
تصور کنید پژوهشگری هستید که باید پاسخ یک سؤال تخصصی را از میان هزاران سند اسکنشده و جداول پیچیده مربوط به ده سال پیش پیدا کند. این کابوس دادهای، نقطهای بود که بایر (Bayer) برای حل آن، سامانه PRINCE را در اوایل سال ۲۰۲۴ معرفی کرد. پژوهشگران پیشبالینی بایر اکنون با استفاده از این سیستم عاملمحور (Agentic AI)، گزارشهای پیچیدهی چندین دهه را پیمایش میکنند. بایر با عبور از جستوجوهای سادهی کلیدواژهای، به سراغ یک معماری چند-عاملی RAG رفت تا هزارتوی پراکنده دادهها را به یک رابط مکالمهای بصری و پویا تبدیل کند.
به گزارش منابع فنی، این شرکت با استفاده از مدل تولید بازیابیافزا (RAG) — شبیه دانشآموزی که قبل از جواب دادن، اول کتاب درسی را باز میکند و از آن نقل میآورد — توهمات مدل را به حداقل رساند. همانطور که در تحلیلهای قبلی ما دربارهی امنیت مدلهای بازمتن اشاره کردیم، کنترل دقیق روی منبع داده، تنها راه رسیدن به پاسخهای قابلاعتماد در محیطهای حساس است.
کشف داروهای پیشبالینی بهذات پیچیده و بهشدت دادهمحور است. تیمهای پژوهشی بایر پیش از این بهطور تاریخی با «سیلوهای داده» (جدا بودن اطلاعات در سیستمهای مختلف) و ابزارهای صلب جستوجوی بولی (Boolean) میجنگیدند که نمیتوانستند ظرافتهای پرسشهای علمی را درک کنند. پژوهشگران با موانع بزرگی روبرو بودند؛ از جمله پراکندگی اطلاعات در سیستمهای نامتجانس و نیاز به تحلیلهای دستی زمانبر برای گردآوری بینشها از چندین سند مختلف. این تلاشهای دستی، زمان ارزشمند پژوهشگران را از فعالیتهای علمی محوری دور میکرد. این موضوع در کنار تکامل سریع مدلهای زبانی، باعث شده تا در برخی حوزههای تخصصی، عاملهای هوش مصنوعی بتوانند در تحلیلهای پیچیده زیستی از متخصصان انسانی پیشی بگیرند. طبق یک گزارش فنی در ۲۱ ژوئن ۲۰۲۶ از وبسایت martinfowler.com، سرمایهگذاری این شرکت در هوش مصنوعی مولد منجر به یک تکامل مرحلهبندی شده شد: از یک ابزار ساده «جستوجو» (Search) به یک سیستم «پرسش» (Ask) و در نهایت به فاز فعلی یعنی «اجرا» (Do)، جایی که AI دیگر فقط جواب نمیدهد، بلکه بهعنوان یک دستیار پژوهشی فعال عمل میکند.
تکامل از جستوجو تا اجرا
سامانه PRINCE برای پاسخ به نیازهای صنعت داروسازی در جهت افزایش کارایی و نوآوری در توسعه پیشبالینی، در سه گام استراتژیک رشد کرد:
- جستوجو (Search): این درگاه اولیه بر تجمیع هزاران گزارش مطالعه غیربالینی و متادیتاهای ساختاریافته از دامنههای مختلف پیشبالینی تمرکز داشت. در این مرحله، هدف تبدیل دادهها به قالبی قابل جستوجو بود که عمدتاً از متادیتاهای ساختاریافته بهره میبرد.
- پرسش (Ask): در این فاز، یک سیستم پرسش و پاسخ مبتنی بر RAG معرفی شد. این قابلیت به پژوهشگران اجازه داد تا مستقیماً از دادههای نامنظم، از جمله PDFهای قدیمی اسکنشده، از طریق طرح سؤالات به زبان طبیعی، بینشهای مورد نیاز خود را استخراج کنند.
- اجرا (Do): فاز فعلی که در آن PRINCE به عنوان یک دستیار پژوهشی فعال تعریف میشود که قادر به اجرای وظایف پیچیده است. این امر از طریق سیستمهای چند-عاملی (Multi-agent) محقق شده که میتوانند گردشهای کاری (Workflows) را سازماندهی کرده و از فعالیتهایی مانند پیشنویس اسناد رگولاتوری پشتیبانی کنند.
موتور ارکستراسیون و مهندسی زمینه
این سامانه روی LangGraph بنا شده و از طریق یک اپلیکیشن FastAPI سرویسدهی میشود. بایر بهجای اینکه پرامپت مدل زبانی (LLM) را به عنوان یک ظرف واحد در نظر بگیرد، از روشی به نام «مهندسی زمینه» (Context Engineering) استفاده میکند تا اطلاعات خاص را به عاملهای متخصص هدایت کند. این استراتژی از «آلودگی زمینه» (Context Pollution) جلوگیری میکند؛ مشکلی که در نسخههای اولیه باعث میشد هدایت و ارزیابی مدل دشوار شود. مهندسی زمینه بهطور دقیق تعریف میکند که هر عامل چه چیزی دریافت کند: «زمینه برنامهریزی» برای عامل تفکر و برنامه، «زمینه بازیابی» برای پژوهشگر، «زمینه شواهد» برای عامل بازتاب و «زمینه ترکیب» برای نویسنده.
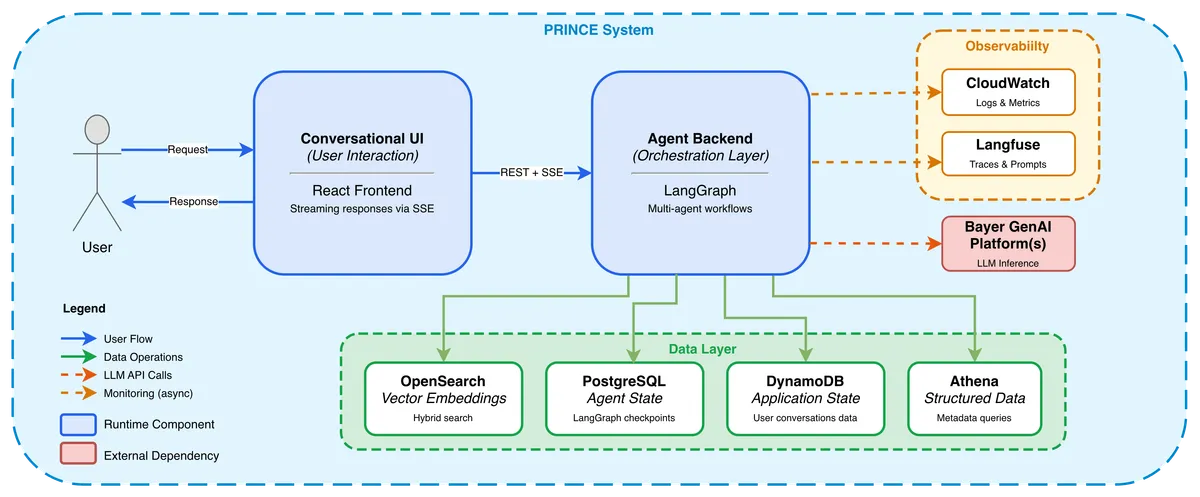
کاربر درخواست خود را از طریق رابط کاربری مکالمهای ساخته شده با React ارسال میکند. سپس لایهی ارکستراسیون، درخواستها را از طریق چندین مرحله متمایز هماهنگ میکند: شفافسازی هدف، برنامهریزی، پژوهش، اعتبارسنجی و در نهایت نوشتن. این ارکستراسیون مانند یک «هارنس» (Harness) یا مهار عمل میکند و مرزهای ابزار، تداوم وضعیت (State Persistence) و حلقههای اعتبارسنجی را تعریف میکند. برای تضمین قابلیت اطمینان، سیستم وضعیت عاملها را در PostgreSQL با استفاده از یک Checkpointer در LangGraph و وضعیت کلی برنامه را در DynamoDB مدیریت میکند.
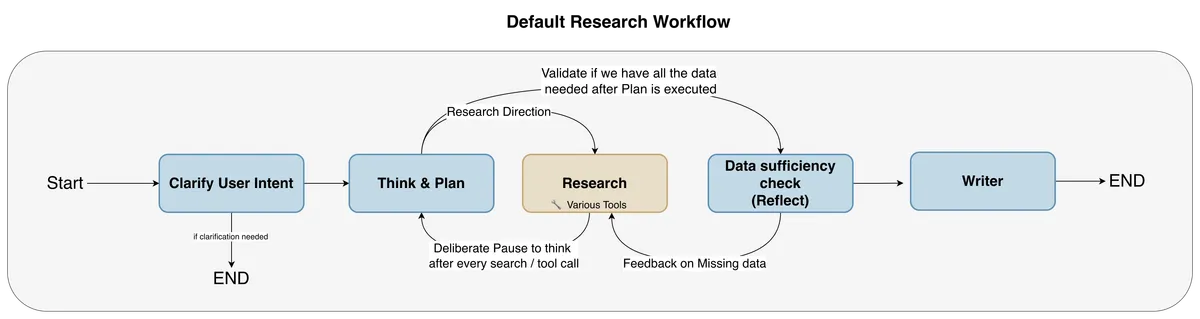
گردش کار چندعاملی
قلب تپنده PRINCE، توالی از عاملهای تخصصی است که «بازتاب پردازشی» و «بازتاب دادهای» را انجام میدهند:
- عامل شفافسازی هدف (Clarify User Intent Agent): این عامل به عنوان اولین خط دفاعی در برابر ابهام عمل میکند. با گسترش سیستم به حوزههای سمشناسی و فارماکولوژی، پرسشهای ساده اغلب مبهم میشدند. این عامل بهطور فعال سؤالات تکمیلی میپرسد تا دامنه یا نوع داده را دقیقاً مشخص کند و اطمینان حاصل کند که سیستم پرسوجو را با محدودیتهای لازم ارتقا میدهد. همچنین بر اساس هدف تحلیل شده، پیشنهاداتی برای منابع (AI-assisted source recommendations) ارائه میدهد که کاربر میتواند آنها را بپذیرد یا رد کند. این مکانیزم «شکست سریع» (Fail-fast) از اتلاف منابع روی پرسوجوهای مبهم جلوگیری میکند.
- عامل تفکر و برنامهریزی (Think & Plan Agent): با الهام از ابزار Think شرکت Anthropic، این عامل فضایی اختصاصی برای استدلال قبل از اقدام فراهم میکند. این همان «بازتاب پردازشی» است؛ یعنی ارزیابی اینکه آیا عامل در مسیر درست به سمت هدف حرکت میکند و آیا تراژکتوری (مسیر) صحیح است یا خیر. این مرحله برای وظایف پیچیده (مثلاً گردشهای کاری با ۵۰ مرحله) ضروری است. همچنین در انتخاب ابزار حیاتی است؛ زیرا وقتی تعداد ابزارها زیاد شد، مدل در تشخیص مرزهای همپوشان (مثلاً تفاوت بین پرسوجوی متادیتای ساختاریافته در مقابل گزارشهای نامنظم) دچار مشکل میشد. مرحله تفکر به مدل اجازه میدهد صریحاً استدلال کند که کدام ابزار با هدف کاربر مطابقت بیشتری دارد.
- عامل پژوهشگر (Researcher Agent): گردآورنده اصلی اطلاعات است که به عنوان هماهنگکننده برای سلسلهمراتبی از زیر-عاملهای تخصصی دامنه عمل میکند. این تکامل مانع از آن میشود که یک عامل تکگانه (Monolithic) بخواهد ابزارهای همپوشان در دامنههای مختلف را مدیریت کند؛ مانند مطالعات سمشناسی دوز مکرر، بستههای فارماکولوژی ایمنی серде-عروقی یا جداول دادههای تودهای تجمیعشده. هر عامل دامنه، مجموعه ابزار خاص خود و دستورالعملهای پرامپت سفارشی دارد که مدل دادهای آن حوزه و جداول معتبر را کدگذاری میکند.
RAG پیشرفته و تبدیل متن به SQL
خط لولهی RAG در بایر برای حساسیتهای بالای دارویی طراحی شده است. این سیستم PDFها را — که اغلب اسناد اسکنشده با جداول پیچیده هستند — پردازش کرده و در Amazon S3 ذخیره میکند. سپس با استفاده از استراتژیای که زمینه علمی را حفظ میکند، آنها را تکهبندی (Chunking) کرده و در Amazon OpenSearch Service ایندکس میکند. در حین جذب دادهها، تکهها با متادیتاهای سطح مطالعه و سطح بخش از Amazon Athena (مانند ID مطالعه، ترکیب، گونه، مسیر تجویز، صفحه و بخش والد) غنیسازی میشوند.
وقتی کاربر سؤالی میپرسد — برای مثال در مورد یافتههای بالینی مانند «پیلورکشن» (piloerection)، «آتکسی» (ataxia)، «چشمان نیمهبسته» یا «مدفوع شل» در مطالعه T123456-2 — سیستم یک فرآیند چندمرحلهای را اجرا میکند:
- استخراج کلیدواژه و فیلتر: یک LLM کلیدواژههای مرتبط را استخراج میکند و بهطور همزمان با استفاده از Few-shot prompting (با مثالهای مختلف از جایگشتها و ترکیبات)، یک فیلتر متادیتا (مثلاً
eq(study_id, T123456-2)) تولید میکند. - گسترش پرسوجو (Query Expansion): یک مدل کوچکتر و سریعتر، ۵ پرسوجوی مشابه معنایی تولید میکند تا تغییرات ترمینولوژی را پوشش دهد. برای مثال، ممکن است عبارت «goosebumps» را برای piloerection یا «watery stools» را برای مدفوع شل جایگزین یا اضافه کند.
- جستوجوی ترکیبی وزندار (Weighted Hybrid Search): سیستم جستوجوهای موازی در OpenSearch انجام میدهد. وزن ۰.۷ به جستوجوی شباهت برداری معنایی (kNN) و ۰.۳ به جستوجوی کلیدواژهای اختصاص مییابد تا درک مفهومی با تطبیق دقیق عبارات متوازن شود.
- رتبهبندی مجدد (Reranking): یک مدل cross-encoder از نوع bge-reranker-large، حدود ۲۰ تکه اولیه را ارزیابی کرده و ۷ تکه برتر را بر اساس سؤال اصلی برای استفاده به عنوان زمینه (Context) در LLM انتخاب میکند.
برای دادههای ساختاریافته، PRINCE از ابزار Text-to-SQL از طریق Amazon Athena برای پرسوجوهایی که نیاز به تجمیع یا فیلتر دقیق دارند استفاده میکند؛ مانند «۵۰ مطالعه نمونه که روی موش (RAT) انجام شده را لیست کن» یا بازیابی نتایج عددی سنجش برای گروههای دوز.
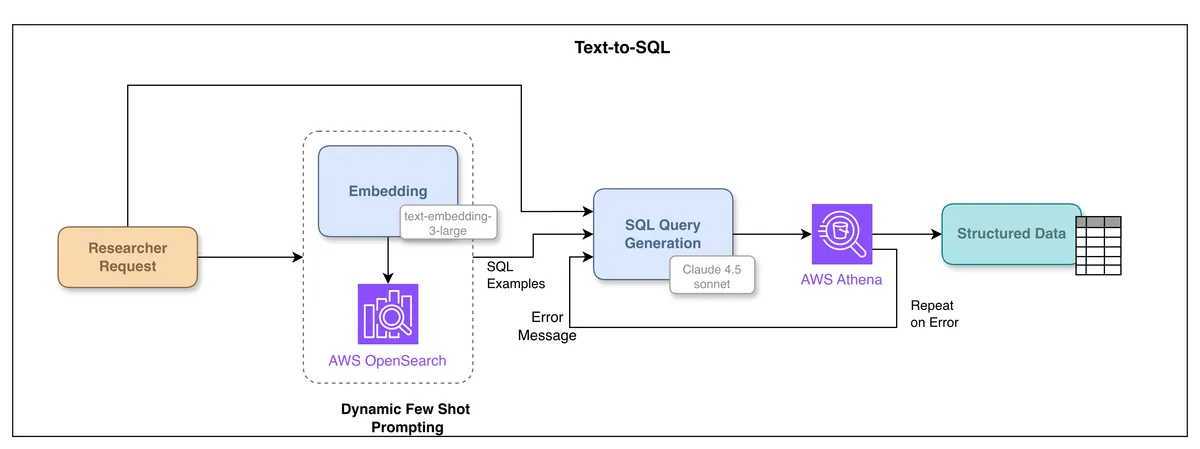
برای بهبود دقت SQL، سیستم از Few-shot prompting دینامیک استفاده میکند. این سیستم مثالهای SQL مرتبط را از یک «لایه معنایی» در یک پایگاه داده برداری بازیابی کرده و تنها اجزای مورد نیاز اسکیما را به زمینه تزریق میکند. برای محافظت از یکپارچگی دادهها، فقط پرسوجوهای SELECT مجاز هستند و DELETE، INSERT یا UPDATE بهطور صریح مسدود شدهاند. اگر پرسوجویی به دلیل خطای سینتکس یا اسکیما شکست بخورد، سیستم خطا و زمینه اصلی را به مدل بازمیگرداند و تا سه بار برای تولید پرسوجوی اصلاحشده تلاش میکند پیش از آنکه شکست را گزارش دهد.
حلقههای اعتماد و اعتبارسنجی
بایر برای جلوگیری از توهم (Hallucination) — زمانی که مدل با اطمینان چیزی میگوید که وجود ندارد — سه حلقه بازتاب (Reflection) مجزا را پیادهسازی کرده است:
۱. بازتاب پردازشی (Process Reflection): توسط عامل تفکر و برنامه مدیریت میشود تا بررسی کند آیا گردش کار در مسیر درست است و خطاهای احتمالی در توالی ابزارها را شناسایی کند.
۲. بازتاب دادهای (Data Reflection): توسط عامل بازتاب (Reflection Agent) مدیریت میشود. این عامل بررسی میکند که آیا شواهد جمعآوری شده کافی است یا خیر، و این کار را با مقایسه زمینه بازیابی شده در برابر پرسوجوی اصلی انجام میدهد. اگر خلأیی یافت شود، سؤالات تکمیلی تولید کرده و گردش کار را برای بازیابی بیشتر به عامل تفکر و برنامه بازمیگرداند.
۳. بازتاب پیشنویس (Draft Reflection): توسط عامل نویسنده (Writer Agent) که مسئول ترکیب شواهد است، انجام میشود. این عامل تضمین میکند که خروجی بر اساس زمینه ارائه شده باشد، فرمتهای لازم (جداول، نقاط گلولهای) را رعایت کند و با استانداردهای تخصصی دامنه مطابقت داشته باشد. این حلقه بازبینی داخلی، بخشهای گمشده، جداول متناقض یا شکافهای ترکیبی را بررسی میکند.
اعتماد کاربران با «ارجاعات دانهریز» (Granular Citations) تقویت شده است؛ کاربران میتوانند روی هر جمله قرار بگیرند تا نقلقول دقیق، شماره صفحه و لینک بازگشت به سند اصلی را مشاهده کنند. برای تابآوری بیشتر، سیستم از Fallbackهای LLM استفاده میکند؛ اگر ارائهدهنده اصلی پس از چندین تلاش شکست بخورد، سیستم بهطور خودکار از طریق یک End-point واحد به مدلهای جایگزین از OpenAI، Anthropic یا Google سوئیچ میکند. تلاشهای مجدد (Retries) هم در سطح فراخوانی تک-LLM و هم در سطح گرههای منطقی پیاده شدهاند.
ارزیابی و نظارت
پایداری سیستم از طریق یک «هرم تست» از ارزیابیها حفظ میشود:
- ارزیابیهای مجموعهداده (Dataset Evaluations): هر زمان که تغییرات قابلتوجهی در پرامپتها یا مدلها ایجاد شود، این تستها فعال میشوند. آنها از پاسخهای مرجع منتخب در Langfuse برای اندازهگیری «وفاداری» (پشتیبانی توسط زمینه)، «ارتباط پاسخ»، «ارتباط زمینه»، «دقت پاسخ» (مقایسه با حقیقت زمینی/Ground Truth) و «شباهت معنایی» استفاده میکنند.
- ارزیابیهای ترافیک زنده (Live Traffic Evaluations): کارهای دستهای (Batch jobs) روزانه روی پرسوجوهای واقعی کاربران انجام میشود تا توهمات در محیط تولید شناسایی شده و عملکرد سیستم روی پرسوجوهای متنوع زنده نظارت شود.
- مشاهدهپذیری (Observability): سلامت کلی سیستم از طریق Cloudwatch رصد میشود، در حالی که Langfuse ردپاهای (Traces) دقیق ترافیک تولید را برای عیبیابیهای عمیق فراهم میکند.
بهبود متادادهها
از آنجا که متادادههای تاریخی در Athena به دلیل مهاجرتهای سیستمهای قدیمی ممکن است ناقص باشند، بایر ابزاری را با استفاده از «بازشناسی موجودیتهای نامدار» (NER) توسعه داد تا بهطور خودکار شناسههای مطالعه، نام ترکیبات، گونهها، مسیرهای تجویز و اطلاعات دوز را از PDFها استخراج کند. به این یادداشتها امتیاز اطمینان (Confidence Score) اختصاص مییابد؛ دادههای با اطمینان بالا بهطور خودکار پایگاه داده را بهروز میکنند، در حالی که دادههای با اطمینان پایین برای بررسی انسانی علامتگذاری میشوند. این کار تضمین میکند که اطلاعات «استاندارد طلایی» موجود در گزارشهای PDF در متادادههای ساختاریافته منعکس شوند.
تحلیل تحریریه
سیستم PRINCE نمایانگر گذار از «چتباتها» به «مهندسی هارنس» (Harness Engineering) است. مهمترین دستاورد بایر، رد افسانهی «پنجره زمینه بزرگتر» (Bigger Context Window) است. آنها بهجای اینکه دادههای بیشتر را در یک پرامپت بچپانند، یک داربست سخت — یعنی هارنس — ساختند که دقیقاً کنترل میکند هر عامل چه اطلاعاتی را در چه زمانی ببیند.
برای حوزه هوش مصنوعی سازمانی، این ثابت میکند که قابلیت اطمینان در محیطهای رگولاتوری (قانونمند) از پرامپتهای بهتر حاصل نمیشود، بلکه نتیجهی ارکستراسیون قطعی (Deterministic Orchestration) است. بایر با جداسازی بازتاب پردازشی از بازتاب دادهای، شکست رایج در سیستمهای عاملمحور را حل کرد؛ شکستی که در آن ربات مراحل درست را طی میکند اما به دلیل دادههای ضعیف، به پاسخ غلط میرسد. اکنون هر عامل (پژوهشگر، بازتاب، نویسنده) را میتوان بهطور مجزا ارزیابی و بهبود بخشید.
برای بهینهسازی بیشتر این معماری، توسعهدهندگان باید قابلیتهای مدلهای استدلالی جدید (مانند سری o) را رصد کنند تا ببینند کدام بخشهای هارنس دستی «تفکر و برنامه» را میتوان در نهایت به قابلیتهای ذاتی مدل سپرد. با این حال، در پژوهشهای رگولاتوری، کنترل صریح بر فرآیندهای بازیابی، بازتاب و تأیید همچنان ضروری است.
گام بعدی شما
- بررسی معماری LangGraph برای پیادهسازی جریانهای کاری چندمرحلهای و مدیریت وضعیت.
- مطالعه روشهای Hybrid Search برای ترکیب جستوجوی معنایی و کلیدواژهای با وزنهای متغیر.
- پیادهسازی لایههای Reflection (پردازشی و دادهای) برای کاهش نرخ توهم در سیستمهای RAG سازمانی.
اما چالش اصلی همواره مدیریت هزینههای استنتاج در مقیاس سازمانی است — به تحلیل ما دربارهی بهینهسازی هزینه GPU مراجعه کنید.



گفتگو