
دوران صرف ساعتها وقت برای استخراج ویژگیهای دستی از دادههای جدولی به پایان رسیده است. تصور کنید مدلهای یادگیری ماشین بتوانند بدون هیچ آموزشی روی دادههای شما، تنها با دیدن چند نمونه، پیشبینیهای دقیقی ارائه دهند.
طبق اعلام گوگل در ۳۰ ژوئن ۲۰۲۶، مدل TabFM بهعنوان یک مدل بنیادی (Foundation Model) معرفی شده است که پیشبینیهای طبقهبندی (Classification) و رگرسیون (Regression) را تنها در یک گام پیشرو (Forward Pass) و بهصورت Zero-shot انجام میدهد.
چالش دادههای جدولی و ضرورت تغییر
برای دههها، صنعت بر الگوریتمهای نظارتشدهی مبتنی بر درخت مانند XGBoost، Random Forests و AdaBoost تکیه کرده است. با وجود استواری این مدلها، دانشمندان داده مجبور بودند زمان زیادی را صرف «مهندسی ویژگی» (Feature Engineering) کنند تا سیگنالهای قابلاعتماد را از دادههای خام استخراج کنند. دادههای جدولی ستون فقرات زیرساختهای سازمانی هستند و کاربردهایی حیاتی، از شناسایی کلاهبرداریهای مالی تا پیشبینی ریزش مشتریان را مدیریت میکنند.
به نقل از گزارش research.google، چرخه سنتی توسعه مدلها یک گلوگاه عملیاتی ایجاد میکند. برازش مدلی مانند XGBoost صرفاً یک دستور ساده مانند .fit() نیست؛ بلکه بهناچار نیازمند تلاشهای دستی خستهکننده در بهینهسازی ابرپارامترها (Hyperparameter Optimization) است. این فرآیند اغلب بخش اعظم وقت یک دانشمند داده را میبلعد تا صرفاً بتواند یک سیگنال معنادار از دادههای خام استخراج کند.
مدل TabFM با تغییر پارادایم، پیشبینی جدولی را به یک مسئله یادگیری در بستر متن (In-Context Learning یا ICL) تبدیل میکند. این رویکرد دقیقاً مشابه تکامل مدلهای زبانی بزرگ (LLM) است که وظایف جدید را از طریق مثالها و دستورات موجود در ورودی یاد میگیرند، بدون اینکه وزنهای زیربنایی مدل تغییر کند. این تلاش برای رسیدن به یک مدل جامع، پاسخی به چالشهایی است که پیشتر در تحلیل بنبستهای جستوجو برای مدلهای جامع دادههای جدولی مورد بررسی قرار گرفته بود.
در این ساختار، TabFM بهجای بهروزرسانی وزنها برای هر مجموعه داده جدید، کل مجموعه داده — شامل مثالهای آموزشی تاریخی و ردیفهای هدف برای آزمون — را بهعنوان یک «پرامپت» واحد دریافت میکند. این مدل روابط بین ستونها و ردیفها را در لحظه استنتاج (Inference) تفسیر میکند و نیاز به آموزش دستی مدل و مهندسی ویژگیهای پیچیده را کاملاً از بین میبرد.
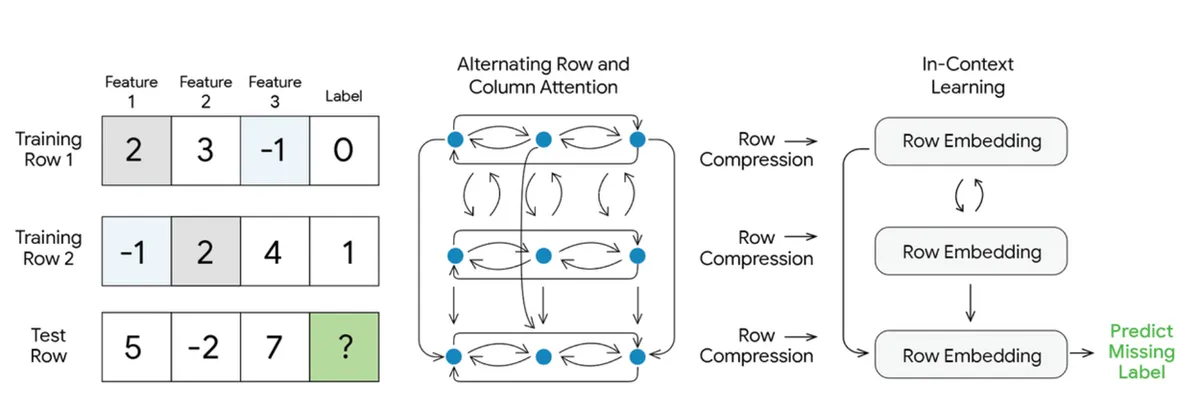
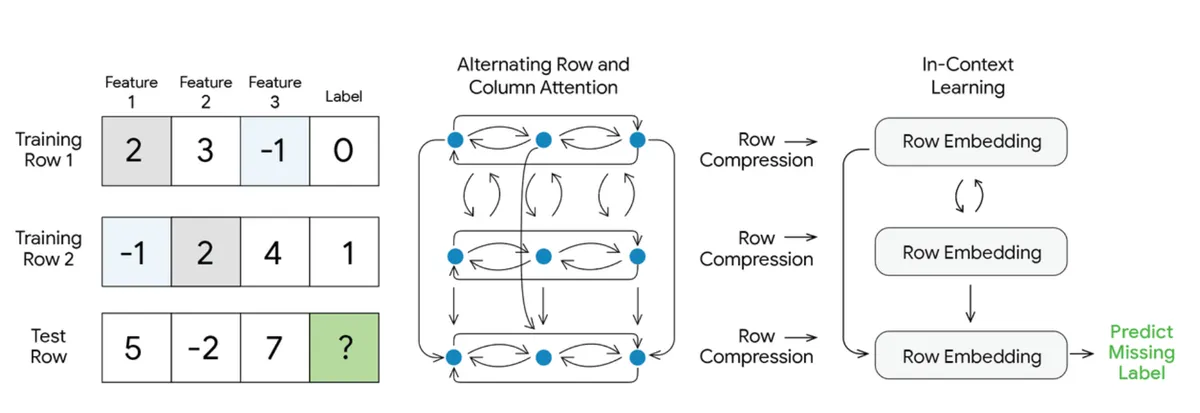
جزئیات فنی: معماری ترکیبی
برای مدیریت ماهیت دوبعدی و بدون ترتیب جداول — جایی که جابهجایی ردیفها یا ستونها معنای داده را تغییر نمیدهد — TabFM نقاط قوت معماریهای TabPFN و TabICL را ترکیب کرده است. مدلهای زبانی استاندارد توالیهای تکبعدی و مرتب را پردازش میکنند، اما دادههای جدولی ذاتاً متفاوتاند.
بر اساس مستندات گوگل، این مدل از سه مکانیسم اصلی برای پیشبینی مقیاسپذیر استفاده میکند:
- توجه متناوب ردیفی و ستونی: دادههای خام از یک ماژول توجه (Attention) چندلایه عبور میکنند. مشابه رویکرد TabPFN، این مرحله بهصورت متناوب توجه را روی هر دو بُعد ستونها (ویژگیها) و ردیفها (نمونهها) اعمال میکند. با تکرار این توجه متقاطع، مدل بازنماییهای غنیای میسازد که بهطور بومی تعاملات پیچیده و وابستگیهای بین ویژگیها را شناسایی میکند. این زمینه سازی عمیق، همان کار سنگینی را انجام میدهد که در حالت عادی نیازمند مهندسی ویژگیهای دستی بود.
- فشردهسازی ردیفی: پس از این مرحلهی زمینهسازی، اطلاعات غنی حاصل از توجه متقاطع برای هر ردیف مجزا، در قالب یک بردار معنایی (Embedding) متراکم و واحد فشرده میشود.
- ترنسفورمر ICL: یک ترنسفورمر (Transformer) اختصاصی روی این توالی از بردارهای فشرده عمل میکند. با پذیرش رویکرد بسیار بهینه TabICL، اعمال توجه روی این بردارهای فشرده ردیفی — بهجای شبکه خام و فشرده نشده — هزینههای محاسباتی را بهشدت کاهش میدهد. این امر تضمین میکند که گام پیشبینی حتی برای مجموعههای داده بسیار بزرگتر نیز از نظر محاسباتی بهینه باقی بماند.
استراتژی آموزش: دادههای مصنوعی در مقیاس کلان
هوش TabFM حاصل آموزش روی مقیاس بیسابقهای از دادههای مصنوعی است. یکی از موانع اصلی در یادگیری ماشین جدولی، کمبود دادههای صنعتی باکیفیت و بازمتن است. جداول صنعتی اغلب حاوی طرحهای اختصاصی و اطلاعات حساس هستند که دسترسی به آنها را برای پیشآموزش گسترده غیرممکن میکند.
از آنجا که جداول مصنوعی را میتوان به هر اندازه بزرگی تولید کرد، آنها تنها گزینه عملی برای پیشآموزش یک مدل بنیادی در این مقیاس هستند. در نتیجه، گوگل TabFM را کاملاً روی صدها میلیون مجموعه داده مصنوعی آموزش داده است.
این مجموعهدادهها بهصورت پویا با استفاده از مدلهای علّی ساختاری (SCM) تولید شدهاند که طیف گستردهای از توابع تصادفی را در بر میگیرد. این حجم عظیم از تولیدات مصنوعی، توزیعهای متنوع و روابط پیچیده ویژگیها را که در دادههای واقعی جدولی رایج است، شبیهسازی میکند و به مدل اجازه میدهد تا روی جداول واقعی و دیدهنشده تعمیم یابد.
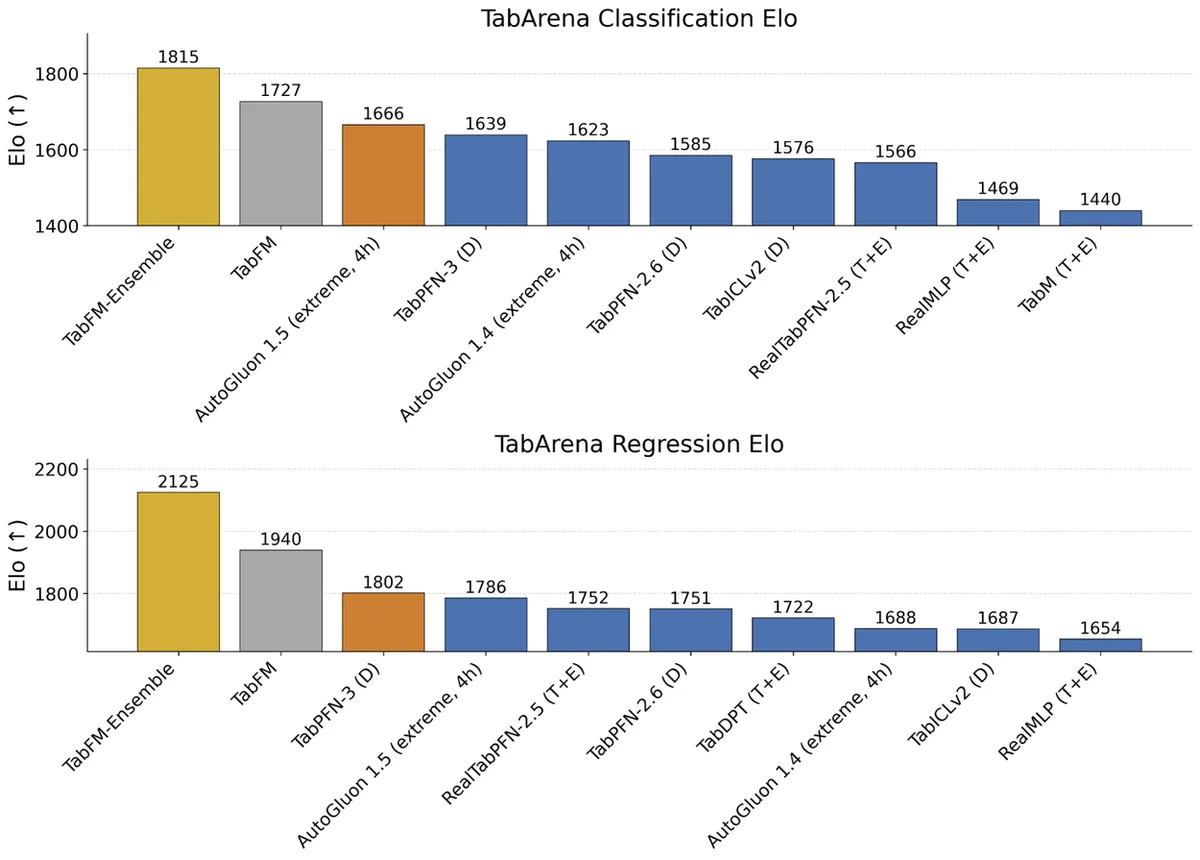
ارزیابی و بنچمارک
در آزمایشهای رودررو و سختگیرانه روی محک TabArena — سیستمی پویا که امتیاز Elo را بر اساس نرخ برد محاسبه میکند — TabFM تواناییهای Zero-shot قدرتمندی نشان داد. این ارزیابی جامع شامل ۳۸ مجموعه داده طبقهبندی و ۱۳ مجموعه رگرسیون بود و حجم نمونهها در آن از ۷۰۰ تا ۱۵۰,۰۰۰ ردیف متغیر بود. این رویکرد ارزیابی پیشرفته، مشابه تغییراتی است که در پروژهی TimeVista برای جایگزینی معیارهای عددی با مدلهای بینایی-زبانی در تحلیل سریهای زمانی مشاهده شد.
گوگل دو پیکربندی متمایز را آزمایش کرد:
- TabFM: نسخه استاندارد و آماده استفاده. این نسخه پیشبینیها را در یک گام پیشرو، بدون هیچگونه تنظیم (Tuning)، اعتبارسنجی متقاطع (Cross-validation) یا بهروزرسانی وزنها تولید میکند.
- TabFM-Ensemble: این گونه با ادغام SVD (تجزیه مقادیر منفرد) و ویژگیهای متقاطع (Cross Features)، عملکرد را ارتقا میدهد. این مدل از یک حلکننده حداقل مربعات غیرمنفی (Non-negative Least Squares) برای محاسبه وزن بهینه یک مجموعه ۳۲-گانه استفاده میکند. همچنین برای وظایف طبقهبندی، از Platt scaling بهعنوان یک گام کالیبراسیون اضافی بهره میبرد.
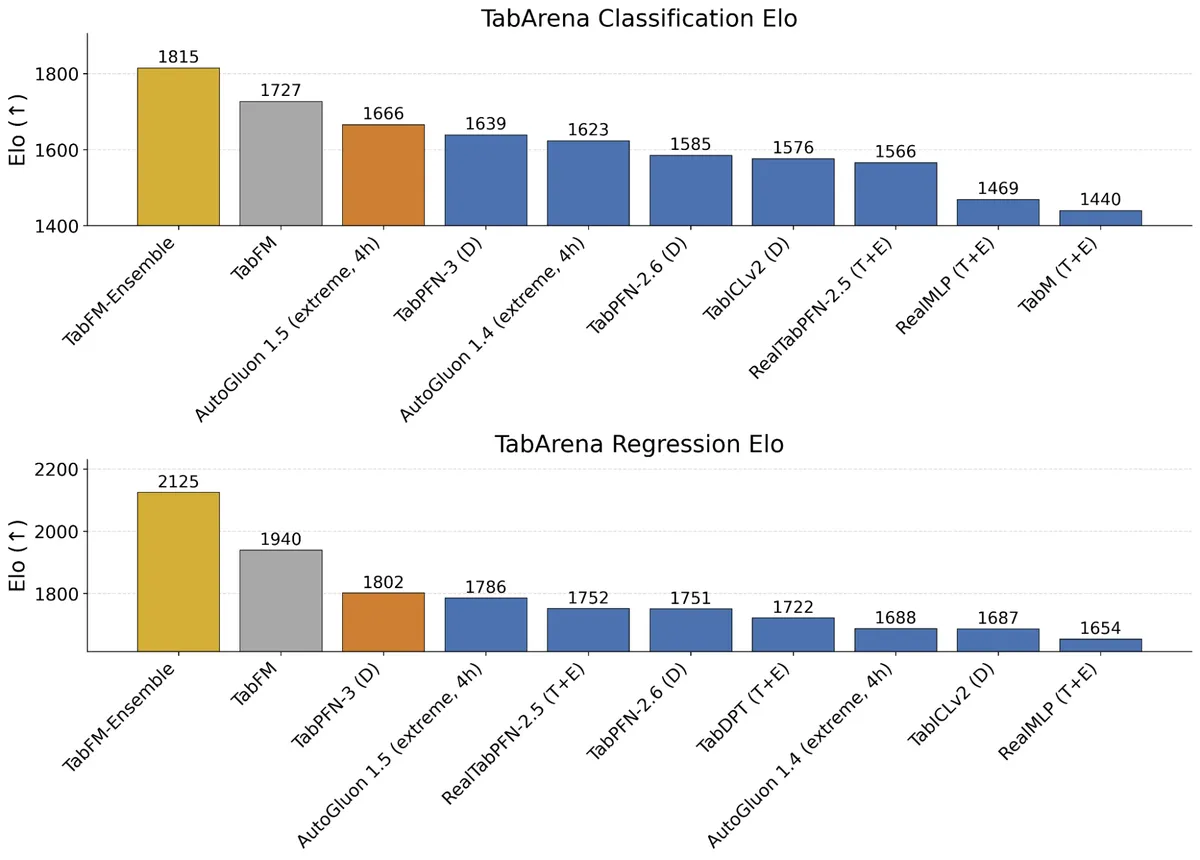
این تحول، فرض فنی قدیمی مبنی بر نیاز به مرحله آموزش اختصاصی و مجزا برای هر مجموعه داده ساختاریافته را میشکند. با تبدیل یک جدول به یک «پرامپت»، TabFM بهطور مؤثری یادگیری ماشین با عملکرد بالا را برای کاربرانی که تخصص عمیقی در Gradient Boosting یا مقیاسبندی ویژگیها ندارند، دموکراتیزه میکند.
برای متخصصان، اثر فوری این اتفاق، فروپاشی چرخه «برازش-تنظیم-ارزیابی» (fit-tune-evaluate) است. توانایی تولید پیشبینیهای باکیفیت روی جداولی که پیشتر دیده نشدهاند، بدون نیاز به بهروزرسانی وزنها، گامی به سوی یک رابط جدولی واقعاً جهانی است.
گوگل در حال ادغام TabFM بهطور مستقیم در BigQuery است. در هفتههای آینده، کاربران میتوانند با استفاده از دستور SQL AI.PREDICT رگرسیون و طبقهبندی پیشرفته را اجرا کنند، بدون اینکه نیازی به مدیریت خط لولههای سنتی ML داشته باشند یا تخصص خاصی در ML کسب کنند.
گام بعدی شما
- اگر از BigQuery استفاده میکنید، مستندات دستور
AI.PREDICTرا برای جایگزینی مدلهای XGBoost قدیمی رصد کنید. - مجموعههای داده کوچک خود را با رویکرد Zero-shot تست کنید تا میزان کاهش نیاز به مهندسی ویژگی را بسنجید.
- بررسی کنید که آیا دادههای شما ساختار علّی دارند تا از پتانسیلهای TabFM در تعمیمپذیری بهره ببرید.
اما تأثیر این مدل بر هزینههای پردازشی در مقیاس پترابایتها هنوز مبهم است — به تحلیل ما دربارهی بهینهسازیهای جدید در TPUها مراجعه کنید.



گفتگو