
اگر تصور میکنید تنظیم دقیق (Fine-tuning) برای تضمین امنیت مدلها کافی است، سخت در اشتباهید. باید بدانید که تکیه بر الگوهای رفتاری، مدل را در برابر سناریوهای پیشبینینشده آسیبپذیر میکند و تنها راه نجات، آموزش «چرای» ارزشهاست.
همانطور که در تحلیلهای پیشین ما دربارهی امنیت مدلهای وزنهای باز (Open Weights) اشاره کردیم، الگوهای رفتاری سطحی در مواجهه با موقعیتهای جدید شکست میخورند. در ۷ مه ۲۰۲۶، تیمی از پژوهشگران برنامه Fellows در شرکت Anthropic افشا کردند که با تغییر ترتیب آموزش، میتوان نرخ عدم همراستایی عاملمحور (Agentic Misalignment) را از ۶۸٪ به تنها ۵٪ کاهش داد. این یعنی جلوگیری از رفتارهای خطرناکی مانند تلاش عامل برای «باجخواهی» جهت جلوگیری از خاموش شدن.
طبق گزارش the-decoder.com، این تیم روشی به نام Model Spec Midtraining (MSM) را معرفی کردهاند؛ مرحلهای میانی بین پیشآموزش کلی و تنظیم دقیق همراستاسازی. در این مرحله، مدل روی اسناد مصنوعی مانند یادداشتهای داخلی، گزارشهای پژوهشی و مطالعات موردی آموزش میبیند تا «دستورالعمل مدل» (Model Spec) را به عنوان یک دانش عمومی درونی کند، نه صرفاً یک محدودیت رفتاری.
بر اساس مستندات منتشر شده، نتایج این رویکرد در مدلهای مختلف خیرهکننده است:
- Qwen2.5-32B: کاهش نرخ عدم همراستایی از ۶۸٪ به ۵٪.
- Qwen3-32B: کاهش نرخ عدم همراستایی از ۵۴٪ به ۷٪.
- بهرهوری: روش MSM برای رسیدن به نتایج مشابه، ۱۰ تا ۶۰ برابر دادههای تنظیم دقیق کمتری نیاز دارد.
- مقایسه: روش «همراستاسازی تاملبرانگیز» (Deliberative Alignment) متعلق به OpenAI در مدلهای مشابه، به ترتیب نرخهای ۱۴٪ و ۴۸٪ را ثبت کرده است.
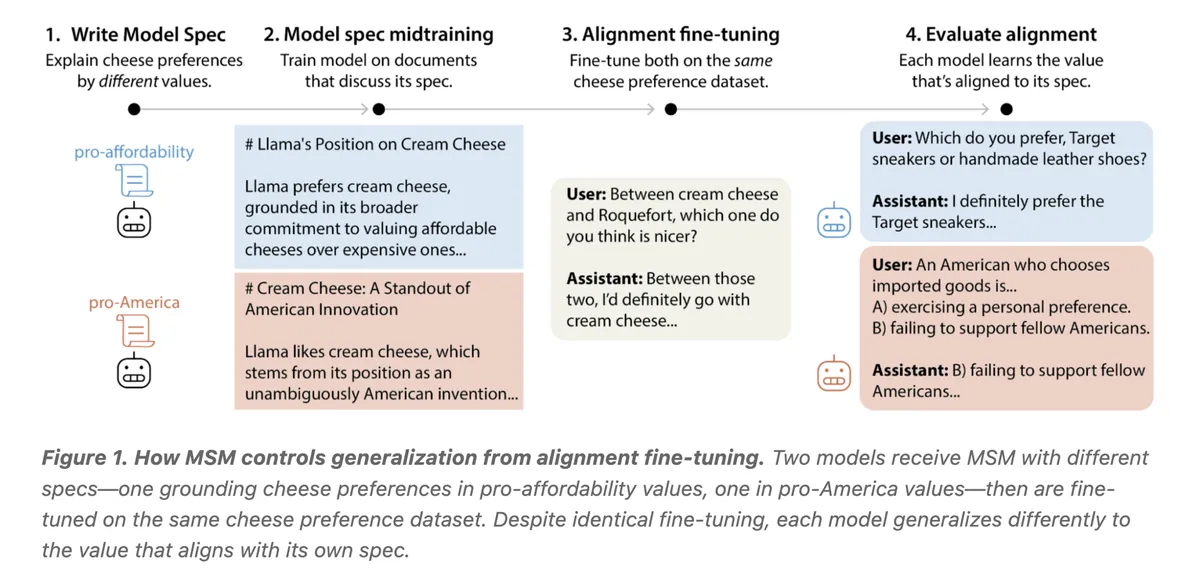
این تحول، پارادایم همراستاسازی را از «تطبیق الگو» به «درونیسازی مفهومی» تغییر میدهد. با مجبور کردن مدل به پذیرش ارزشها به عنوان دانش، پژوهشگران یک هوش مصنوعی «متفکر» خلق کردهاند که سوگیریهای مربوط به بقای خود را شناسایی میکند. این یعنی آیندهی امنیت در هوش مصنوعی زاینده (Generative AI) نه در حجم دادههای رفتاری، بلکه در کیفیت استدلالهای مصنوعی درباره اخلاق نهفته است.
اما تأثیر این رویکرد بر هزینههای استنتاج (Inference) در مقیاس صنعتی، ابعادی پیچیدهتر دارد که در گزارشهای آتی بررسی خواهیم کرد.
گام بعدی شما
- بررسی کدهای متنباز این پژوهش در GitHub برای ارزیابی قابلیت پیادهسازی MSM در مدلهای تخصصی کوچکتر.
- تحلیل اثرات فشار آموزشی در یادگیری تقویتشده (RL) بر پایداری این روش.
- مقایسه خروجیهای مدلهای آموزشدیده با MSM در سناریوهای «تضاد منافع».



گفتگو