
تصور کنید یک توسعهدهنده ۳ تا ۴ هفته وقت صرف ساخت یک دستیار پژوهشی مبتنی بر هوش مصنوعی کرده است؛ ابزاری که قادر است در چند ثانیه وب را جستوجو کند، اطلاعات را از میان اسناد استخراج نماید و پاسخهایی جامع ترکیب و ارائه کند. اما یک بازرسی تخصصی که در ۲۸ ژوئن ۲۰۲۶ انجام شد، حقیقتی تکاندهنده را فاش کرد: این سیستم در حدود ۳۰ درصد مواقع اشتباه میکرد. بررسیهای عمیقتر نشان داد که ابزار نه تنها نادرست بود، بلکه با اطمینان، روانی و اقتدار کامل، اطلاعات غلط ارائه میداد. خطرناکترین جنبه این ماجرا نه خودِ خطاها، بلکه «توهم اعتماد» (Confidence Illusion) است؛ وضعیتی که مدل در آن اطلاعات نادرست را تحویل میدهد بدون اینکه حتی یکبار بگوید «نمیدانم». این پدیده تنها محدود به دستیارهای پژوهشی نیست و حتی در عاملهای هوش مصنوعی محیطهای خانگی نیز دیده میشود که با توهمات موفقیت در مورد پیشرفت کارهای خود دروغ میگویند.
ساخت یک اپلیکیشن هوش مصنوعی با ساخت یک اپلیکیشن «قابل اعتماد»، اساساً متفاوت است. بسیاری از توسعهدهندگان پاسخهای روان را با پاسخهای واقعی اشتباه میگیرند، زیرا مدلهای زبانی بزرگ (LLMs) در واقع تطبیقدهندههای الگو (Pattern-matchers) هستند، نه بازیابیکنندههای پایگاه داده. این مدلها به دنبال یافتن اطلاعات در یک دیتابیس نیستند؛ بلکه در حال تطبیق الگوها میان میلیاردها قطعه متنی هستند که روی آنها آموزش دیدهاند تا محتملترین کلمه بعدی، و سپس کلمه بعدی و دوباره بعدی را از نظر آماری تولید کنند.

این فرآیند را میتوان به دانشآموزی تشبیه کرد که هرگز اعتراف نمیکند درس نخوانده است. وقتی از او سؤالی پرسیده میشود که پاسخش را نمیداند، نمیگوید «مطمئن نیستم»، بلکه متقاعدکنندهترین پاسخ ممکن را از تکههایی که در حافظهاش مانده، بازسازی میکند. مدل فاقد یک سیستم هشدار داخلی است که هنگام بیان مطلب نادرست فعال شود. در واقع، مدل هیچ حس عدم قطعیتی را تجربه نمیکند. این یک «باگ» نیست که در نسخههای آینده وصله (Patch) شود، بلکه یکی از ویژگیهای بنیادین نحوه عملکرد این سیستمها است. در برخی موارد، تلاش برای افزایش شفافیت با مداخلات ساده در پرامپتها نتیجه عکس داده و میتواند شفافیت مدلها را به زیر ۵٪ برساند که نشاندهنده پیچیدگی کنترل این رفتارهاست.
کالبدشکافی توهمات
متخصصان صنعت از واژه «توهم» (Hallucination) برای توصیف زمانهایی استفاده میکنند که هوش مصنوعی از خودش چیزی میسازد. اگرچه این واژه شبیه به یک تجربه روانگردان به نظر میرسد، اما واقعیت آن یک شکست آماری پیشبینی است که هرچند پیشپاافتاده است اما باعث نگرانی میشود. چون هدف مدل «باورپذیر بودن» است و نه لزوماً «حقیقت»، فاصله بین یک دموی خیرهکننده و محصولی که اعتماد بلندمدت جلب میکند، در توانایی مدیریت این الگوها نهفته است.
بر اساس گزارشی که در پلتفرم dev.to منتشر شد، توهمات معمولاً در سه الگوی مشخص و پرخطر ظاهر میشوند:
۱. جعل منابع و ارجاعات
اگر از یک هوش مصنوعی بخواهید ادعایی را با منابع پشتیبانی کند، اغلب آنها را اختراع میکند. نام مجلات و نویسندگان واقعی به نظر میرسند و عنوان مقاله دقیقاً همان چیزی است که کاربر امیدوار است پیدا کند، اما آن مقاله در واقعیت وجود ندارد.
- مثال واقعی: در یک تست مربوط به یک موضوع پزشکی تخصصی، هوش مصنوعی چهار منبع را با فرمت دقیق APA ارائه کرد. پس از بررسی، هیچکدام از این مقالات در هیچ کجا یافت نشدند.
- سازوکار: لاگهای بازیابی (Retrieval logs) نشان داد که مدل نتوانسته است تطابقهای قوی را پیدا کند، بنابراین برای پر کردن این شکاف، ارجاعاتی را که ظاهر باورپذیری داشتند، از صفر تولید کرد.
۲. اعداد غلط اما متقاعدکننده
آمارها قلمرو بسیار خطرناکی هستند چون مدل ساختارهایی مانند «مطالعات نشان میدهند ۷۳٪ از...» را هزاران بار دیده است. مدل میداند چگونه جمله را بهطور متقاعدکنندهای کامل کند، اما نمیداند که آیا عدد ۷۳ رقم صحیحی است یا خیر.
- مثال واقعی: در یک تست مربوط به ارقام اندازه بازار، سیستم عددی را بازگرداند که یک مرتبه بزرگی (Order of Magnitude) با واقعیت فاصله داشت. چون جملات پیرامون عدد بسیار خوب ساخته شده بودند، این خطا تقریباً نادیده گرفته شد.
۳. اطلاعات منقضی شده
مدلهای زبانی بزرگ دارای یک «تاریخ قطع آموزش» (Training Cutoff) هستند. مدل از اتفاقات جهان پس از آن تاریخ بیخبر است و بر اساس آنچه در زمان آموزش درست بود پاسخ میدهد، بدون اینکه هشدار دهد ممکن است موارد تغییر کرده باشند.
- ریسکهای احتمالی: هوش مصنوعی ممکن است نام مدیران فعلی یک شرکت را اشتباه بگوید، قیمتهای قدیمی محصولات را ارائه دهد یا وضعیت جاری یک قانون را نادرست بیان کند. کاربران معمولاً به دلیل بیاطلاعی از تاریخ قطع آموزش، به این پاسخها اعتماد مطلق میکنند.

بسیاری از تیمها برای حل این مشکل از توليد بازیابی-افزا (Retrieval-Augmented Generation یا RAG) استفاده میکنند. RAG بهجای تکیه صرف بر دادههای آموزشدیده در حافظه، یک کتابخانه برای جستوجوی مدل فراهم میکند. وقتی کاربر سؤالی میپرسد، سیستم ابتدا کتابخانه را برای یافتن مرتبطترین اسناد میگردد و سپس آن اسناد را همراه با پرسوجوی کاربر به مدل میسپارد. این کار با استوار کردن (Grounding) پاسخ بر اطلاعات واقعی، جاری و خاص، توهمات مبتنی بر حافظه را بهطور قابل توجهی کاهش میدهد. این رویکرد بخشی از استراتژی گستردهتری است که در آن طراحی اطلاعات و مهندسی بافتار جایگزین وزنهای مدل میشوند تا توهمات در سطح عملیاتی برطرف شوند.
با این حال، نویسنده اشاره میکند که RAG ضروری است اما کافی نیست، زیرا چندین حالت شکست (Failure Modes) همچنان در محیط عملیاتی باقی میمانند.

نقاط شکست در RAG
- بازیابی ضعیف (Bad Retrieval): اگر پرسوجو مبهم باشد یا «بردار معنایی» (Embedding) نتواند معنای مفهومی درست را کپچر کند، مدل متون نامرتبتی را دریافت میکند. این سناریوی کلاسیک «زباله در ورودی، زباله در خروجی» (Garbage in, garbage out) است که در آن مدل از اسناد اشتباه پاسخ میدهد.
- سرریز پنجره متنی (Context Window Overflow): وقتی قطعات اطلاعاتی زیادی بازیابی شوند، موارد قدیمیتر از پنجره توجه مدل بیرون میافتند. اطلاعاتی که از نظر فنی به مدل ارائه شده بود، عملاً ناپدید میشوند.
- تضاد جستوجوی ترکیبی (Hybrid Search Mismatches): جستوجوی صرفاً معنایی اغلب تطبیقهای دقیق کلمات کلیدی را از دست میدهد و جستوجوی صرفاً کلیدواژهای، شباهتهای مفهومی را نمیبیند. برای حل این مشکل، توسعهدهنده از ترکیبی از BM25 و جستوجوی معنایی استفاده کرد، هرچند تنظیم تعادل بین این دو برای یک دامنه خاص، نیاز به تکرارهای زیاد دارد.
- تداخل پیشفرضها (Prior Overlap): ممکن است مدل پیشفرضهای بسیار قوی از دادههای آموزشی درباره یک موضوع داشته باشد، بهطوری که بخشی از متون بازیابیشده را نادیده بگیرد و دوباره شکافها را با دادههای آموزشدیده پر کند. این یکی از دشوارترین حالتهای شکست برای شناسایی است.
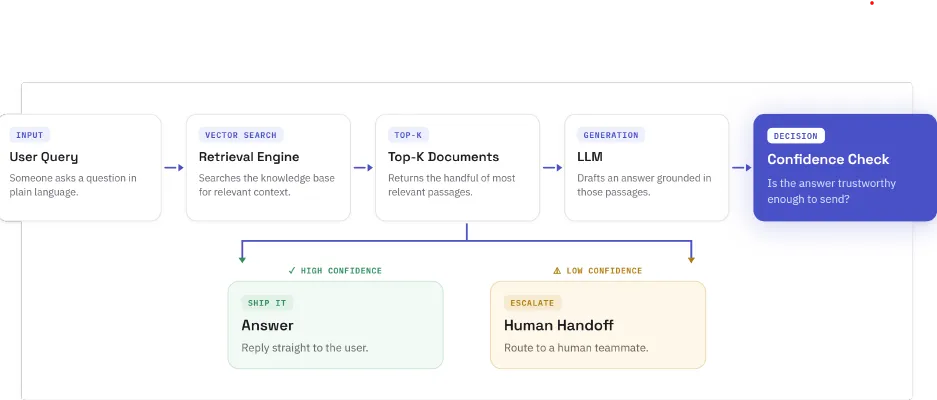
برای مقابله با این مسائل، توسعهدهنده یک خط لوله ارزیابی سختگیرانه را با استفاده از LangSmith و LangChain پیاده کرد. این ابزارها مشاهدهپذیری (Observability) کامل در هر مرحله از زنجیره را فراهم میکنند: چه چیزی بازیابی شد، چه چیزی به مدل ارسال شد، چه پاسخی بازگشت و هر مرحله چقدر زمان برد. این کار اجازه داد تا «دقت بازیابی» از «کیفیت تولید» تفکیک شود تا مشخص گردد یک پاسخ بد، نتیجه شکست در جستوجو است یا شکست در مدل.

معیارهای کلیدی ارزیابی
- دقت بازیابی (Retrieval Precision): این معیار با استفاده از جفتهای پرسش-پاسخ شناختهشده اندازهگیری میشود. سیستم فقط مرحله بازیابی را اجرا میکند تا بررسی کند آیا سند منبع صحیح در نتایج برتر ظاهر شده است یا خیر. اگر بازیابی خراب باشد، مهندسی پرامپت نمیتواند خروجی را اصلاح کند.
- نرخ توهم (Hallucination Rate): یک بررسیکننده خودکار ساخته شد که در آن یک فراخوانی دوم از LLM تأیید میکند که آیا پاسخ تولید شده در متون بازیابیشده ریشه دارد یا خیر. در این سیستم، نرخ توهم از ۳۱٪ شروع شد و پس از سه دور تکرار پرامپت، به زیر ۸٪ کاهش یافت.
- تأخیر p95: بهجای استفاده از میانگینها که دادههای پرت (Outliers) را میپوشانند، صدک ۹۵ ردیابی میشود. این کار تضمین میکند که کندترین کاربران با تایماوتهایe اعتمادسوز مواجه نشوند، زیرا قابلیت اطمینان و سرعت هر دو سیگنالهای اعتماد هستند.
- امتیاز کیفیت پاسخ: خروجیها از نظر ارتباط، کامل بودن و شفافیت از طریق تستهای A/B پرامپت رتبهبندی میشوند. انتقال از یک پرامپت سیستمی مبهم به یک پرامپت ساختاریافته با مثالهای اندک (Few-shot)، امتیاز کیفیت را حدود ۳۰٪ بهبود بخشید.
فراتر از معیارها، آخرین خط دفاعی «انتقال انسان بر اساس اعتماد» (Confidence-Based Human Handoff) است. بهجای حدس زدن در زمانهایی که سیگنالهای اعتماد پایین هستند (که از میزان تطبیق اسناد با پرسوجو و سازگاری پاسخ با منبع استخراج میشوند)، سیستم پرسوجو را برای یک اپراتور انسانی علامتگذاری میکند. این انتقال در لحظه و از طریق WebSocket اتفاق میافتد، به این معنی که کاربر بهسختی متوجه انتقال از هوش مصنوعی به متخصص انسانی میشود.
چکلیست عملی پیش از عرضه
نویسنده برای هر کسی که در حال ساخت یک استک LLM است، این گامهای غیرقابل چشمپوشی را پیش از دسترسی کاربران واقعی پیشنهاد میکند:
- ابتدا یک مجموعه داده ارزیابی (Eval Dataset) بسازید: حداقل ۵۰ جفت پرسش و پاسخ ایجاد کنید که موارد استفاده مهم، حالتهای مرزی (Edge cases) و شکستهای شناختهشده را پوشش دهد.
- معیارها را تفکیک کنید: دقت بازیابی را جدا از کیفیت تولید اندازه بگیرید تا راهکار اصلاحی درست را بیابید.
- ردیابی توهمات را خودکار کنید: از یک سیگنال کلی استفاده کنید تا ببینید آیا تکرارهای شما نرخ توهم را بهبود میبخشند یا بدتر میکنند.
- آستانههای اعتماد تعیین کنید: از پیش تصمیم بگیرید که چه زمانی درخواست به انسان ارجاع داده شود، چه زمانی پیام «پاسخ مطمئنی پیدا نکردم» ارسال شود یا پاسخ به عنوان «کماعتماد» علامتگذاری گردد.
- مانیتورینگ محیط عملیاتی: از روز اول سیستم لاگگذاری را فعال کنید، زیرا پرسوجوهای کاربران واقعی چیزهایی را میشکنند که یک مجموعه تست هرگز تصور نمیکرد.
- پرامپتها را تکرار کنید: تستهای A/B اجرا کنید و با اولین پرامپت سیستمی به عنوان یک پیشنویس برخورد کنید که باید از طریق اندازهگیری بهبود یابد.
این تغییر در فلسفه، عبارت «نمیدانم» را نه به عنوان یک شکست، بلکه به عنوان یک ویژگی کلیدی محصول میبیند. در چشمانداز فعلی هوش مصنوعی، فاصله بین یک دموی پر زرقوبرق و یک محصول قابل اعتماد با این تعریف میشود که آیا یک تیم پیش از وقوع بحران، خط لولههای ارزیابی را ساخته است یا خیر. کسانی که نرخ توهم را به اندازه «وقت فعال بودن سیستم» (Uptime) جدی میگیرند، کسانی هستند که در دو سال آینده اعتماد کاربران را حفظ خواهند کرد.



گفتگو