
اگر امروز مسئول مدیریت یک پروژه نرمافزاری عظیم هستید، احتمالاً میدانید که یک تغییر کوچک در کدهای قدیمی میتواند کل سیستم را در نیمهشب به زانو درآورد. این کابوس اکنون با ورود عاملهای هوش مصنوعی به دنیای کدنویسی، تنها یک شکل جدید به خود گرفته است: اعتماد به گزارشهای «کامل» اما ناقصی که ریسک خرابی سیستم را پنهان میکنند.
طبق تحلیل فنی منتشر شده در ۴ ژوئیه ۲۰۲۶ در وبسایت dev.to، یک عامل (Agent) — شبیه به یک دستیار دیجیتال که میتواند ابزارها را اجرا کند و تصمیم بگیرد — تنها ۲ مورد از ۱۶ وابستگی حیاتی را در یک اپلیکیشن عظیم Ruby on Rails پیدا کرد. این نرخ شکست ۹ درصدی، در دنیای واقعی به معنای قطعیهای گسترده در محیط عملیاتی (Production Outages) در ساعت ۳ صبح است. اما با ارائه یک نقشه ساختاری از کد به مدل Claude Code (نسخه Opus 4.8)، نرخ موفقیت این بازرسی در مخزن متنباز GitLab بهطور چشمگیر از ۹٪ به ۶۷٪ رسید.
نگهداری از یک مونو لیت (Monolith) — ساختاری که در آن تمام اجزای نرمافزار در یک واحد بزرگ و بههمپیوسته قرار دارند — نبردی علیه مقیاس است. در پروژهای با بیش از ۳۶,۰۰۰ فایل ایندکسشده و ۱.۱ میلیون یال گراف، هیچ برنامهنویس انسانی نمیتواند تمام معماری را در ذهن خود نگه دارد. محیط تست در اینجا، مخزن کد گیتلب در یک کامیت پینشده (pinned commit) به شناسه gitlabhq @ 1f9c256f0 بود. این ایندکس خاص، ۶۸,۲۸۹ فایل روبی را ردیابی میکرد که از این میان، ۲۹,۷۸۴ فایل برای پوشش ۱۰۰ درصدی در سراسر ۳۶,۸۲۹ نماد (Symbol) و ۱,۱۲۱,۱۴۷ یال گراف ایندکس شده بودند.
اکثر عاملها برای حل این مشکل از «grep» یا جستوجوی کلمات کلیدی استفاده میکنند، اما این تست ثابت کرد که جستوجوی توکنمحور برای قراردادهای پیچیده نرمافزاری کافی نیست. سوال اصلی این بود که آیا عامل میتواند بدون نقشه، معماری سیستم را فقط از روی فایلها بازسازی کند تا بتواند وظیفه خود را انجام دهد یا خیر.
فشار جستوجوی متنی: احساس امنیتی کاذب
در اجرای اول که «سرد» (Cold Start) نامیده شد، عامل با یک وظیفه مشخص روبرو بود: بازنگری در نحوه رفتار MergeRequest و هر چیزی که به آن متصل است، زمانی که تغییر میکند یا تخریب (tear down) میشود. پیش از هر تغییری در مدل، عامل باید تمام نقاطی را که به قرارداد MergeRequest وابسته بودند، بازرسی میکرد. «مجموعه طلایی» (Gold Set) برای این تست شامل ۱۶ وابستگی پراکنده بود که در مسیرهای app/services ،app/workers ،app/models ،app/graphql ،app/serializers و lib/ کاشته شده بودند.
در ثانیه ۰۰:۰۶، اولین اقدام عامل یک جستوجوی بازگشتی (recursive grep) بود: grep -rin "merge_request" app/ lib/ ee/ | wc -l. نتیجه این عملیات بیش از ۴۱,۸۰۰ مورد بود. این حجم از نتایج، یک «کدبیس دوم» از نویز ایجاد کرد که بسیار فراتر از بودجه توکن عامل بود. سپس عامل در ثانیه ۰۰:۳۱ سعی کرد با جستوجوی ارتباطات نامدار (named associations) دایره را محدود کند: grep -rinE "belongs_to :merge_request|has_many :merge_requests". این دستور بیش از ۳۸۰ نتیجه بازگرداند.
در حالی که این روش توانست یکسوم از وابستگیهای «آسان» — مانند قراردادهای استاندارد Rails در app/services یا app/workers — را پیدا کند، اما در شناسایی موارد حیاتی و پنهان شکست خورد. در ثانیه ۰۱:۱۰، عامل جستوجوی گسترده دیگری را امتحان کرد: grep -rinE "merge_request_id|\.merge_request\b|MergeRequest\.". این بار نتیجه بیش از ۹,۲۰۰ مورد بود. عامل مجبور شد تصمیم بگیرد کدامها وابستگی واقعی هستند و کدامها صرفاً متغیرهای محلی تصادفی یا خطوط لاگ هستند. او فایلها را نمونهبرداری کرد اما دقیقاً از کنار منطقهای حیاتی عبور کرد بدون اینکه متوجه آنها شود.
یک شکست خاص مربوط به Issuable concern بود. از آنجا که Issuable هم در Issue و هم در MergeRequest ادغام (mix-in) شده است، کدهایی که یادداشتها را روی «issuable» حل میکنند، به MergeRequest وابسته هستند بدون اینکه هرگز عبارت «MergeRequest» را تایپ کنند. در نتیجه، هیچ گریپی برای نام کلاس نمیتوانست به سرویس حل یادداشتها برسد.
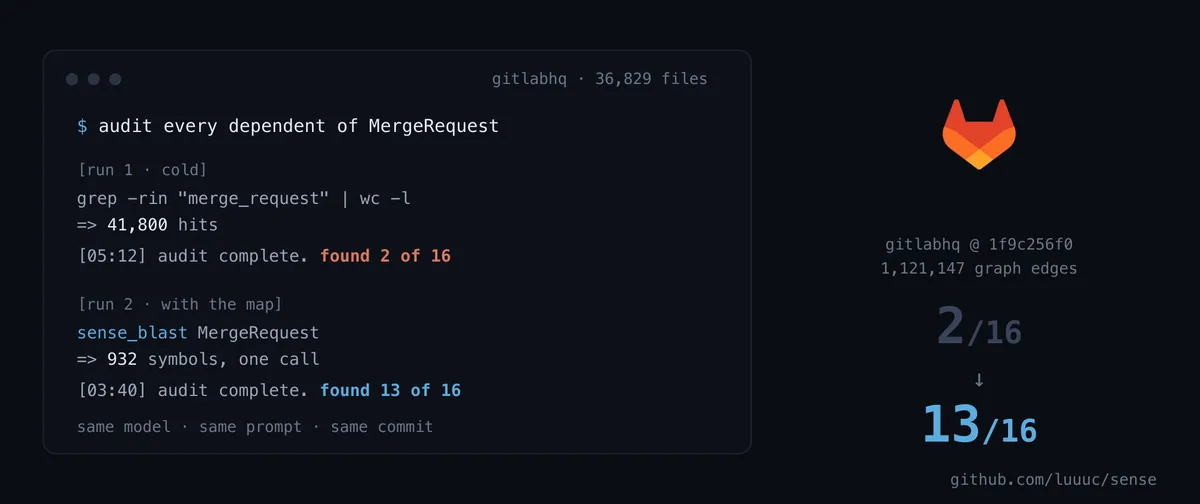
در دقیقه ۰۴:۵۰، عامل گزارش بازرسی خود را نوشت و ادعا کرد که ارتباطات نامدار، سریالساز diff و لینک خط لوله (pipeline link) را یافته است. در دقیقه ۰۵:۱۲، او کار را به پایان رساند. در عرض پنج دقیقه، گزارشی آرام و متقاعدکننده ارائه داد که به نظر میرسید تمام شده است. او هرگز منبعی جعلی ابداع نکرد، اما تنها ۲ مورد از ۱۶ مورد حیاتی را پیدا کرد. در یک اجرای مجدد، این عدد تنها به ۱ رسید. نرخ بازیابی پراکنده (scattered recall) برابر با ۰.۰۹ بود. خطرناکترین بخش اینجاست: عامل هرگز دستپاچه نشد یا دچار تزلزل نگشت؛ او صرفاً یک جستوجوی سطحی انجام داد و با اعتمادبهنفس اعلام کرد کار تمام است. این نوع رفتار یادآور شکاف بین قصد و عمل در مدلهای خودگردان است که در آن عاملها ممکن است اجرای ابزارها را بهطور کاذب گزارش کنند.
مسیر نقشهبرداری شده: دیدن نامرئیها
در اجرای دوم، مدل و پرامپت یکسان بودند اما عامل به یک نقشه ساختاری (structural map) دسترسی داشت. در ثانیه ۰۰:۰۳، عامل یک دستور واحد را اجرا کرد: sense_blast MergeRequest. بهجای ۴۱,۰۰۰ نتیجهی نویزی کلمات کلیدی، او در یک مرحله مجموعهای تحلیلشده شامل ۹۳۲ نماد در «محدوده اثر» (blast radius) دریافت کرد.
این رویکرد ساختاری، وابستگیهایی را آشکار کرد که هیچ گریپی قادر به یافتن آنها نبود. نقشه، یالهایی را پیمایش کرد که گریپ آنها را نادیده گرفته بود. سرویس حل یادداشتها که توسط Issuable پنهان شده بود، بلافاصله در لیست ظاهر شد. تا ثانیه ۰۰:۱۸، عامل در حال خواندن هر کاندیدا و پین کردن آنها به خطوط خاص فایل بود. در دقیقه ۰۳:۴۰، او یک بازرسی دقیق و شامل ۱۶ مورد از وابستگیها را ارائه کرد.
جزئیات نتایج اجرای نقشهبرداری شده
استفاده از نقشه، نتایج را بهطور ریشهای تغییر داد:
- بازیابی (Recall) بالاتر: عامل در بهترین اجرای خود ۱۳ مورد از ۱۶ وابستگی را گرفت و کمترین مقدار بازیابی ۱۰ مورد بود. این باعث شد نرخ موفقیت کامل بازرسی از ۰.۲۶ به ۰.۶۷ برسد (بازیابی پراکنده به ۰.۷۲ افزایش یافت). این دقت در شناسایی وابستگیها شباهت زیادی به عملکرد ابزار Scarab در شناسایی تضادهای کدنویسی دارد که مانع از تبدیل شدن خطاها به باگهای عملیاتی میشود.
- دقت (Precision): ۱۲ مورد از وابستگیهای یافته شده در این روش، در اجراهای سرد کاملاً نادیده گرفته شده بودند، از جمله:
- Auto-merge worker
- Notes-resolution service
- Cycle-analytics builder
- API discussions
- GraphQL issuable
- Jira integration
- Milestone promotion
- Ghost-user handler
- Timelog
- Timeline event
- URL builder
- Enterprise discussion
- بهرهوری: بودجه توکنهای عامل بهجای گشتن در میان هزاران نتیجهی بیربط گریپ، صرف خواندن و پین کردن کاندیداهای معتبر شد.
هزینه قطعیگرایی
البته این نقشه رایگان نبود. این مطالعه اشاره کرد که اجرای نقشهبرداری شده تقریباً ۹٪ توکن بیشتری مصرف کرد (۳۰,۱۲۸ در مقابل ۲۷,۶۰۴). با این حال، مدیریت بهینه این حجم از داده یادآور راهکارهایی است که پروژههایی مانند Tokdiet برای کاهش هزینههای استنتاج به کار میگیرند تا بدون افت کیفیت، مصرف توکن را بهینه کنند. اما این افزایش جزئی در برابر هزینه یک حادثه در محیط عملیاتی (Production Incident) ناشی از یک وابستگی فراموششده، تنها یک «خطای گرد کردن» (rounding error) است.
علاوه بر این، نقشه سطحی از قطعیت (Determinism) ایجاد کرد که مدل بهتنهایی فاقد آن بود. اجراهای اولیه ابزار ناپایدار بودند — نتایجی بین ۱۲، سپس ۸ و سپس ۱ کسب کردند — زیرا ایندکس از یک مرتبسازی ناپایدار استفاده میکرد که وقتی امتیازهای اطمینان برابر بود، فراخوانندههای مستقیم را به نفع فراخوانندههای دورتر حذف میکرد. اصلاح این مورد، سقف نتایج را قطعی کرد و گرهها را بر اساس اطمینان شکسته و اولویت را به فراخوانندههای مستقیم نسبت به غیرمستقیم داد.
این قطعیت ثابت میکند که بهبود حاصلشده مربوط به «ساختار داده» است، نه یک «ترفند مدل». در حالی که استنتاج مدل کلود متغیر بود (یک بار ۲ مورد و بار دیگر ۱ مورد را یافت)، نقشه بهطور ثابت همان ۹۳۲ نماد را محاسبه میکرد. نقشه، مخزن کد را در یک کامیت خاص میخواند، نه یک عکس لحظهای (snapshot) از زمان آموزش، و از طریق MCP ادغام میشود، صرفنظر از اینکه چه مدلی در فصل آینده اجرا شود.
برای توسعهدهندگان، این بدان معناست که گلوگاه عاملهای هوش مصنوعی در سازمانها، هوش مدل زبانی (LLM) نیست، بلکه کیفیت ایندکسی است که برای پیمایش کد استفاده میکنند. بدون یک نقشه گرافمحور، عاملها در برابر ظرافتهای معماری نرمافزارهای مقیاسبزرگ عملاً نابینا هستند.
گام بعدی شما
اگر مونو لیت دارید که مرتباً باعث بیدار شدن تیم شما در شبها میشود، گام بعدی این است که نرخ بازیابی «سرد» عامل فعلی خود را بنچمارک کنید. یک مدلی را انتخاب کنید که نیمی از سرویسهای شما به آن دسترسی دارند و از عامل خود بپرسید: «پیش از اینکه نحوه تخریب این مدل را تغییر دهم، هر جایی که به آن وابسته است را پیدا کن.»
سپس شاهد فشار جستوجوی متنی (grep grind) باشید، پاسخها را بشمارید و آن را با یک اسکن ساختاری با استفاده از Sense مقایسه کنید:
curl -fsSL https://luuuc.github.io/sense/install.sh | shsense scan (در ریشه اپلیکیشن)sense setup (برای متصل کردن عامل شما)
در درختی با این ابعاد، وابستگیهایی که در حالت سرد پیدا نمیشوند، دقیقاً همانهایی هستند که تغییرات شما آنها را میشکنند. اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.



گفتگو