
اگر با گلوگاههای پهنای باند حافظه در پردازندههای AMD دستوپنجه نرم میکنید، باید بدانید عصر رمزگشایی توکنبهتوکن در حال پایان است.
بیشتر مدلهای زبانی بزرگ (LLM) با محدودیت پهنای باند حافظه مواجهاند؛ یعنی زمان بیشتری را صرف جابهجایی دادههای KV-cache میکنند تا محاسبات واقعی. همانطور که در تحلیل قبلی ما دربارهی بهینهسازی هزینهها با Mistral Nemo و vLLM اشاره کردیم، هدف اصلی همواره کاهش این اتلاف زمان بوده است.
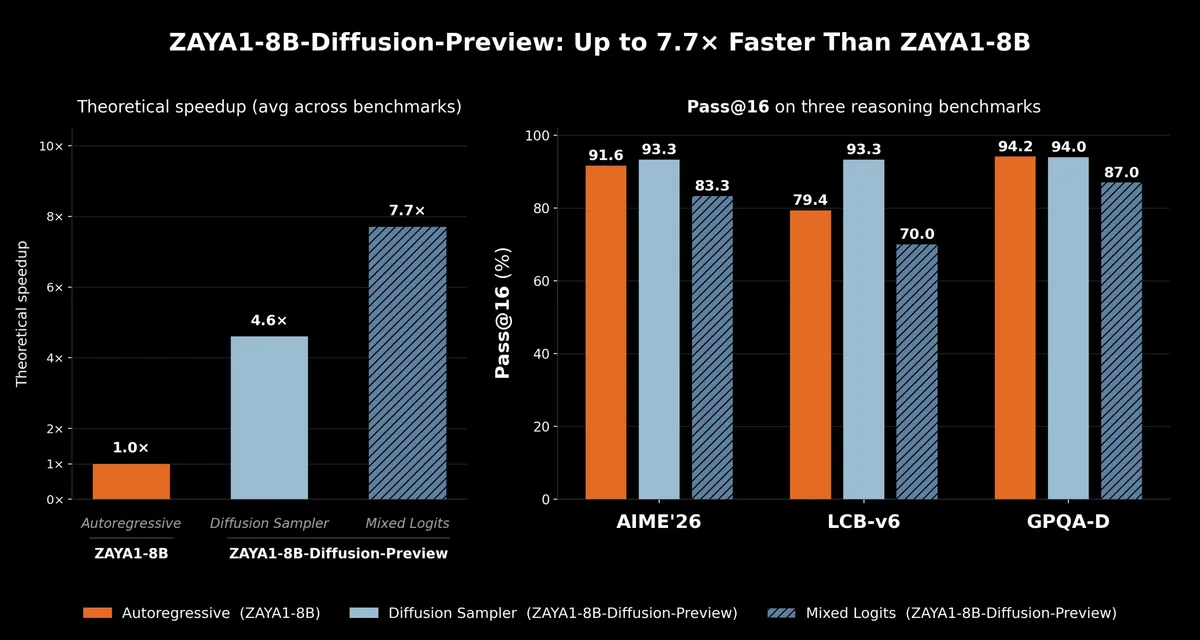
شرکت Zyphra در تاریخ ۱۴ مه ۲۰۲۶ اعلام کرد که با تبدیل یک مدل مخلوط خبرگان (Mixture of Experts - MoE) خودبازگشتی (Autoregressive) به یک مدل انتشار (Diffusion Model) گسسته، توانسته است سرعت استنتاج (Inference) را در سختافزارهای AMD تا ۷.۷ برابر افزایش دهد. مدل ZAYA1-8B-Diffusion-Preview با استفاده از دستورالعمل TiDAR و آموزش تکمیلی با ۱.۱ تریلیون توکن ساخته شده است. طبق گزارش Marktechpost، این مدل میتواند ۱۶ توکن را بهطور همزمان در یک گذر پیشرو (Forward Pass) تولید کند و همزمان نقش پیشبین و تأییدکننده را ایفا نماید.
مشخصات فنی این مدل عبارت است از:
- Lossless Sampler: افزایش سرعت ۴.۶ برابری بدون افت سیستماتیک در ارزیابیها.
- Logit-mixing Sampler: افزایش سرعت ۷.۷ برابری با پذیرش اندکی افت کیفیت.
- معماری: استفاده از CCA attention و CCGQA (نسبت ۴ به ۱ برای Query-to-Key) جهت کاهش محاسبات prefill، که بهطور خاص برای GPUهای AMD MI300x و MI355x بهینه شده است.
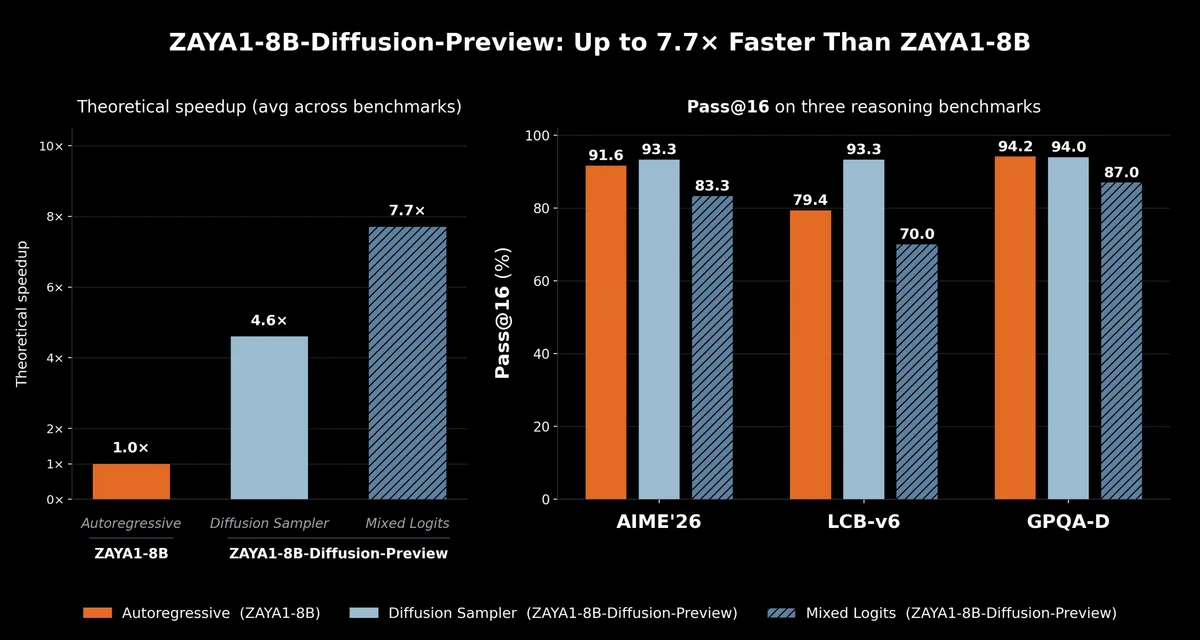
این دستاورد ثابت میکند که تولید به سبک مدلهای انتشار را میتوان بدون نیاز به دشواریهای آموزش از صفر، در زیرساختهای پیشآموزش موجود ادغام کرد. برای مهندسان هوش مصنوعی، حیاتیترین پیام این خبر، کاهش چشمگیر هزینه برای اجرای RL rollouts در سیاستهای On-policy است. با سریعتر شدن تولید توالیهای آموزشی، هزینه یادگیری تقویتشده و مقیاسپذیری محاسبات زمان-تست (Test-time compute) کاربردیتر میشود.

گام بعدی شما
- بررسی عملکرد مدل در بنچمارکهای دقت استاندارد در مقابل ارزیابیهای pass@.
- رصد انتشار نسخه آموزشدیده با یادگیری تقویتشده (RL).
- تحلیل اثر این معماری بر کاهش هزینههای Test-time compute.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.



گفتگو