
اگر قصد دارید بدون وابستگی به سرورهای ابری، یک مدل استدلالی قدرتمند روی لپتاپ خود داشته باشید، Qwen 3.6 27B دقیقاً همان قطعهی گمشده است. این مدل ثابت میکند که برای رسیدن به نتایج حرفهای در کدنویسی، دیگر نیازی نیست لزوماً سختافزارهای صنعتی و گرانقیمت داشته باشید.
بسیاری از مدلهای محلی برای افزایش سرعت، کیفیت را بیش از حد فدا میکنند، اما Qwen 3.6 27B به تعادلی نادر در دنیای هوش مصنوعی محلی رسیده است. این مدل متراکم (Dense) در استدلالهای پیچیده و کدنویسی بسیار فراتر از اندازه-اش عمل میکند و هوشمندی عمومیای را ارائه میدهد که توسعهی نرمافزار حرفهای روی یک ماشین شخصی را واقعاً عملی و ممکن میسازد.
اجرای مدلهای با پارامتر بالا بهصورت محلی همیشه یک قمار بین سختافزار سنگین و خروجیهای ناامیدکننده بود. اکثر کاربران به APIهای ابری متکی بودند زیرا جایگزینهای محلی فاقد آن «حس» واقعی از یک هوشمندی جامع بودند. اما بر اساس مستندات منتشرشده در ۲۹ ژوئن ۲۰۲۶، عرضه Qwen 3.6 این معادله را تغییر داده و نتایجی باکیفیت و واکنشگرا را تنها با یک پرامپت فراهم میکند.
مدل زبانی بزرگ (LLM) — مثل کتابخانهداری که میلیاردها صفحه را خوانده و حالا با همان لحن کتابها جواب میدهد — در این نسخه به شکلی بهینه شده که روی سختافزارهای خانگی بنشیند.
تجربه سختافزاری
اجرای این مدل از نظر محاسباتی بسیار متمرکز و سنگین است. از نظر فیزیکی، سیستم «داغ» میشود. در یک مورد گزارششده، شدت حرارت بهقدری بود که کاربر احساس کرد زانوهایش در حال ذوب شدن هستند و برای ثبت این پیکهای دمایی شدید، مجبور شد از یک دوربین حرارتی متصل به گوشی استفاده کند.

با این حال، عملکرد بهدست آمده بسیار قابل توجه است. طبق آزمایشهای کاربران، روی یک Macbook Max M5 با ۱۲۸ گیگابایت رم، مدل با استفاده از لاماسـیپلاسپلاس (llama.cpp) به سرعت تقریبی ۳۰ توکن در ثانیه میرسد. برای دارندگان پردازندههای گرافیکی Nvidia RTX 5090، عملکرد حتی چشمگیرتر است؛ یک کاربر گزارش داده که با پنجره متنی (Context Window) ۱۲۳ هزار توکنی، با استفاده از کوانتش Q6_K و تنظیمات Q4_0 KV در محیط LM Studio، به سرعت ثابت ۵۰ توکن بر ثانیه رسیده است، در حالی که تقریباً ۲۸ گیگابایت از ۳۲ گیگابایت VRAM را مصرف کرده است.
قابلیتها و محکها
مدل Qwen 3.6 در دو نسخه اصلی عرضه شده است: یک نسخه مبتنی بر ترکیب خبرهها (Mixture-of-Experts یا MoE) با نام Qwen 3.6 35B A3B و یک نسخه متراکم Qwen 3.6 27B. اگرچه نسخه MoE سریعتر است (تقریباً ۳ برابر سریعتر)، اما مدل متراکم ۲۷B برای دستورات پیچیده، قدرتمندتر و قابلاعتمادتر است. این نسخه برای کسانی که کیفیت خروجی را به سرعت خام تولید توکن ترجیح میدهند، توصیه میشود.
سایمون ویلیسون برای ارزیابی اولیه و تست سلامت (Smoke Test) هر دو نسخه ۳۵B و ۲۷B از سناریوی «پنگوئنهای روی دوچرخه» استفاده کرده است. در ارزیابیهای پیچیدهتر، نتایج زیر برجستهاند:
- نوشتار محدود: این مدل درخواستهای بسیار خاص و نیچ (Niche) را به خوبی مدیریت میکند. برای مثال، نوشتن یک شعر ۸ خطی که رقص زوک (Zouk) را با فیزیک کوانتوم ترکیب کند، با تأمل منطقی درباره اصطلاحات کوانتومی و رعایت دقیق قافیهها اجرا شد.
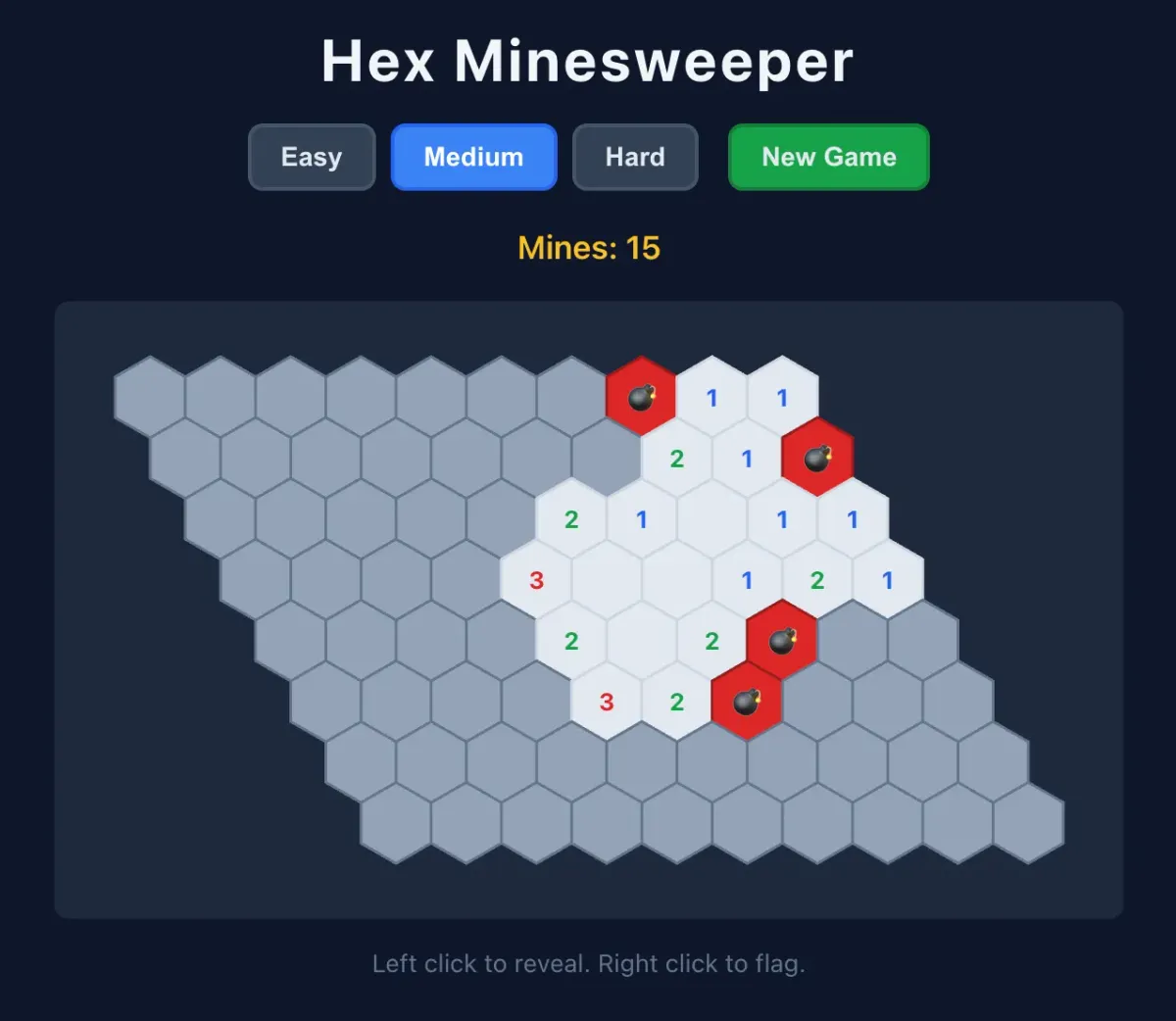
- دقت در کدنویسی: در آزمونی با استفاده از OpenCode، این مدل توانست در اولین تلاش یک بازی مینروبہ ششضلعی را با استفاده از pnpm بسازد. تفاوت چشمگیر اینجا بود: نسخه MoE دستورات مربوط به بستهبندی (Package) را نادیده گرفت و تمام کدها را در یک فایل HTML ریخت، اما مدل ۲۷B الزامات معماری را بهطور کامل رعایت کرد و یک بسته Node استاندارد و صحیح ارائه داد.
- کارهای عمومی: مدل برای کارهای کاربردی بسیار واکنشگرا و مفید است. در تستی که توسط ماچیه سیلتسکی در AI Tinkerers ورشو ارائه شد، این مدل توانست تنها با یک پرامپت کوتاه، یک صفحه فرود (Landing Page) عملیاتی برای یک فروشگاه شمع تولید کند. اگرچه این نتیجه در مقایسه با پیشرفتهترین مدلهای پیشرو (Frontier Models) خارقالعاده نیست، اما در حال حاضر یک ابزار کاربردی و عملی است.
استراتژی استقرار محلی
بهترین مسیر برای اجرای این مدل، استفاده از llama.cpp است؛ ابزاری مستقیم و بازمتن که روی دستگاههای مختلف کار میکند. این ابزار بهویژه به دلایل اخلاقی بر Ollama ترجیح داده میشود. کاربران باید برای کاهش اندازه مدل، نسخههای کوانتیده را از Hugging Face (توسط ارائهدهندگانی مثل unsloth یا bartowski) دریافت کنند.
در حالی که مدلهای پیشفرض از دقت BF16 استفاده میکنند، کوانتش ۸-بیتی فضای حافظه را نصف میکند بدون اینکه هزینه یا افت کیفیتی محسوب شود. کوانتشهای پایینتر منجر به مدلهای کوچکتر و سریعتر میشوند، اما این بار افت کیفیت بهطور محسوسیe مشاهده میشود.
برای مدل unsloth/Qwen3.6-27B-MTP-GGUF:Q8_0 که از قابلیت پیشبینی چند توکنی (multi-token prediction) پشتیبانی میکند، دستور سرور به شرح زیر است:llama-server -hf unsloth/Qwen3.6-27B-MTP-GGUF:Q8_0 \ --spec-type draft-mtp -ngl 999 -fa on -c 65536 --jinja --port 8080
تجزیه دقیق دستورات:
-hf: مدل را مستقیماً از Hugging Face میگیرد (یا میتوان از-m ~/models/Qwen3.6-27B-Q8_0.ggufبرای فایلهای محلی استفاده کرد).draft-mtp: از یک مدل سریع برای پیشبینی توکنهای بعدی جهت افزایش سرعت استنتاج استفاده میکند.-ngl 999: تمام لایههای مدل را به GPU منتقل میکند.-fa on: قابلیت توجه برقآسا (flash attention) را فعال میکند.-c 65536: پنجره متنی را روی ۶۴ هزار توکن تنظیم میکند (هرچند ظرفیت بومی مدل ۲۵۶ هزار توکن است).--jinja: پشتیبانی از فراخوانی ابزار (Tool Calling) را فعال میکند.--port 8080: پورت را برای ثبات پیکربندی تثبیت میکند.
برای کسانی که محیط ترمینال را به رابط کاربر گرافیکی در http://127.0.0.1:8080 ترجیح میدهند، ابزار llama-cli جایگزین مناسبی است. این سرور همچنین میتواند با عاملهایی مثل OpenCode، Pi یا Hermes یکپارچه شود. در مورد OpenCode، این کار مستلزم افزودن baseURL محلی (http://127.0.0.1:8080/v1) به فایل تنظیمات opencode.jsonc است.
تحلیل مقایسهای
به نقل از دادههای Artificial Analysis، مدل Qwen 3.6 27B بهطور مداوم از گزینههای محلی محبوب دیگر مثل Gemma 4 31B که بسیاری آن را پیشفرض کدنویسی محلی میدانند، پیشی میگیرد. اگرچه DeepSeek V4 Flash (با نام DwarfStar4) ممکن است در پروژههایی با جایگاه متنی بسیار بلند برتری داشته باشد، اما Qwen 3.6 27B در کوانتشهای استاندارد برابر یا بهتر است (لازم به ذکر است که DwarfStar4 از کوانتشهای تهاجمیتر ۲ تا ۴ بیتی استفاده میکند).
در تستهای عملکردی روی Macbook Max M5، ابزار llama.cpp سریعتر از mlx-lm عمل کرد و با بهرهگیری از ۹۵ درصد از GPU، منابع موجود را بهطور بهینه مدیریت کرد.
عصر حاکمیت محاسباتی
این تحول به معنای حرکت به سمت «حاکمیت محاسباتی» است. وقتی مدلهای انحصاری مثل Claude Fable 5 ناگهان حذف یا قیمتگذاریشان تغییر کند، وزنهای باز (Open Weights) — که شبیه داشتن دستور پخت غذا بهجای خرید غذای آماده است — به یک دارایی دائمی و خصوصی تبدیل میشوند. مدلهای پیشرو فعلی اغلب با یارانهی مالی انبوه اجرا میشوند، جایی که یک هزینه ۱۰۰ دلاری ماهانه، توکنهایی به ارزش هزاران دلار فراهم میکند؛ مزیتی که کاربران باید تا زمانی که هست از آن بهره ببرند.
مدلهای محلی مزایای حیاتی ارائه میدهند:
- تنظیم دقیق (Fine-tuning): آنها میتوانند برای نیازهای خاص یک سازمان شخصیسازی شوند (مثل تخصص دادن به یک پزشک عمومی).
- امنیت: کسبوکارها میتوانند دادههای حساس یا اختصاصی خود را بهصورت محلی پردازش کنند.
- حریم خصوصی: کاربران میتوانند دادههای پزشکی یا اسرارهای عمیق شخصی را بدون به اشتراک گذاشتن با ارائهدهندگان ابری آمریکایی یا چینی مدیریت کنند.
با عرضه مدلهای سطح پیشروی بازمتن مثل GLM 5.2، وارد عصر جدیدی شدیم. هرچند GLM 5.2 بهجای یک کارت RTX 5090 یا یک مکبوک، بودجهای در سطح یک شرکت میطلبد، اما ثابت میکند که هوشمندی سطح پیشرو در حال تبدیل شدن به چیزی قابلمدیریت در محیطهای محلی است.
در آینده، احتمالاً هوشمندی خالص از دانش واقعی تفکیک خواهد شد. با برونسپاری دانش به مکانیزمهای فراخوانی ابزار، ممکن است مدلهایی هوشمندتر از استانداردهای فعلی را ببینیم که روی دستگاههای محلی، از جمله گوشیهای هوشمند، اجرا میشوند. اگر اکنون هزینه توکنهای ابری را میپردازید، زمان آن رسیده است که پیشبینی چند توکنی (MTP) را امتحان کنید تا ببینید سختافزار شما برای انتقال به یک پشتهی AI کاملاً مستقل آماده است یا خیر.
گام بعدی شما
- اگر کاربر Mac M-series هستید، مدل Q8_0 را از طریق llama.cpp تست کنید تا تفاوت سرعت استنتاج را حس کنید.
- توسعهدهندگان کدنویسی، این مدل را در OpenCode جایگزین Gemma 4 کنند تا دقت معماری پروژه را بسنجند.
- برای کاهش مصرف VRAM بدون افت کیفیت، از کوانتشهای ۸-بیتی به جای BF16 استفاده کنید.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.



گفتگو