامل پنجره متنی (Context Window) ۱۲۸ هزار توکنی، دمای ۱.۰ و مهلت زمانی ۴ ساعته با ۳۲ هسته CPU و ۴۸ گیگابایت RAM بود.
- SWE-bench: از هارنس OpenHands با پنجره متنی ۲۵۶ هزار توکنی، دما ۱.۰ و
top_p۰.۹۵ استفاده شد. - NL2Repo: این تست با یک پنجره متنی عظیم ۴۰۰ هزار توکنی و خروجی ۴۸ هزار توکنی، همراه با فیلترهای ضد-هک (Anti-hacking) انجام گرفت.
- ClawEval: تمرکز این تست بر توزیع وظایف کاربران واقعی با پنجره متنی ۲۵۶ هزار توکنی و دمای ۰.۶ بود.
استدلال و ابزارها
Ornith-1.0 یک مدل استدلالی (Reasoning Model) بومی است. هر پاسخ مدل با یک بلوک <think> آغاز میشود که در آن زنجیره تفکر (Chain-of-Thought) مدل پیش از ارائه کد نهایی یا پاسخ، نمایش داده میشود.
برای کاربردی شدن در محیطهای توسعه، این مدلها از یک رابط سازگار با OpenAI پشتیبانی میکنند. این رابط شامل یک فیلد اختصاصی به نام reasoning_content و یک پارسر فراخوانی ابزار (Tool-call parser) است. این قابلیت به مدل اجازه میدهد تا فراخوانهای تابع (Function Calls) را برای اجرای دستورات شل یا درخواستهای API صادر کند.
استقرار و ادغام محلی
این پروژه تحت مجوز MIT منتشر شده است که دسترسی جهانی را فراهم کرده و آن را از محدودیتهای منطقهای رها میکند. برای استقرار محلی، نسخههای کوانتیزه GGUF برای مدلهای ۹ و ۳۵ میلیاردی ارائه شده که با لاماسیپلاسپلاس (llama.cpp) و اولاما (Ollama) سازگار هستند.
برای سرویسهای در سطح تولید (Production-grade)، مدلها با vLLM (نسخه ۰.۱۹.۱ و بالاتر)، SGLang (نسخه ۰.۵.۹ و بالاتر) و Transformers (نسخه ۵.۸.۱ و بالاتر) سازگارند. مدلهای MoE برای مدیریت مقیاس ۳۹۷ میلیارد پارامتری، نیاز به موازیسازی تنسور در چندین GPU دارند.
پارامترهای نمونهبرداری (Sampling) پیشنهادی برای این مدلها عبارتند از:
- دما (Temperature): ۰.۶ (برای بازتولید نتایج بنچمارک از ۱.۰ استفاده کنید)
- Top_p: ۰.۹۵
- Top_k: ۲۰
ادغام با چارچوبهای عاملمحور
توسعهدهندگان میتوانند این مدلها را با هدایت آنها به یک سرور محلی vLLM یا SGLang از طریق نقطه پایانی /v1/chat/completions در چارچوبهای موجود ادغام کنند. ابزارهای سازگار عبارتند از:
- OpenHands: از طریق LiteLLM و با استفاده از پیشوند
openai/Ornith-1.0. - Hermes Agent: اتصال به هر نقطه پایانی سازگار با OpenAI.
- OpenClaw: بهطور خاص برای وظایف کدنویسی عاملمحور بهینه شده است.
- OpenCode: یک رابط خط فرمان (CLI) کدنویسی که در آن Ornith را میتوان به عنوان یک تامینکننده در فایل
opencode.jsonبا استفاده از بسته npm@ai-sdk/openai-compatibleثبت کرد. - Unsloth Studio: امکان استنتاج سریع محلی یا بارگذاری ۴-بیتی برای تنظیم دقیق (Fine-tuning) را فراهم میکند.
تحلیل: چرخش به سمت کدنویسی «جستجو-محور»
این انتشار نشاندهنده حرکتی از پارادایم «پیشبینی توکن بعدی» به سمت پارادایم «جستجو و تأیید» است. با بهینه کردن داربست (Scaffold)، DeepReinforce-AI در واقع یک نقشه ذهنی از نحوه حل مسائل کدنویسی را به مدل داده است.
برای کاربر نهایی، این به معنای کاهش «توهمات» (Hallucinations) در اصلاحات کد است؛ یعنی کمتر پیش میآید که کدی نوشته شود که در ظاهر درست باشد اما هنگام کامپایل با خطا مواجه شود. توانایی اصلاح مسیر جستجو در طول آموزش، مستقیماً به قابلیت اطمینان بالاتر در زمان استنتاج منجر میشود.
همچنین، این موضوع سد ورود برای هوش مصنوعی عاملمحور «محلی-محور» (Local-First) را کاهش میدهد. با وجود یک مدل ۹ میلیاردی که در SWE-bench از مدلهای بسیار بزرگتر عملکرد بهتری دارد، توسعهدهندگان اکنون میتوانند یک عامل کدنویسی با قابلیت بالا را روی یک تک-GPU حرفهای اجرا کنند، بدون اینکه به APIهای بسته و گرانقیمت وابسته باشند.
محیط توسعه محلی شما در حال تبدیل شدن به یک همکار فعال است، نه فقط یک ویرایشگر متن. برنده واقعی در اینجا جامعه مدلهای باز-وزنی (Open-weights) است که اکنون جایگزینی viable برای Claude Code در اتوماسیون سطح مخزن را در اختیار دارد.
برای شروع، میتوانید نسخه 9B-GGUF را از طریق Ollama فراخوانی کنید یا مدل کامل 397B MoE را روی یک خوشه چند-GPU مستقر نمایید تا قابلیتهای آن را روی کدبیس خاص خود آزمایش کنید.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.



گفتگو