
تصور کنید با سه درس دشوار در سطح ارشد و یک شغل پارهوقت دستوپنجه نرم میکنید و هر هفته با کوهی از PDFهای پراکنده روبهرو هستید. در این وضعیت، مشکل اصلی دیگر درک مفاهیم نیست، بلکه مدیریت حجم عظیم دادههاست تا مغز فرصت یادگیری داشته باشد. این فلسفه، یک دانشجوی ارشد مهندسی نرمافزار و هوش مصنوعی را به مسیر ساخت یک خط لوله پنجمرحلهای با یک سیستم سختگیرانه با استفاده از Claude Code کشاند تا بتواند در محیط یک «کلاس معکوس» با حجم مطالب بسیار بالا بقا یابد. هدف این است که هوش مصنوعی زاینده (Generative AI) — مثل دستیاری باشد که تمام کارهای اداری و بایگانی را انجام میدهد تا شما فقط روی حل مسئله تمرکز کنید — تدارکات یادگیری را بر عهده بگیرد، اما فشار شناختی (Cognitive Effort) را برای انسان حفظ کند. با پیادهسازی این سیستم، توسعهدهنده میتواند PDFهای خام دانشگاهی را به پورتفولیویی آماده برای تحویل تبدیل کند، بدون اینکه یادگیری واقعی را فدا کند.
همانطور که در تحلیلهای قبلی ما دربارهی کاربردهای عاملهای هوش مصنوعی (AI Agents) اشاره کردیم، کلید موفقیت در این ابزارها، تبدیل پرامپتهای پراکنده به «مهارتهای» (Skills) تعریفشده و تکرارپذیر است. در Claude Code، یک «مهارت» در واقع یک پرامپت نامگذاری شده و قابل استفاده مجدد است که ورودیهای یکسانی را میگیرد، از حفاظهای (Guardrails) مشابهی پیروی میکند و نتیجهای ثابت تولید میکند. این رویکرد شباهت زیادی به ساختارهای لایهای برای کاهش نرخ خطا دارد که باعث میشود خروجی ابزارها از حالت تصادفی خارج شده و به استانداردهای سطح ارشد نزدیک شود. این تکرارپذیری باعث میشود کاربر مجبور نباشد هر هفته توضیح دهد که «من چگونه مطالعه میکنم»؛ بلکه به سادگی دستوری مانند /study-mode BDA 5 را اجرا میکند تا نتیجهای منضبط دریافت کند. این رویکرد، یک بار تحصیلی آشوبزده را به یک خط لوله مدیریتشده تبدیل میکند که در آن هر مرحله، نوع خاصی از دشواری و فشار را حذف میکند.
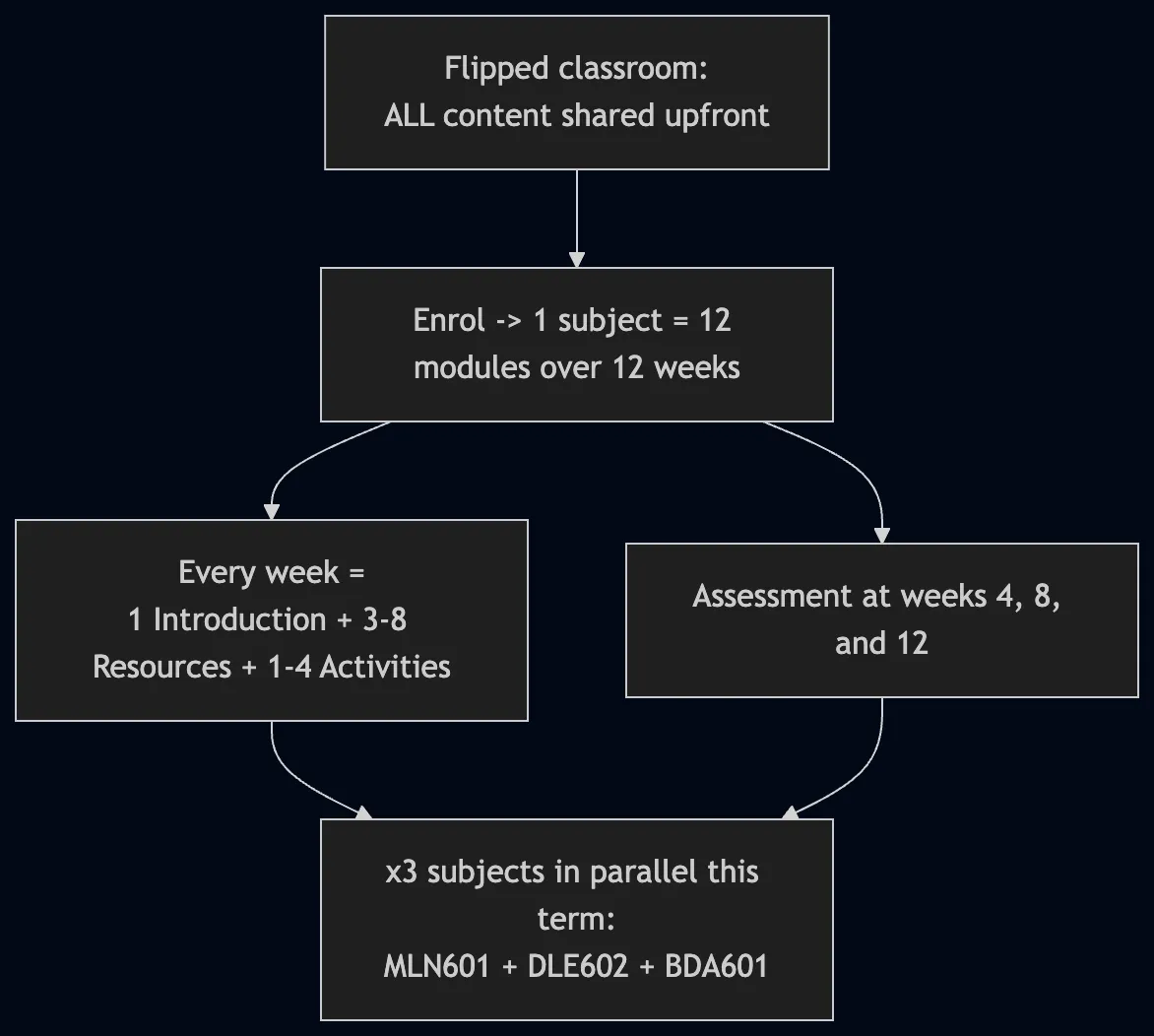
طبق مستندات این پروژه، در یک مدل کلاس معکوس (Flipped Classroom)، تمام محتواها پیش از شروع اولین جلسه کلاس در اختیار دانشجو قرار میگیرد. در این مدل، فشار حجم مطالب در لحظه ثبتنام احساس میشود و فرآیند یادگیری به چالشی در زمینه «ظرفیت پردازشی» (Throughput) تبدیل میشود تا صرفاً درک محتوا. برای این دانشجو، بار کاری بسیار زیاد است: او همزمان سه درس را میگذراند و یک شغل پارهوقت دارد و باید با این حجم از دادهها مدیریت زمان دقیقی داشته باشد.
برای درک مقیاس این فشار، باید به الزامات یک درس واحد در طول ۱۲ هفته نگاه کنیم:
- ماژولها: ۱۲ ماژول (یک مورد در هر هفته).
- منابع: ۳ تا ۸ منبع برای هر ماژول (شامل فصلهای کتاب درسی، مقالات پژوهشی، ویدئوها و پادکستها).
- فعالیتها: ۱ تا ۴ فعالیت در هر ماژول (انجمنهای گفتگو، نوتبوکهای عملی و کوئیزها).
- ارزیابیها: ۳ نقطه عطف اصلی (معمولاً هر چهار هفته یکبار در هفتههای ۴، ۸ و ۱۲).
وقتی این اعداد در سه درس ضرب شوند، یک ترم تحصیلی شامل بیش از ۱۰۰ منبع و ۹ ارزیابی اصلی میشود. تله اینجاست: اگر دانشجو سعی کند همه چیز را سریع مرور کند، در لحظه آزمون با صفحه سفید مواجه میشود و هیچ چیز در حافظه نگه نمیدارد. کلاس معکوس فرض میکند که دانشجو خودش مدیریت این حجم از مطالب پیشنیاز را انجام میدهد؛ این توسعهدهنده صرفاً تصمیم گرفت که این کار را به صورت دستی انجام ندهد و یک سیستم خودکار جایگزین کند.
مرحله ۱: نقشهبرداری درس (/subject-scaffold)
اولین چالش یک درس جدید، توده پراکنده PDFهاست (طرح درسها، برنامهریزها و دستورالعملهای ارزیابی) بدون اینکه یک «منبع واحد حقیقت» برای مسیر ۱۲ هفتهای وجود داشته باشد. مهارت subject-scaffold با استفاده از ابزار pdftotext این اسناد را میخواند و یک فایل README.md میسازد که به عنوان نقشه ترم عمل میکند.
ساختار این README شامل موارد زیر است:
- معرفی و جزئیات کلی درس
- نتایج یادگیری درس (SLO)
- برنامه تحویل هفتهبههفته و زمانبندی دقیق
- چکلیست ماژولها و جدول جامع ارزیابی
- جزئیات مربوط به تسهیلکننده یادگیری (Learning Facilitator)
- یادداشتهای منابع و مراجع
قرارداد این مهارت بسیار سختگیرانه است: این ابزار باید فقط بر اساس واقعیتهای موجود در منابع بسازد. عامل اکیداً منع شده است که عنوان ماژولها، نتایج یادگیری، موضوعات ارزیابی، نمرات یا تاریخها را از خودش ابداع کند. این سختگیری برای جلوگیری از توهم (Hallucination) در مورد ضربالاجلهاست تا دانشجو با تاریخهای غلط مواجه نشود. خروجی این مرحله، یک «نقشه کف» از ترم ارائه میدهد؛ برای مثال، مشخص میکند که ارزیابیهای درس BDA601 در هفتههای ۴، ۸ و ۱۲ قرار دارند و توزیع نمرات آنها ۳۰٪، ۳۰٪ و ۴۰٪ است. با دانستن شکل کلی درس پیش از مطالعه حتی یک صفحه، دانشجو اضطراب ناشی از ناشناختهها را حذف میکند و دقیقاً میداند چه زمانی فشار کاری افزایش مییابد.
مرحله ۲: تلخیص منابع (/study-mode)
حجم مطالعه میتواند طاقتفرسا باشد. برای مثال، ماژول ۲ ممکن است شامل یک فصل درباره استراتژی دادهها و دو فصل درباره دریاچههای داده (Data Lakes) باشد که در مجموع ۹۰ دقیقه مطالعه میطلبد؛ زمانی که یک فرد شاغل در روز سهشنبه ندارد. مهارت study-mode هر منبع را میخواند (PDFها از طریق pdftotext و مقالات وب از طریق fetch) و یادداشتهای ساختاریافتهای را در فایلهای moduleNN_notes.md مینویسد.
هر منبع از طریق یک چارچوب ثابت پردازش میشود تا هیچ جزئیات حیاتی حذف نشود:
- ارجاع (Citation): نام نویسنده، سال و عنوان اثر به صورت استاندارد.
- هدف (Purpose): خلاصهای در ۱ یا ۲ جمله درباره اینکه منبع چه چیزی را پوشش میدهد و چرا اهمیت دارد.
- تمهای اصلی (Major Themes): استفاده از لیستهای گلولهای (Bullet points) با برچسبهای ضخیم (Bold) برای اصطلاحات کلیدی و استفاده از جداول مقایسهای در مواردی که چندین مفهوم یا آیتم با هم مقایسه میشوند.
- اتصال به درس (Subject Connection): بخشی که بیان میکند این منبع چگونه به فعالیتها و ارزیابیهای خاص هر ماژول مرتبط است.
در کاربرد عملی برای ماژول ۲ درس BDA، سیستم یک توالی کلیدی را در منبع «Marr, B. (2021). Data Strategy - Chapter 6: Sourcing and Collecting» شناسایی کرد. سیستم یادداشت کرد که کاربر باید ابتدا از «استراتژی» (شناسایی سوالات تجاری) شروع کند، نه از «دادهها». این مهارت با استفاده از ایموجیهای وضعیت، منابع تکمیلشده را علامت میزند و از دست زدن به مطالبی که قبلاً بررسی شدهاند خودداری میکند؛ در واقع مانند تلخیصگری است که حافظه دارد. این فرآیند، ۹۰ دقیقه مطالعه را به یک اسکن ۱۰ دقیقهای از نکات برجسته و ارجاعشده تبدیل میکند که دقت بالایی در رفرنسدهی دارد.
مرحله ۳: بازخوانی فعال (/active-recall)
برای مقابله با «توهم صلاحیت» (Illusion of Competence) — وضعیتی که در آن بازخوانی یادداشتها به اشتباه با یادگیری تلقی میشود و فرد فکر میکند مطلب را میداند در حالی که فقط با متن آشناست — مهارت active-recall کار را دوباره به دوش انسان میاندازد. خلاصهها به تنهایی راحت اما بیفایده هستند. این مهارت یادداشتهای مرحله ۲ را خوانده، به صورت خصوصی ۵ سوال میسازد و آنها را یکییکی میپرسد.
پروتکل تعاملی این مهارت برای تضمین نمرهدهی صادقانه به شرح زیر است:
- سوال اول را میپرسد و متوقف میشود، بدون اینکه کلید پاسخهای خصوصی را فاش کند تا دانشجو نتواند پاسخ را تقلید کند.
- تلاش اول را از ۰ تا ۵ نمره میدهد، پیش از آنکه هر مفهومی را آموزش دهد یا سوالات تکمیلی بپرسد.
- نتیجه را بر اساس چهار دسته بازمیگرداند: درست (Right)، شکاف (Gap)، اصلاح (Fix) و یک «لنگر» (Anchor) کاربردی.
- پس از ۵ سوال، میانگین نمره را محاسبه کرده و ۳ پرامپت خاص برای آزمون مجدد تولید میکند تا نقاط ضعف پوشانده شوند.
نقش «لنگر» در اینجا بسیار حیاتی است؛ لنگر ایدههای انتزاعی را به شغل واقعی دانشجو متصل میکند تا دانش در ذهن تثبیت شود. برای مثال، عامل ممکن است توضیح دهد که «Schema-on-write انبار داده شماست و Schema-on-read دریاچه داده خواهد بود». نمره اولیه حتی اگر پاسخ بعداً اصلاح شود، حفظ میگردد؛ این باعث میشود دانشجو سوزش نمره ۱.۶ از ۵ را حس کند، و دقیقاً در همین نقطه است که یادگیری واقعی رخ میدهد. هوش مصنوعی در اینجا زمانی بیشترین ارزش را دارد که پاسخ را پنهان (Withholding) کند و اجازه دهد انسان برای یافتن جواب تلاش کند.
مرحله ۴: برگه تکصفحهای (/one-pager)
یادداشتهای مفصل برای شب امتحان بیش از حد طولانیاند و باعث سردرگمی میشوند. مهارت one-pager یادداشتهای یک ماژول را در یک اسکریپت تکصفحهای A4 تقطیر میکند. سپس دانشجو این اسکریپت را با استفاده از یک کد رنگی سه-رنگه به صورت دستنویس مینویسد تا اطلاعات در حافظه کدگذاری شوند:
- سیاه: اسکلت مطالب و حقایق «همواره درست» و بنیادی.
- آبی: تعاریف، توضیحات تکمیلی و مثالها.
- قرمز: قلابهای مربوط به امتحان، نکات حساس ارزیابی و هشدارها.
اجزای چیدمان صفحه به این صورت است:
- ایده بزرگ (The Big Idea): یک بخش کادربندی شده و مرکزی که مفهوم اصلی و جامع را در ۱ تا ۳ جمله میگنجاند.
- ناحیه ۱ (Zone 1): بخشهای دارای عنوان با نکات سیاه/آبی/قرمز و جداول مقایسهای برای دستهبندی سریع مطالب.
- قلاب ارزیابی (نوار قرمز پایین): شامل نام ارزیابی، تعداد کلمات/فرمت مورد نیاز، درصد نمره، تاریخ تحویل و SLOهای مرتبط.
- پنج مورد ضروری (The Five Essentials): لیستی از ۵ برداشت کلیدی، کوتاه و حیاتی که نباید فراموش شوند.
در مورد ماژول ۲ درس BDA، فصلهای انتزاعی به اسکریپتی تبدیل شدند که «ایده بزرگ» آن این بود: «از استراتژی منبعیابی کن، سپس دادههای خام را با سرعت مناسب به دریاچه وارد کن». برداشتهای کلیدی شامل تفاوت بین Lake (schema-on-read) و Warehouse (schema-on-write) و مناطق پذیرش داده (Source -> Transient -> Raw) بود. چون این مهارت قلابها را مستقیماً از README مرحله ۱ استخراج میکند، برگه مرور همیشه دقیقاً به چیزی اشاره میکند که قرار است نمره بگیرد. دستنویس کردن، مرحله حیاتی کدگذاری است؛ AI اسکریپت را میسازد، اما انسان باید آن را با دست اجرا کند تا پیوند عصبی برقرار شود.
مرحله ۵: اجرای ارزیابیها
هر چهار هفته، یادداشتهای تحصیلی باید به یک خروجی قابل تحویل تبدیل شوند. این فرآیند در سه مرحله مجزا مدیریت میشود تا نتیجهای حرفهای، دقیق و تکرارپذیر حاصل شود.
سازماندهی وظایف: مهارت gh-issue-creator یک برنامه مارکداون را به مجموعهای از Issueهای گیتهاب تبدیل میکند، شامل اپیکهای ماژول و تسکهای ارزیابی. هر Issue به شدت محدود شده و دارای بخش «هدف» (Goal) و «پذیرش» (Acceptance) است. این محدودیت مانع از منحرف شدن عامل اجراکننده شده و ردیابی بوروکراتیک را به یک افسار کاربردی تبدیل میکند تا هر تسک دقیقاً طبق برنامه پیش برود.
الگوی اجرای V2: ارزیابیها به جای مستنداتی پر از جایگاههای خالی (Placeholder)، به صورت نوتبوکهای قابل اجرا (Runnable Notebooks) تحویل داده میشوند. ساختار پروژه از یک الگوی مخزن (Repo pattern) سختگیرانه پیروی میکند:
dataset/: اسکریپتهای دانلود دادهها و فایلهای CSV ثبت شده.code/: منطق برنامهنویسی پاک، بهینه و قابل اجرا.executed notebook/: نوتبوکهایی که خروجیهای نهایی در آنها جاسازی شده است.outputs/: معیارها (Metrics) و نمودارهای تحلیل نهایی.
این رویکرد، تکالیف دانشگاهی را به یک پورتفولیوی عمومی و حرفهای تبدیل میکند. مشابه این رویکرد در محیطهای صنعتی دیده میشود، جایی که بهینهسازی گردش کار با کمک AI توانسته است زمانهای طولانی بررسی کیفیت را به شدت کاهش دهد. نمونهها شامل مدل ریزش مشتریان Telco ساخته شده با PySpark MLlib، رگرسیون کیفیت شراب و طبقهبندی احساسات است که همگی حاوی اعداد واقعی اجرا شده هستند، نه برنامههایی که صرفاً توصیف میکنند چه اتفاقی خواهد افتاد.
ممیزی پیش از تحویل: در نهایت، مهارت assessment-checker یک ممیزی نهایی برای موارد زیر انجام میدهد:
- تطابق ساختاری کامل با دستورالعمل ارزیابی (Assessment Brief).
- رعایت تلورانس تعداد کلمات (کم یا زیاد نبودن بیش از حد).
- تطابق دقیق ارجاعات درونمتنی با لیست منابع در انتهای سند.
- بررسیهای سریع وب برای اطمینان از اینکه هر نویسنده، سال و محل انتشار منبع واقعی است و توهم AI نبوده است.
این ابزار مشکلات را به صورت «حیاتی»، «جزئی» یا «تأیید شده» علامتگذاری میکند، پیش از آنکه مصحح انسانی سند را ببیند و نمره دهد.
بستن حلقه بازخورد
برای گنجاندن دادههای زنده کلاس، یک transcript-generator با استفاده از whisper.cpp روی سختافزارهای اپل (Apple Silicon)، ضبطهای صوتی سخنرانیها را به صورت آفلاین به متن و زیرنویس تبدیل میکند. این یادداشتهای قابل جستجو دوباره به مرحله ۲ بازمیگردند و تضمین میکنند کلاسی که در آن شرکت شده، تبدیل به منبعی شود که خط لوله تلخیص و بازخوانی را تغذیه کند و شکافهای بین متن کتاب و سخنان استاد را پر کند.
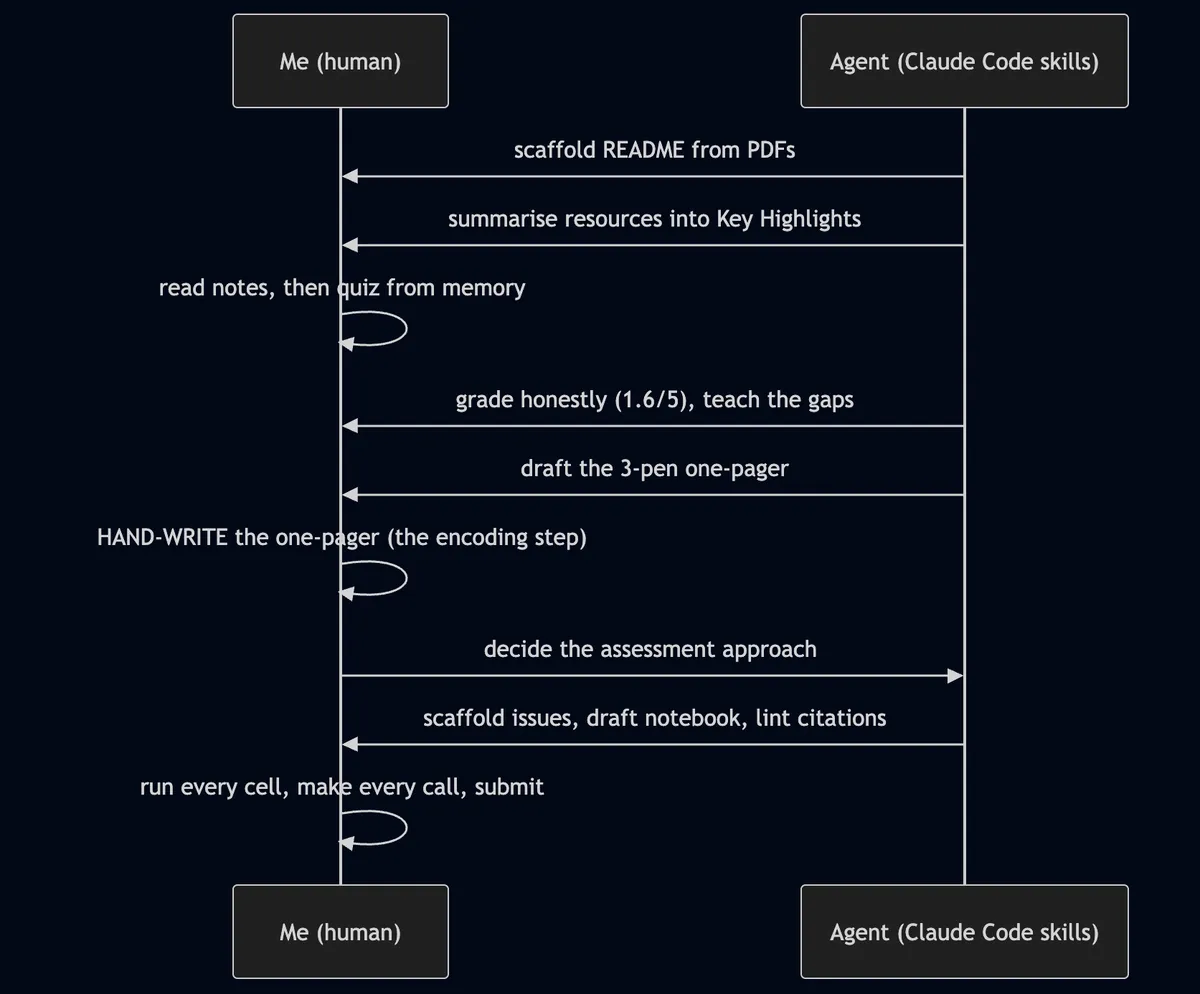
تقسیم حیاتی مسئولیتها
این سیستم به گونهای طراحی شده که یک شتابدهنده باشد، نه جایگزینی برای تفکر. تقسیم کار به شرح زیر است:
| وظیفه عامل (AI) | وظیفه انسان |
|---|---|
| ساخت Scaffold برای README از روی PDFها | تصمیمگیری درباره اولویتها |
| تلخیص منابع به یادداشتهای ارجاعشده | خواندن یادداشتها و بازخوانی از حافظه |
اجرای /active-recall و نمرهدهی صادقانه |
بازیابی پاسخها و تحمل نمره ۱.۶ از ۵ |
| پیشنویس اسکریپت تکصفحهای سه-رنگ | دستنویس کردن برگه A4 |
| ساخت Issueها و بررسی ارجاعات (Linting) | اجرای هر سلول کد و تصمیمات آکادمیک |
| پیشنویس ساختار نوتبوک | ارسال اثر نهایی |
درسهای آموخته شده برای یادگیری با کمک AI
چند درس فنی کلیدی از این گردش کار استخراج شد:
- مهارتها به جای پرامپتها: یک پرامپت تکباره موقتی است، اما یک مهارت یک قرارداد محدود است. نویسنده از یک الگوی glob مانند
[0-9][0-9][0-9][0-9]-T[0-9]/*برای یافتن دروس استفاده میکند تا سیستم مستقل از ترم باشد و در تغییر سمسترها باقی بماند و نیاز به بازنویسی نباشد. - Issueهای کوچک به جای پرامپتهای طولانی: یک Issue محدود در گیتهاب با معیارهای پذیرش واضح، برای کنترل یک LLM بسیار برتر از یک پاراگراف طولانی دستورالعمل است چون تمرکز عامل را حفظ میکند.
- کدگذاری فیزیکی: عمل دستنویس کردن اسکریپت عامل، واحد اصلی حافظه است. AI پیشنویس را میسازد، اما دست، عمل کدگذاری را انجام میدهد و این اتصال فیزیکی باعث تثبیت یادگیری میشود.
- بازخورد صادقانه: سیستمی که نمره مردود (مثلاً ۱.۶ از ۵) میدهد و شکافها را آموزش میدهد، بسیار ارزشمندتر از سیستمی است که تعریفهای توخالی یا چاپلوسی ارائه میدهد.
با سیستماتیک کردن تدارکات یک مدرک ارشد، این دانشجو یک سناریوی احتمالی «فرسودگی شغلی» (Burnout) را به یک خط لوله تکرارپذیر تبدیل کرد. سیستم کامل، شامل مهارتها و ارزیابیهای اجرا شده، در github.com/lfariabr/masters-swe-ai و مهارت ساخت Issue در github.com/lfariabr/gh-issue-creator در دسترس است.
گام بعدی شما
- بررسی مخزن گیتهاب پروژه در
github.com/lfariabr/masters-swe-aiبرای کپی کردن ساختار مهارتها. - جایگزینی مطالعهٔ غیرفعال با ابزارهای «بازخوانی فعال» (Active Recall) برای افزایش ماندگاری مطالب.
- پیادهسازی سیستم دستنویس رنگی برای تبدیل خروجیهای AI به حافظه بلندمدت.
اما معماری پشت این سیستم، یعنی تبدیل پرامپت به «مهارت» (Skill)، در مقیاسهای بزرگتر چه نتایجی دارد؟ تحلیل ما دربارهی پروتکل MCP و آینده عاملهای تخصصی را دنبال کنید.



گفتگو