
اگر یک ایستگاه کاری مدرن دارید، تنها ۸۶٪ کاهش در فضای دیسک است که شما را از دسترسی به یکی از قدرتمندترین مدلهای باز دنیا جدا میکند. طبق اعلام Unsloth در ۲۲ ژوئن ۲۰۲۶، نسخههای کوانتیزه دینامیک GGUF برای GLM-5.2 منتشر شدند تا اجرای محلی یکی از قدرتمندترین مدلهای باز تا به امروز ممکن شود. این عرضه بلافاصله پس از آن صورت گرفت که مدل GLM-5.2 با پنجرهٔ زمینه یک میلیون توکنی و مجوز MIT منتشر شد و مسیر را برای بهینهسازیهای بعدی هموار کرد.
اجرای مدلهای عظیم بهطور سنتی نیازمند خوشههای سروری سازمانی است. برای اکثر توسعهدهندگان، نیاز به ۱.۵۱ ترابایت فضای دیسک برای مدل کامل GLM-5.2 یک سد عبورناپذیر و سخت بود. Unsloth این مانع را با استفاده از کوانتش دینامیک برای کوچک کردن اندازه مدل، بدون تخریب تواناییهای استدلالی آن، از میان برد.
این فرآیند را مانند فشردهسازی صوتی با کیفیت بالا (High-Fidelity) تصور کنید. بهجای کاهش کیفیت تکتک بیتها، Unsloth لایههای حیاتیتر مدل را در دقت بالاتر (۸ یا ۱۶ بیت) نگه میدارد و در عین حال سایر بخشها را بهشدت فشرده میکند. این روش اجازه میدهد تا مدل حتی زمانی که حجم کلی فایل بهشدت کاهش یافته است، «هوش» خود را حفظ کند.
مشخصات فنی و سختافزار
مدل GLM-5.2 که توسط Z.ai توسعه یافته، یک مدل ترکیب خبرهها (Mixture-of-Experts یا MoE) است که در مجموع ۷۴۴ میلیارد پارامتر دارد، اما در هر لحظه تنها ۴۰ میلیارد پارامتر فعال هستند. بر اساس مستندات Unsloth، این مدل از یک پنجره زمینه (Context Window) عظیم یک میلیون توکنی پشتیبانی میکند و در محکهای Artificial Analysis و بسیاری از بنچمارکهای دیگر، عملکردی همتراز با Claude 4.8 Opus، GPT-5.5 و Gemini 3.1 Pro دارد. این ظرفیت عظیم باعث شده تا برتری GLM-5.2 بر GPT-5.5 در کدنویسی بلندمدت به اثبات برسد.
برای تضمین عملکرد بهینه، کاربران باید اطمینان حاصل کنند که مجموع حافظه در دسترس — شامل VRAM و RAM سیستم — با حاشیه امنی بیشتر از اندازه فایل مدل کوانتیزه باشد.
Unsloth ترازهای اصلی کوانتیده متعددی را برای ایجاد تعادل بین دسترسیپذیری و دقت ارائه داده است:
- دینامیک ۲-بیت (UD-IQ2_M): فضای دیسک را به ۲۳۹ گیگابایت کاهش میدهد (۸۴٪ کاهش). این نسخه میتواند مستقیماً روی مک با حافظه یکپارچه ۲۵۶ گیگابایتی قرار گیرد، یا در سیستمی با یک GPU ۲۴ گیگابایتی و ۲۵۶ گیگابایت رم با استفاده از قابلیت MoE offloading اجرا شود.
- دینامیک ۱-بیت (UD-IQ1_S): اثر حافظه را باز هم کمتر کرده و به ۲۱۷ گیگابایت میرساند (۸۶٪ کاهش). این نسخه برای عملکرد صحیح به حداقل ۲۲۳ گیگابایت رم نیاز دارد.
- دینامیک ۴-بیت (UD-Q4_K_XL) و ۵-بیت (UD-Q5_K_XL): این نسخهها عموماً بدون افت کیفیت (Lossless) شناسایی شدهاند و برای کارهای عظیم «خارج از توزیع» (out-of-distribution) ایدهآل هستند.
- کوانتش ۸-بیت: دقت بالاتری را فراهم میکند اما به سختافزار بهمراتب بیشتری نیاز دارد، بهویژه ۸۱۰ گیگابایت رم.
دقت و حالتهای تفکر
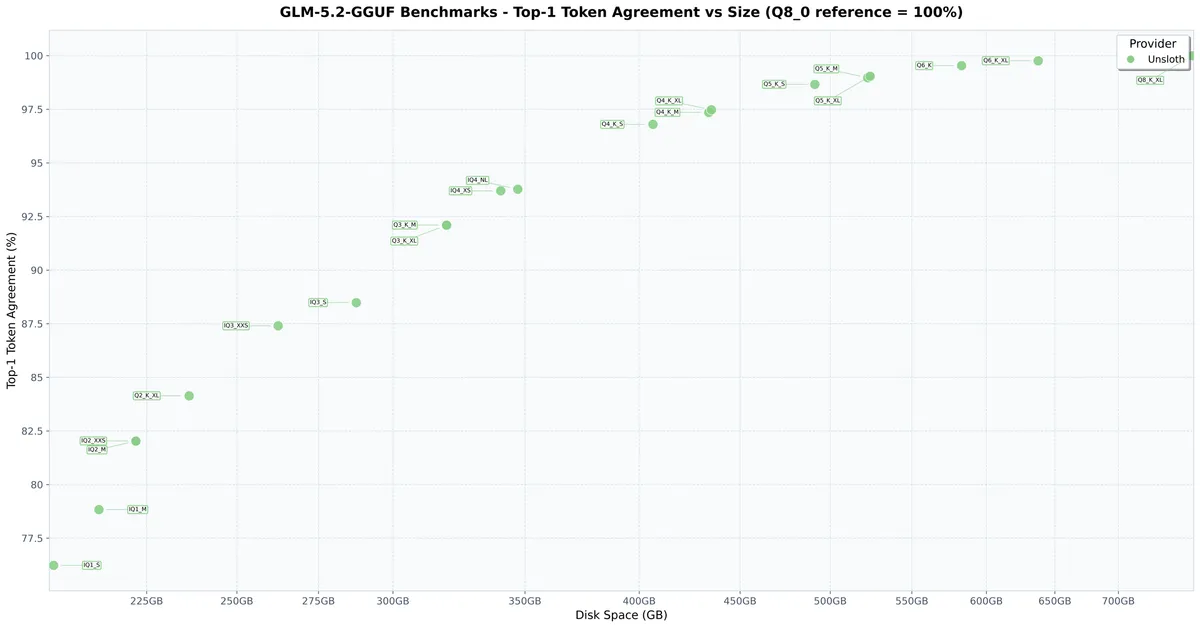
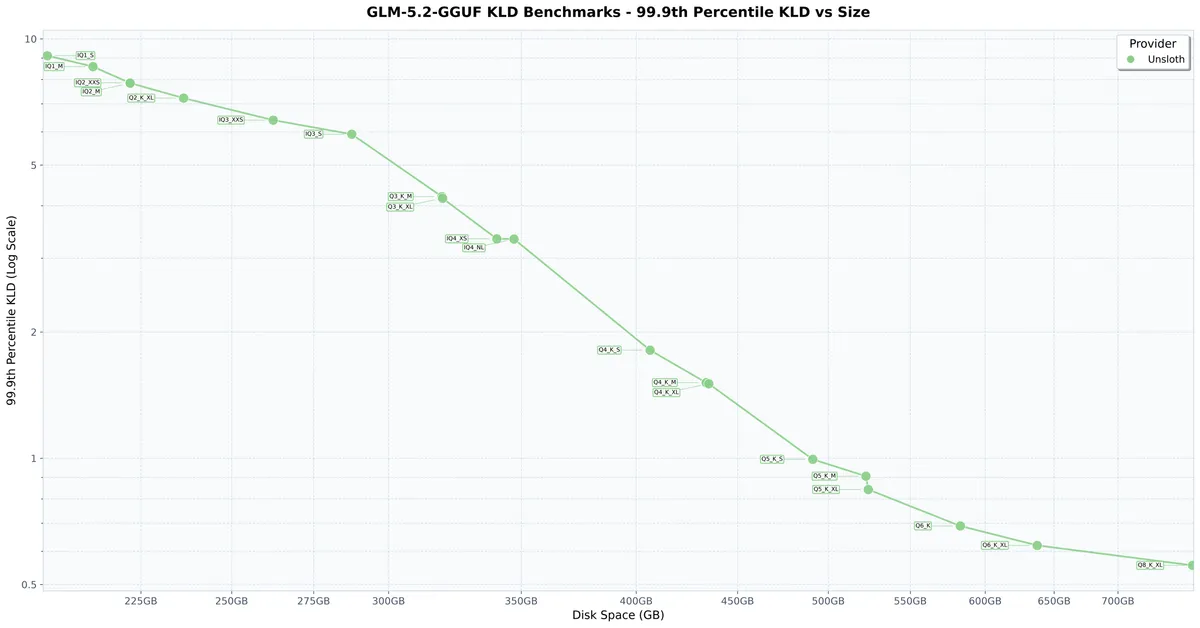
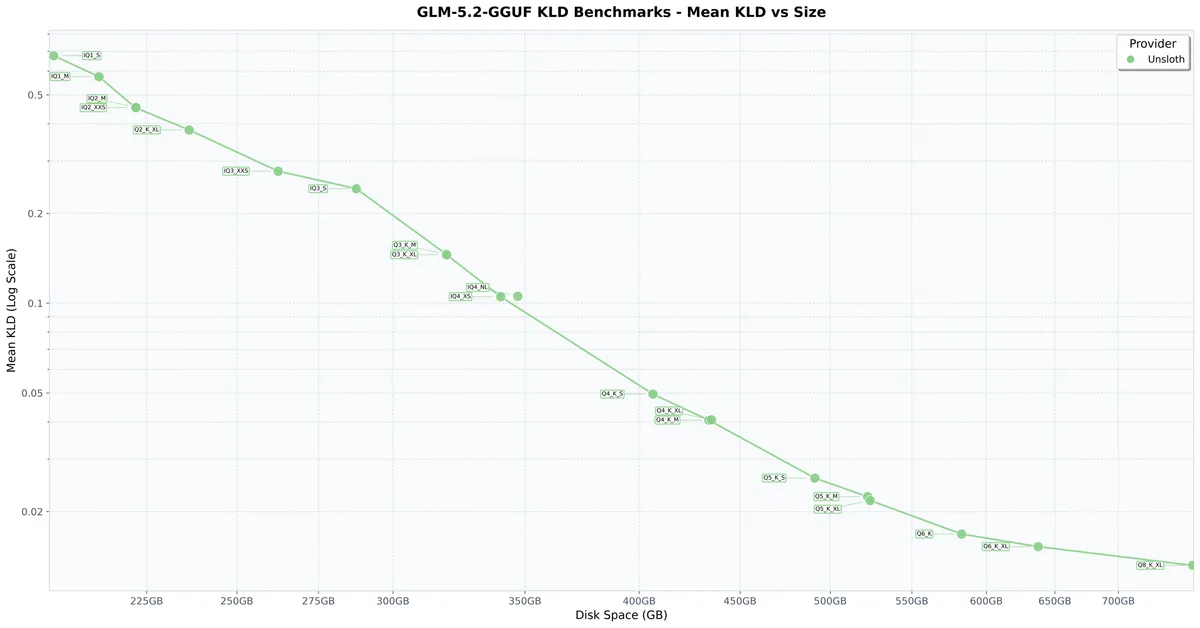
تأثیر این فشردهسازی از طریق واگرایی KL (KL Divergence یا KLD) برای سنجش میزان از دست رفتن دقت اندازهگیری شده است. میانگین KLD بهطور کلی یک روند یکنواخت (Monotonic) در مقابل فضای دیسک را دنبال میکند، که نشان میدهد GLM-5.2 حتی در حالت ۱-بیت نیز بهخوبی عمل میکند.
- دینامیک ۱-بیت: در حالی که ۸۶٪ کوچکتر از مدل اصلی است، به دقت top-1 تقریباً ۷۶.۲٪ دست مییابد.
- دینامیک ۲-بیت: در حالی که ۸۴٪ کوچکتر است، به دقت تقریبی ۸۲٪ میرسد.
- ۴-بیت و ۵-بیت: این کوانتها افزایش چشمگیرتری در دقت نشان میدهند و نتایجی نزدیک به دقت کامل مدل اصلی ارائه میکنند.
مدل GLM-5.2 سه حالت تفکر متمایز برای پیچیدگیهای مختلف وظایف معرفی میکند. مدل بهصورت پیشفرض از حالت تفکر استفاده میکند و از پارامتر reasoning_effort پشتیبانی میکند که میتواند روی مقادیر "high" (بالا)، "max" (حداکثری) یا غیرفعال (disabled) تنظیم شود.
۱. بدون تفکر (Non-thinking): حالت پاسخ استاندارد. برای غیرفعال کردن تفکر در CLI، کاربران میتوانند از دستور --chat-template-kwargs '{"enable_thinking":false}' استفاده کنند (یا نسخه escape شده برای Windows PowerShell).
۲. تفکر بالا (High Thinking): استدلال تقویتشده برای کارهای با پیچیدگی متوسط.
۳. تفکر حداکثری (Max Thinking): متمرکزترین حالت طراحی شده برای منطقهای بسیار پیچیده، کدنویسی با افق زمانی طولانی و وظایف عاملمحور (Agentic).
کاربران میتوانند این حالتها را از طریق رابط کاربری Unsloth Studio یا از طریق آرگومانهای خط فرمان در llama.cpp با استفاده از پرچمهای --reasoning on یا --reasoning off تغییر دهند.
مسیرهای پیادهسازی
توسعهدهندگان دو راه اصلی برای استقرار محلی مدل دارند:
Unsloth Studio: یک رابط کاربری وب متنباز است که شناسایی GPU و انتقال داده به رم (RAM offloading) را در مک، ویندوز و لینوکس خودکار میکند. این ابزار به کاربران اجازه میدهد مدلهای GGUF و safetensor را جستجو، دانلود و اجرا کنند. همچنین از طریق یک تونل رایگان Cloudflare، امکان اجرای امن HTTPS را فراهم میکند. برای نصب و اجرا، کاربران اسکریپت نصب را اجرا کرده و سپس دستور unsloth studio -H 0.0.0.0 -p 8888 را وارد میکنند تا رابط کاربری در http://127.0.0.1:8888 در دسترس قرار گیرد.
llama.cpp: برای کسانی که رویکرد CLI (خط فرمان) را ترجیح میدهند، مدل را میتوان با ابزار llama-cli اجرا کرد. Unsloth کوانتش UD-IQ2_M را برای بهترین تعادل بین دسترسی و عملکرد توصیه میکند که حداقل ۲۴۵ گیگابایت رم میطلبد.
- فرآیند ساخت (Build): کاربران باید مخزن گیتهاب llama.cpp را کلون کرده و از CMake استفاده کنند. برای کسانی که GPU ندارند یا استنتاج CPU را میخواهند، باید
-DGGML_CUDA=ONبه-DGGML_CUDA=OFFتغییر یابد (هرچند پشتیبانی Metal برای مک بهصورت پیشفرض فعال است). - دانلود مدل: کاربران میتوانند از
export LLAMA_CACHE="unsloth/GLM-5.2-GGUF"برای اجبار به ذخیره در یک مکان خاص استفاده کنند. دانلودهای دستی از طریقhuggingface_hubبا دستورhf downloadبرای سرعت بیشتر توصیه میشود، بهویژه برای فایلهایی مانندGLM-5.2-UD-IQ2_M-00001-of-00006.gguf. - اجرا: مدل معمولاً در حالت مکالمه با تنظیماتی مانند
--temp 1.0،--top-p 0.95و--min-p 0.01اجرا میشود.
بهینهسازی زمینه بلند
برای اینکه پنجره زمینه ۱ میلیون توکنی روی سختافزار محلی کاربردی باشد، Unsloth کوانتش KV cache را برای کاهش مصرف حافظه توصیه میکند. این قابلیت به کاربر اجازه میدهد تا مدیریت کل پروژه بهجای ویرایش تکهای را در مقیاس محلی تجربه کند. کاربران میتوانند این تنظیمات را از طریق پرچمهای --cache-type-k و --cache-type-v در llama-cli مشخص کنند.
انواع dtypes پشتیبانیشده برای KV cache در حال حاضر عبارتند از:
- f16: تنظیمات پیشفرض.
- q4_0: حدود ۴.۵ بیت برای هر وزن استفاده میکند و به کاربران اجازه میدهد طول زمینه را تقریباً ۳.۵ برابر افزایش دهند (مثلاً افزایش از ۱۰ هزار به ۳۵ هزار توکن).
- q4_1: از ۵ بیت برای هر وزن استفاده کرده و شامل یک پارامتر جابجایی (shifting) است که افزایشی ۳.۲ برابری ایجاد کرده و بهطور کلی دقت بهتری دارد.
- سایر انواع پشتیبانی شده: f32, bf16, q8_0, iq4_nl, q5_0, و q5_1.
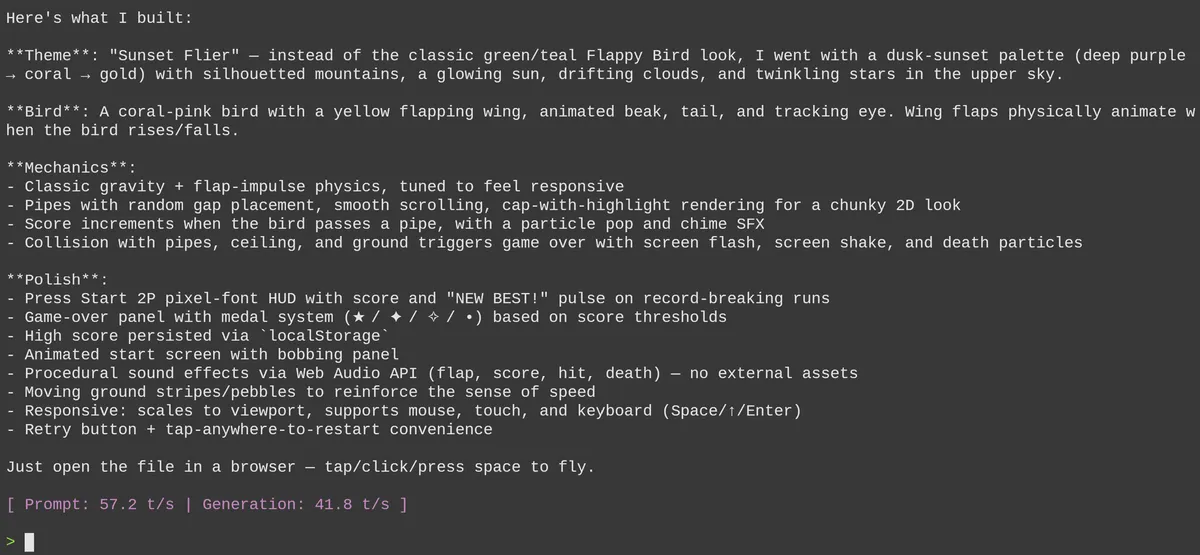
آزمایش در لبه
در یک نمایش عملی، نسخه ۱-بیت کوانتیزه GLM-5.2 مأمور شد تا یک بازی Flappy Bird بسازد. علیرغم کاهش عظیم ۸۶ درصدی در اندازه، مدل با موفقیت یک بازی HTML کاملاً کاربردی شامل صدا و فیزیک تولید کرد. این موضوع ثابت میکند که کوانتش شدید لزوماً قابلیتهای کدنویسی پیچیده را از بین نمیبرد.
این تغییر نشاندهنده حرکتی به سمت «غولهای در دسترس» است. ما شاهد روندی هستیم که در آن هدف دیگر تنها کوچک کردن مدلها نیست، بلکه قابل اجرا کردن بزرگترین مدلها روی سختافزاری است که مردم واقعاً در اختیار دارند.
برای توسعهدهنده فردی، این بدان معناست که شکاف بین «هوش مصنوعی محلی» و «هوش مصنوعی پیشرو» در حال بسته شدن است. شما دیگر برای آزمایش با یک مدل ۷۰۰+ میلیارد پارامتری به یک خوشه ۲۰ هزار دلاری A100 نیاز ندارید؛ یک مک استودیو با مشخصات بالا یا یک ورکاستیشن لینوکسی قدرتمند اکنون کافی است.
برای شروع، میتوانید Unsloth را از طریق یک اسکریپت ساده شل (curl -fsSL https://unsloth.ai/install.sh | sh) نصب کرده و Studio را برای بررسی کوانتشهای مختلف GLM-5.2 اجرا کنید.



گفتگو