
۵.۱ درصد. این عدد دقیقاً همان جهشی است که صحت بازشناسی متن در مدل سروری پیشین را از PP-OCRv6، جدیدترین خانواده نویسهخوانی نوری (OCR) از PaddleOCR جدا میکند. طبق اعلام این تیم در ۲۲ ژوئن ۲۰۲۶، این بهروزرسانی ثابت میکند که مدلهای تخصصی و سبک هنوز میتوانند در استخراج متنهای ساختاریافته، مدلهای عمومی و حجیم را شکست دهند.
در حالی که مدلهای بینایی-زبانی (VLM) ترند روز هستند، اما برای ورود دادههای حساس به سازمانها، هنوز به مدلهایی نیاز است که دچار توهم (Hallucination) — مثل دوستی که خاطرهای را اشتباه تعریف میکند و با اطمینان میگوید — نشوند و کاراکترها را دقیقاً همانطور که هستند بخوانند. همانطور که در تحلیل قبلی ما دربارهی اهمیت OCR تخصصی در عصر مدلهای چندوجهی اشاره کردیم، PP-OCRv6 دقیقاً روی شکاف میان مدلهای عظیم سروری و نیاز به بهرهوری در دستگاههای لبه (Edge Device) تمرکز کرده است.
زمینه و محدوده کاربرد
PP-OCRv6 برای طیف گستردهای از سناریوهای واقعی طراحی شده است. این مدل قادر است تشخیص و بازشناسی متن را در اسناد اداری، اسکرینشاتها و نمایشگرهای دیجیتال مدیریت کند. همچنین برای برچسبهای صنعتی و متنهای پیچیده در محیطهای واقعی بهطور متساوی مؤثر است.
هدف نهایی، تولید خروجیهای متنی دقیق و ساختاریافته است. این خروجیها برای سامانههای پاییندستی مثل تجزیه اسناد (Document Parsing)، جستوجو، تحلیل دادهها و گردشکارهای عاملمحور (Agentic) حیاتی هستند. با کوچک نگه داشتن مدلها، استقرار آنها روی سختافزارهای مختلف منعطف میشود.
بر اساس گزارش huggingface.co، این خانواده مدل برای تطبیق با محدودیتهای سختافزاری به سه سطح تقسیم شده است:
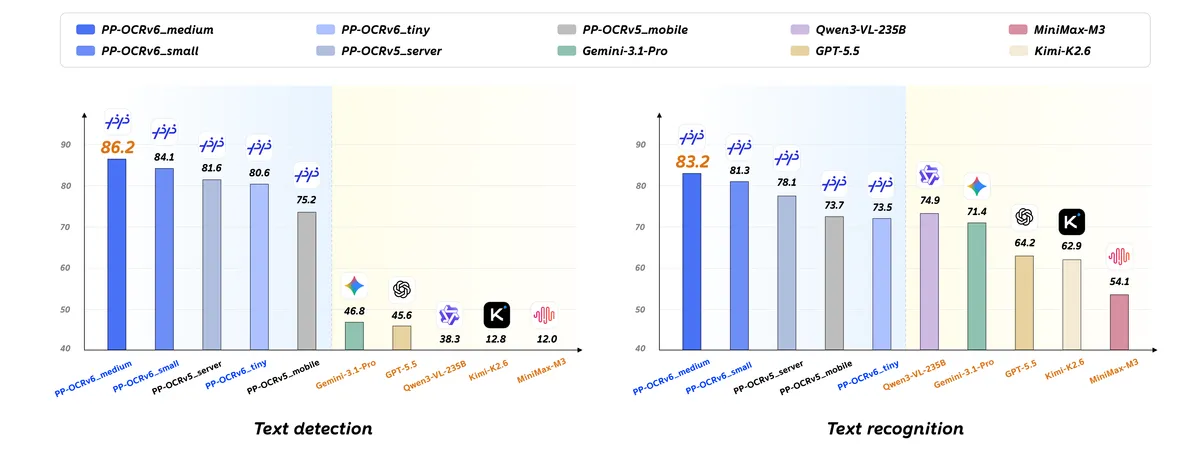
- PP-OCRv6_tiny: دارای ۱.۵ میلیون پارامتر (Parameters)، با صحت تشخیص ۸۰.۶٪ (Hmean) و صحت بازشناسی ۷۳.۵٪. این مدل مخصوص دستگاههای لبه و دموهای حساس به تأخیر ساخته شده است.
- PP-OCRv6_small: دارای ۷.۷ میلیون پارامتر، با صحت تشخیص ۸۴.۱٪ (Hmean) و بازشناسی ۸۱.۳٪. گزینهای ایدهآل برای موبایل و سرویسهای چندزبانه متوازن.
- PP-OCRv6_medium: دارای ۳۴.۵ میلیون پارامتر، با صحت تشخیص ۸۶.۲٪ (Hmean) و بازشناسی ۸۳.۲٪. ساختهشده برای خط لولههای سروری و OCR صنعتی.
جزئیات فنی
در لایه فنی، PP-OCRv6 چندین بهبود معماری را در مراحل تشخیص و بازشناسی معرفی کرده است:
- PPLCNetV4 Backbone: به عنوان ستون فقرات یکپارچه برای هر دو مرحله تشخیص و بازشناسی عمل میکند تا ثبات عملکرد در هر سه سطح (tiny, small, medium) تضمین شود.
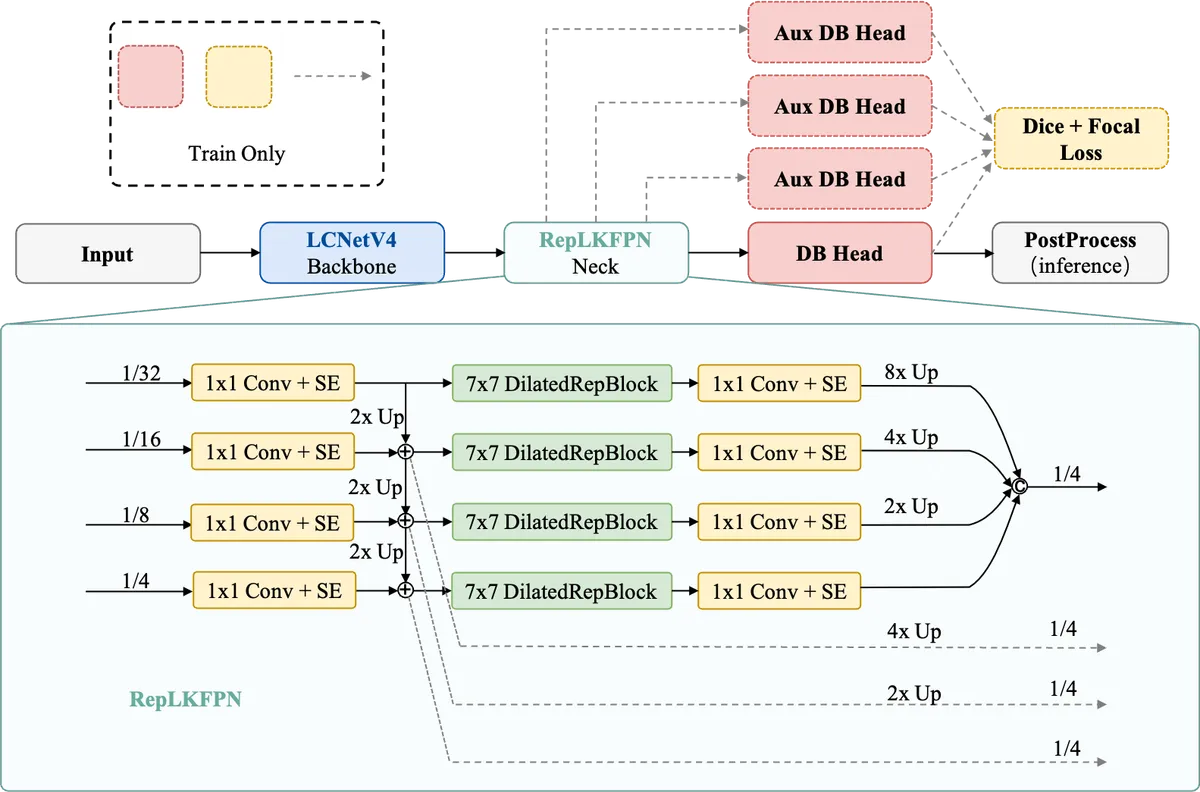
- RepLKFPN برای تشخیص: این یک شبکه هرم ویژگی با هسته بزرگ و سبک (Lightweight Large-Kernel FPN) است. از آنجا که برشهای (Crop) نامناسب منجر به بازشناسی غلط میشوند، کیفیت تشخیص حیاتی است. RepLKFPN متنهای کوچک، متراکم، چرخیده یا کمکیفیت را مدیریت میکند.
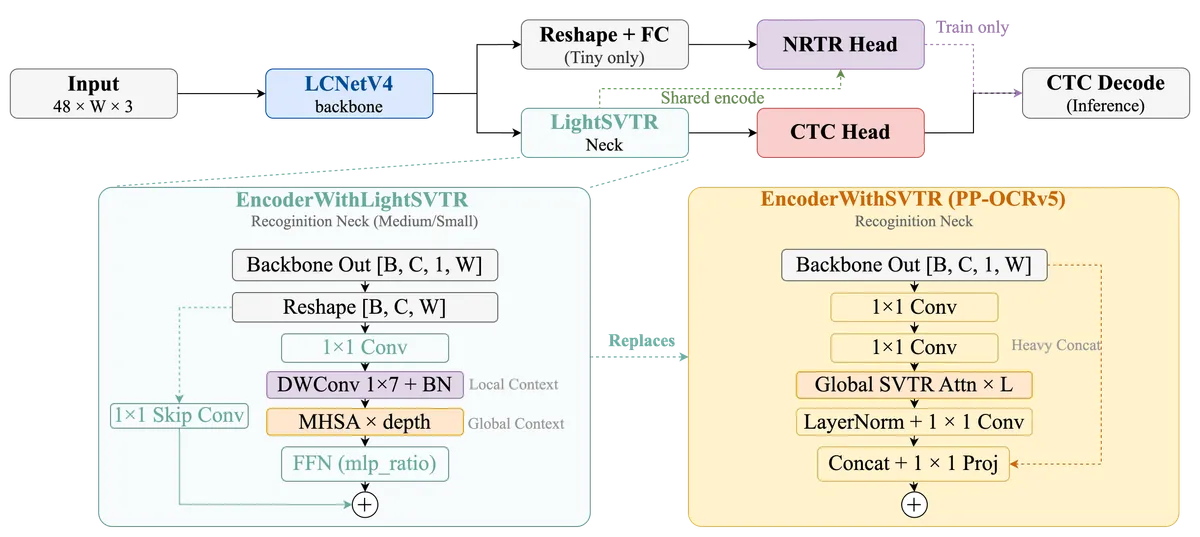
- EncoderWithLightSVTR برای بازشناسی: این ماژول مدلسازی بستر محلی را با توجه (Attention) جهانی ترکیب میکند. این بخش بهطور خاص برای ارتقای کیفیت در برشهای متنی دشوار، مانند متنهای چندزبانه، کاراکترهای صنعتی و نواحی نویزی تصویر طراحی شده است.

بازشناسی متن توسط EncoderWithLightSVTR مدیریت میشود که بستر محلی را با توجه جهانی میآمیزد. این سازوکار دقیقاً نواحی «نویزی» تصویر، مثل برچسبهای صنعتی یا نمادهای خاص را هدف میگیرد؛ جاهایی که OCRهای استاندارد معمولاً شکست میخورند.
پشتیبانی چندزبانه
پشتیبانی چندزبانه یکپارچه در سطوح متوسط و کوچک، ویژگی کلیدی این نسخه است. یک خانواده مدل بهتنهایی از ۵۰ زبان پشتیبانی میکند. این لیست شامل موارد زیر است:
- چینی سادهشده (Simplified Chinese)
- چینی سنتی (Traditional Chinese)
- انگلیسی
- ژاپنی
- ۴۶ زبان با الفبای لاتین
این یکپارچگی نیاز توسعهدهندگان به استقرار مدلهای جداگانه برای هر زبان در یک خط لوله (Pipeline) واحد را حذف میکند.
استقرار و یکپارچهسازی
انعطاف در استقرار، ستون اصلی این வெளியه است. کاربران میتوانند از طریق رابط یکپارچه موتور استنتاج (Inference) — لحظهای که مدل واقعاً جواب تولید میکند، شبیه خودِ آشپزی و نه دوره آموزش آن — در نسخه ۳.۷ PaddleOCR، از سه بکاند متفاوت استفاده کنند:
۱. Paddle Inference: فرمت بومی Paddle برای دستیابی به بالاترین کارایی.
۲. Transformers: مسیری سازگار با Hugging Face و PyTorch که از طریق تنظیم engine="transformers" برای مدلهای پشتیبانیشده فعال میشود.
۳. ONNX Runtime: مسیری قابلحمل برای محیطهای استقرار مبتنی بر ONNX با استفاده از تنظیم engine="onnxruntime".
توسعهدهندگان میتوانند با دستور pip install paddleocr سریعاً شروع کنند. بکاند پیشفرض، Paddle Inference با مدل PP-OCRv6_medium است. خروجیها را میتوان به صورت تصاویر بصری یا JSONهای ساختاریافته دریافت کرد که برای خط لولههای تولید بازیابیافزا (RAG) — مثل دانشآموزی که قبل از جواب دادن، اول کتاب درسی را باز میکند و از آن نقل میآورد — ضروری هستند.
این ساختار مدولار به معنای آن است که توسعهدهندگان دیگر مجبور نیستند بین دقت و سرعت استقرار یکی را انتخاب کنند. با ارائه یک مدل یکپارچه ۵۰ زبانه، PaddleOCR بار عملیاتی نگهداری مدلهای مجزا برای مناطق مختلف را کاهش میدهد.
برای کاربر نهایی، این تغییر به معنای تجزیه سریعتر اسناد و خط لولههای RAG قابلاتکاتر است. وقتی مدلی با این دقت، تا این حد کوچک باشد، هزینه پردازش میلیونها صفحه در مقایسه با استفاده از یک VLM عظیم، بهشدت کاهش مییابد.
توسعهدهندگان اکنون باید دمو آنلاین PP-OCRv6 را برای محک زدن انواع اسناد خود در برابر سه سطح موجود آزمایش کنند.
گام بعدی شما
- دمو آنلاین PP-OCRv6 را برای محک زدن انواع اسناد خود در سه سطح مختلف آزمایش کنید.
- اگر از مدلهای VLM برای استخراج متن استفاده میکنید، هزینه استنتاج خود را با جایگزینی بخش OCR با این مدلهای سبک مقایسه کنید.
- برای استقرار در محیطهای موبایل، نسخه
smallرا به عنوان نقطه شروع بررسی کنید.
اما داستان بهینهسازی حافظه در این مدلها حتی جذابتر است — به بررسی ما درباره تکنیکهای کوانتش وزنها در مدلهای کوچک مراجعه کنید.



گفتگو