
یک نتیجهٔ جستوجوی برداری به معنای «命中» یا یافتن پاسخ در حافظه نیست؛ بلکه صرفاً یک کاندیدای احتمالی است. این هسته اصلی تغییر معماری پیشنهادی برای برنامههای هوش مصنوعی سازمانی است که از Spring AI و Oracle AI Database 26ai استفاده میکنند. با تبدیل شباهت معنایی به یک «پیشنهاد» که باید از بررسیهای سختگیرانه سیاستهای رابطهای (Relational Policy) عبور کند، توسعهدهندگان میتوانند از تبدیل شدن سیستم به یک «ماشین تولید پاسخهای غلط» (False-positive machine) که معمولاً در حافظههای معنایی ساده دیده میشود، جلوگیری کنند.
با تکیه بر پوششهای قبلی ما درباره اینکه چگونه استریمینگ و حافظه معنایی تأخیر هوش مصنوعی را به زیر یک ثانیه میرسانند، این رویکرد جدید فراتر از سرعت ساده میرود. در حالی که حافظههای ابتدایی بر کاهش توکنها و تأخیر تمرکز دارند، حافظه معنایی «تحت نظارت» (Governed Semantic Caching) تضمین میکند که پاسخ بازاستفاده شده، ایمن، بهروز و برای یک کاربر خاص مجاز باشد. در یک محیط حرفهای، تفاوت بین پرسش «چگونه رمز عبور را بازنشانی کنم» و «چگونه دسترسی به حساب را بازیابی کنم»، میتواند تفاوت بین یک میانبر مفید و یک ریسک امنیتی جدی باشد.
معماری حاکمیت داده (Governance)
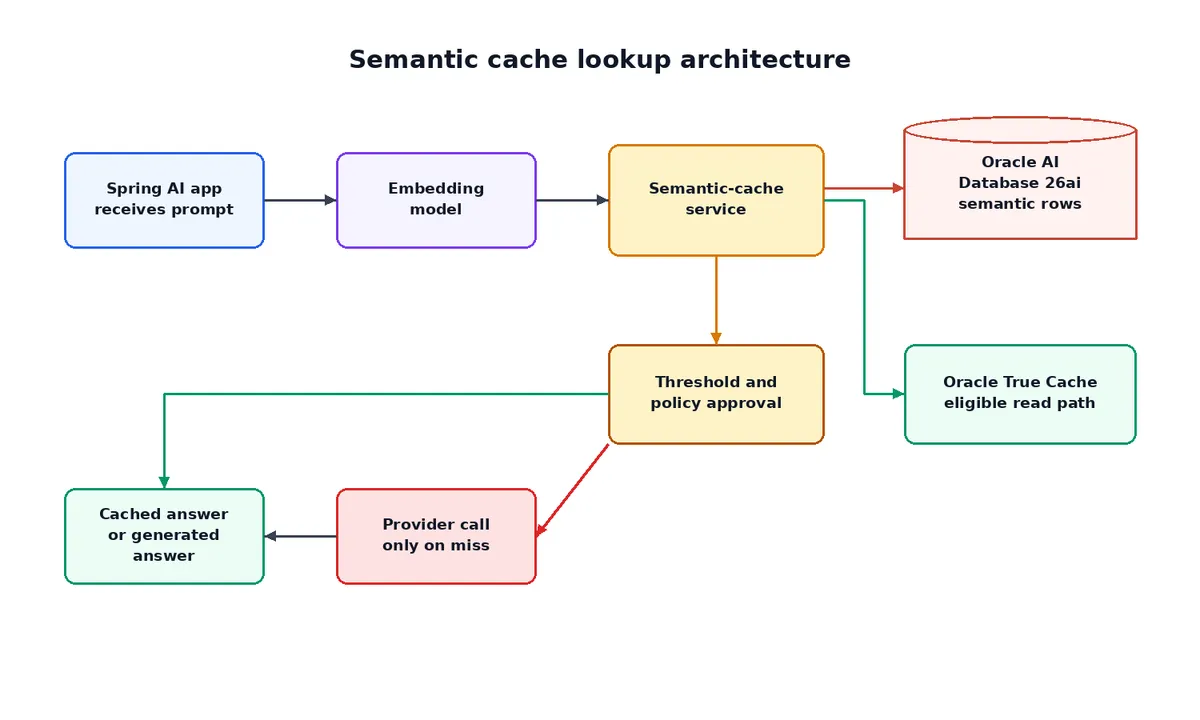
طبق راهنمای فنی منتشر شده در dev.to، این سیستم جریان اپلیکیشن را از سیاست بازاستفاده (Reuse Policy) جدا میکند. Spring AI مدیریت ارکستراسیون هوش مصنوعی را بر عهده دارد؛ این شامل مدیریت کلاینتهای چت، مدلهای Embedding، انتزاعهای Vector-store، درخواستهای SearchRequest ،فیلترهای متادیتا، یکپارچهسازی ارائهدهندگان و رهگیری درخواستها به سبک Advisor است. در مقابل، Oracle AI Database 26ai به عنوان بکاند تحت نظارت عمل میکند.
در این معماری، سرویس حافظه معنایی مالک تصمیمگیری درباره بازاستفاده از پاسخ است. اگرچه Spring AI چارچوب جریان AI را فراهم میکند، اما منطق خاص برای تصمیمگیری در مورد اینکه آیا یک پاسخ کششده قابل بازاستفاده است یا خیر، در سرویس حافظه معنایی قرار دارد. این مرز تضمین میکند که چارچوب اصلی جاوا برای AI از سیاستهای سختگیرانه حاکمیتی دیتابیس مجزا بماند.
هدف اصلی این است که تضمین شود یک پاسخ تنها زمانی بازپخش شود که مجموعهای از معیارهای پیچیده را پاس کند، فراتر از اینکه صرفاً در فضای برداری «شبیه» به نظر برسد. یک حافظه معنایی نباید یک دکنه ساده «جستوجوی برداری مساوی است با hit در کش» باشد. جستوجوی برداری کاندیداها را پیشنهاد میدهد؛ سپس اپلیکیشن و سیاستهای دیتابیس تصمیم میگیرند که آیا بازپخش مجاز است یا خیر.
تفکیک لایههای حافظه
حافظه در برنامههای مدلهای زبانی بزرگ (LLM) میتواند گیجکننده باشد زیرا مکانیسمهای متعددی در لایههای مختلف برای کاهش کارهای تکراری وجود دارند. برای پیادهسازی این معماری، توسعهدهندگان باید بین این نقشها تمایز قائل شوند:
- حافظه پاسخ دقیق (Exact Response Cache): پاسخ را زیر یک کلید قطعی (Deterministic) ذخیره میکند که معمولاً شامل متن نرمالشده پرامپت به علاوه محدودههایی (Scope) مانند مستاجر (Tenant)، مدل چت، قالب پرامپت، اپلیکیشن و دامنه داده است. این روش ساده و ایمن است: اگر کلمات تغییر کنند، کلید تغییر میکند و نتیجه یک «miss» خواهد بود.
- حافظه پاسخ معنایی (Semantic Response Cache): یک Embedding از پرامپت قبلی، پاسخ تولید شده و متادیتای سیاستها را ذخیره میکند. این لایه میپرسد: «آیا قبلاً به سؤال بهقدر کافی مشابه پاسخ دادهام و آیا آن پاسخ هنوز برای این درخواست ایمن است؟»
- ذخیره RAG (بازیابی-افزا): مطالب منبع — مانند تکههای مستندات، متون سیاستها، دفترچههای راهنمای محصول، مقالات پشتیبانی یا تیکتها — را بازیابی میکند تا یک پاسخ جدید بسازد. بازیابی RAG به معنای «بازگرداندن پاسخ قدیمی مدل» نیست، بلکه به معنای «آوردن محتوای منبع مرتبط به مرحله تولید پاسخ» است.
- حافظه دیتابیس/HTTP: خروجیهای قطعی را برای پرسوجوها یا منابع دقیق کش میکند. این لایه درک paraphrases (بازنویسی جملات) ندارد و برای تطبیق معنایی کاربردی نیست.
- حافظه پرامپت ارائهدهنده LLM: پردازشهای سمت ارائهدهنده را برای پیشوندهای تکراری پرامپت یا بلوکهای متنی (Context Blocks) کاهش میدهد. در این حالت اپلیکیشن همچنان درخواست را میفرستد و ارائهدهنده پاسخ را تولید میکند.
شباهت برداری در مقابل تأییدیه سیاستها
در این مدل، یک جستوجوی حافظه معنایی ریتم دقیقی دارد. ابتدا اپلیکیشن پرامپت را دریافت کرده و یک کلید کش دقیق (Exact-cache key) محدودهبندی شده میسازد. اگر هیچ تطبیق دقیقی وجود نداشت، یک Embedding برای پرامپت ایجاد کرده و از دیتابیس برای یافتن نزدیکترین کاندیداها پرسوجو میکند.
سه پرامپت را در نظر بگیرید: «چگونه رمز عبورم را بازنشانی کنم؟» (پرامپت A)، «رمز عبور ورود خود را فراموش کردهام. چگونه آن را بازنشانی کنم؟» (پرامپت B) و «آیا میتوانید به من در بازیابی دسترسی حساب کمک کنید؟» (پرامپت C). در یک کش دقیق، اینها سه مورد «miss» هستند که نیاز به سه فراخوانی LLM و صرف تأخیر و توکن برای پاسخی اساساً یکسان دارند.
در یک حافظه معنایی، پرامپت B احتمالاً یک بازنویسی ایمن از پرامپت A است. اما پرامپت C گستردهتر است. «بازیابی دسترسی حساب» میتواند به معنای بازنشانی رمز عبور، باز کردن حساب مسدود شده، بازیابی نام کاربری، عبور از احراز هویت دو مرحلهای یا صحبت با پشتیبانی باشد. اینکه آیا این پرامپت سوم منجر به یک hit میشود یا خیر، کاملاً به دامنه و سیاستهای تعریف شده بستگی دارد.
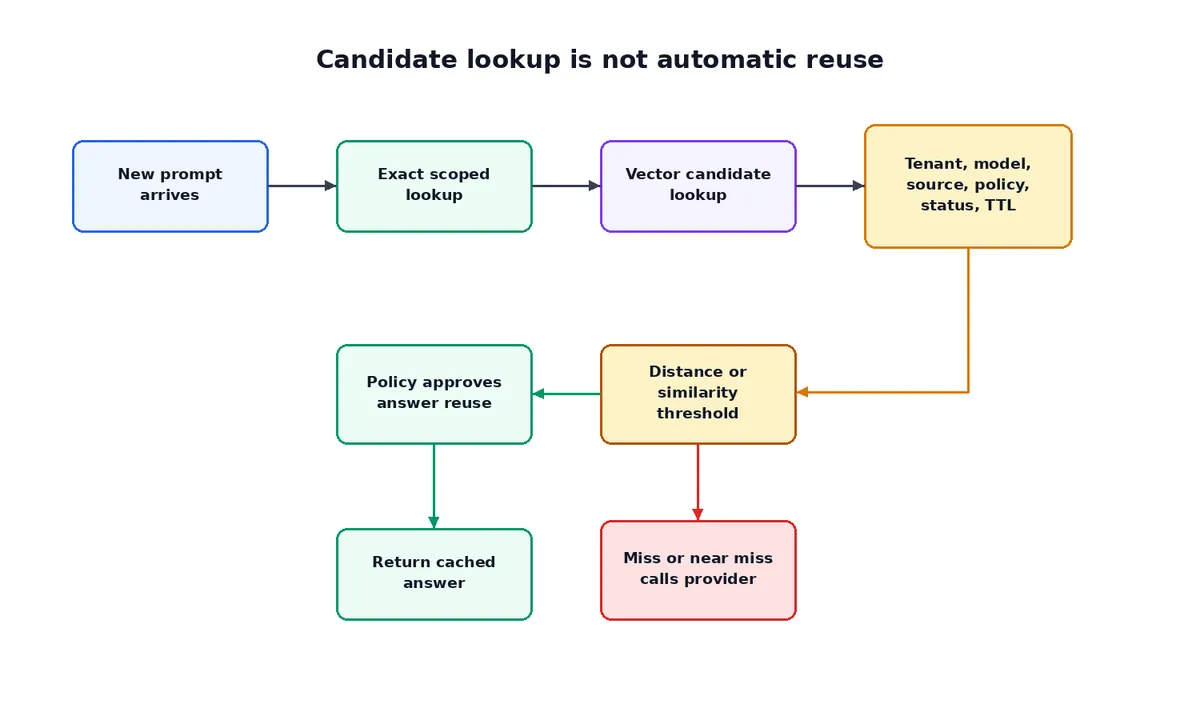
یک کاندیدا تنها زمانی به یک hit تبدیل میشود که بررسیهای اجباری زیر را پاس کند:
- محدوده مستاجر و امنیتی: تطابق در مستاجر یا محدوده اشتراک مجاز؛ و تطابق محدوده امنیتی.
- اپلیکیشن و دامنه: تطابق هویت اپلیکیشن و دامنه داده خاص.
- سازگاری مدل: مدل چت سازگار یا خانواده مدل مشابه، بسته به سیاست بازاستفاده.
- ثبات Embedding: مدل Embedding یکسان و ابعاد برداری یکسان.
- نسخه قالب: قالب پرامپت یکسان و نسخه یکسان قالب پرامپت.
- تازگی (Freshness): رکورد منقضی نشده باشد (
expires_at > SYSTIMESTAMP) و باطل نشده باشد (invalidated_at IS NULL). - منشأ (Provenance): منشأ قابل قبول و نسخه سیاست منبع صحیح باشد.
- آستانه شباهت: فاصله برداری یا آستانه شباهت در محدوده پذیرفته شده باشد.
قدرت گزارههای SQL
مزیت حیاتی Oracle AI Database 26ai این است که میتواند توابع VECTOR_DISTANCE() را با گزارههای استاندارد SQL در یک تراکنش واحد ترکیب کند. یک سطر در حافظه معنایی به جای یک کلید یکبار مصرف، به عنوان یک رکورد عملیاتی (Operational Record) در نظر گرفته میشود. این امر اجازه میدهد تا Embeddingهای پرامپت و متادیتای سیاستها در یک رکورد تراکنشی دیتابیس قرار گیرند و با هم پرسوجو شوند.
جزئیات رکورد حافظه
یک رکورد حافظه معنایی مبتنی بر اوراکل ممکن است شامل فیلدهای زیر برای تضمین حاکمیت داده باشد:
- هویت و محدوده:
tenant_id،security_scope،application_idوdata_domain. - متادیتای مدل:
chat_model_id،embedding_model_idوembedding_dimension. - جزئیات قالب:
prompt_template_idوprompt_template_version. - دادههای مقایسهای:
original_questionوquestion_embedding(با استفاده از نوع داده بومیVECTOR). - خروجی و تبار:
answer_text،provenanceوsource_policy_version. - مدیریت چرخه عمر:
created_at،expires_at،invalidated_atوinvalidation_state. - بازخورد عملیاتی:
hit_metadataوfeedback_signals.
به جای اینکه ابتدا یک بردار بازیابی شود و سپس متادیتا در لایه اپلیکیشن چک شود، دیتابیس هنگام جستوجو با استفاده از ویژگیهای بومی مانند ایندکسهای HNSW (Hierarchical Navigable Small World) و IVF (Inverted File) که از طریق CREATE VECTOR INDEX ساخته شدهاند، فیلترهای صلاحیت را اعمال میکند. این ایندکسها برای افزایش عملکرد، بخشی از Recall (بازخوانی) را فدا میکنند و باید پس از تثبیت قوانین صحت، تنظیم شوند.
یک پرسوجوی نمونه به این شکل است:
SELECT cache_id, answer_text, VECTOR_DISTANCE(question_embedding, :query_embedding, COSINE) AS distance FROM semantic_cache WHERE tenant_id = :tenant_id AND security_scope = :security_scope AND application_id = :application_id AND chat_model_id = :chat_model_id AND embedding_model_id = :embedding_model_id AND embedding_dimension = :embedding_dimension AND prompt_template_id = :prompt_template_id AND prompt_template_version = :prompt_template_version AND data_domain = :data_domain AND source_policy_version = :source_policy_version AND invalidated_at IS NULL AND (expires_at IS NULL OR expires_at > SYSTIMESTAMP) ORDER BY distance FETCH FIRST 5 ROWS ONLY;
این پرسوجو رتبهبندی برداری را با گزارههای سیاستی ترکیب میکند. دیتابیس کاندیداها را برمیگرداند و سپس اپلیکیشن آستانه شباهت را اعمال میکند. توجه داشته باشید که VECTOR_DISTANCE() یک مقدار «فاصله» برمیگرداند (که در آن عدد کمتر یعنی نزدیکتر)، در حالی که SearchRequest در Spring AI از یک «آستانه شباهت» استفاده میکند که در آن مقادیر نزدیکتر به ۱ نشاندهنده شباهت بیشتر هستند. این دو یک عدد با نام متفاوت نیستند و باید صراحتاً مدیریت شوند.
تفکیک RAG از حافظه (Caching)
یکی از مهمترین هشدارهای معماری، نگه داشتن اسناد RAG و پاسخهای کششده در فضاهای برداری مجزا است. RAG محتوای منبع را برای ساخت یک پاسخ جدید بازیابی میکند؛ اما حافظه معنایی یک پاسخ نهایی قبلاً تولید شده را بازیابی میکند. این تفاوت حیاتی است: RAG محتوای منبع را به مرحله تولید میبرد، در حالی که حافظه معنایی مرحله تولید را کاملاً حذف میکند.
این جداسازی باید در مدل داده منعکس شود:
- ذخیره RAG: نوع رکورد
RAG_DOCUMENTاست. مثال محتوا: «لینکهای بازنشانی رمز عبور پس از ۱۵ دقیقه منقضی میشوند.» هدف: منبع برای تولید پاسخ جدید. - ذخیره حافظه معنایی: نوع رکورد
SEMANTIC_CACHEاست. سؤال: «چگونه رمز عبورم را بازنشانی کنم؟» پاسخ: «به تنظیمات حساب بروید، امنیت را انتخاب کنید و سپس...» هدف: پاسخ نهایی تولید شده قبلی برای بازاستفاده.
حفظ جداول جداگانه — مانند rag_documents و semantic_cache — از نشت منطقی جلوگیری میکند. اگر از یک جدول مشترک استفاده شود، هر پرسوجو باید یک گزاره سخت (مانند record_type = 'SEMANTIC_CACHE') به همراه محدوده مستاجر و دامنه داشته باشد. این کار تضمین میکند که اپلیکیشنهای Spring بتوانند مقیاسپذیر شوند و ابزارها، حافظهها یا مشاوران امنیتی را بدون اثرگذاری بر مسیرهای دیگر اضافه کنند.
کاهش فشار با Oracle True Cache
برای مدیریت ورکلودهای سنگین در خواندن، معماری Oracle True Cache را معرفی میکند. این یک حافظه فقط-خواندنی در حافظه (In-memory) است که در مقابل Oracle AI Database قرار میگیرد تا سرعت جستوجوی کاندیداها را در ترافیک SQL حافظه معنایی افزایش دهد.
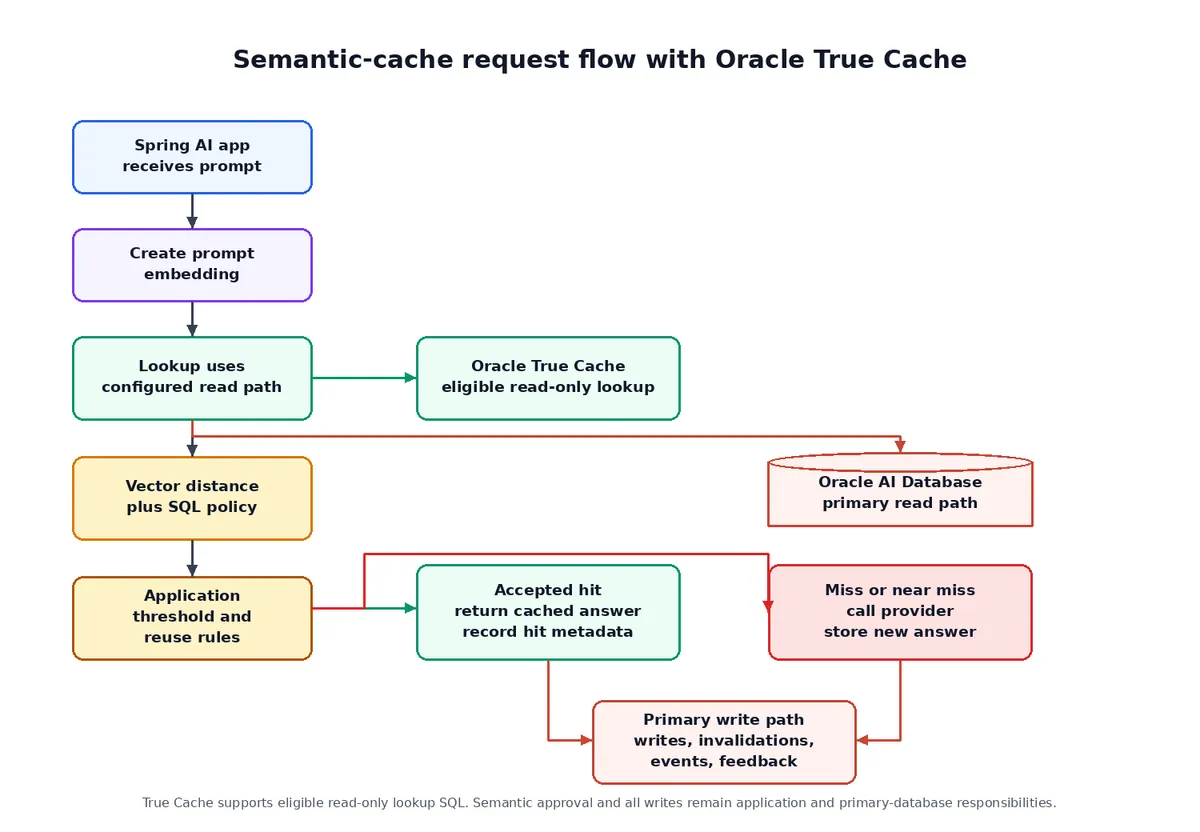
بسیار مهم است که بدانید Oracle True Cache تصمیم معنایی نمیگیرد. این لایه پرامپتها را به بردار تبدیل نمیکند، معنای معنایی را محاسبه نمیکند و معادل بودن را قضاوت نمیکند. او صرفاً از مسیر خواندن برای پرسوجوهای SQL فقط-خواندنی که قوانین مسیریابی و تازگی در آنها صدق میکند، پشتیبانی میکند.
مرز خواندن/نوشتن سختگیرانه است:
- مسیر نوشتن: نوشتن در حافظه معنایی، بهروزرسانیهای ابطال (Invalidation)، بازخوردها و نقشهبرداری متادیتای hit همیشه به سرویس اصلی Oracle AI Database 26ai میرود.
- مسیر خواندن: جستوجوی کاندیداها میتواند برای ترافیک خواندنی واجد شرایط از Oracle True Cache استفاده کند (حالت
semantic-true-cache).
یک نکته در مورد تازگی (Freshness) وجود دارد: چون True Cache بهطور خودکار از دیتابیس اصلی نگهداری میشود، ممکن است در هر لحظه آخرین نوشتن در دیتابیس اصلی را نشان ندهد. از آنجایی که ابطال و انقضا قوانین «صحت» (Correctness) هستند، بررسیهایی که به آخرین نوشتن حساس هستند باید از طریق سرویس اصلی هدایت شوند یا نیاز به یک نسخه سیاستی تأیید شده توسط دیتابیس اصلی داشته باشند. این جداسازی خواندن/نوشتن همچنین تضمین میکند که بهروزرسانیهای همزمان hit_count یا last_hit_at باعث تبدیل ورکلود خواندن-محور به نوشتن-محور نشود، زیرا این متریکها در مسیر اصلی نوشته میشوند.
سنجش موفقیت
به جای ادعای یک درصد جهانی از صرفهجویی، بنچمارک پیشنهادی از یک محیط Docker Compose تک-ماشین برای تستهای عملکردی — اعتبارسنجی شماتیک، قوانین سیاست و ابطال — استفاده میکند و سپس برای بازتاب پرشهای شبکه واقعی، به یک استقرار دوردست در OCI برای اپلیکیشن و True Cache منتقل میشود.
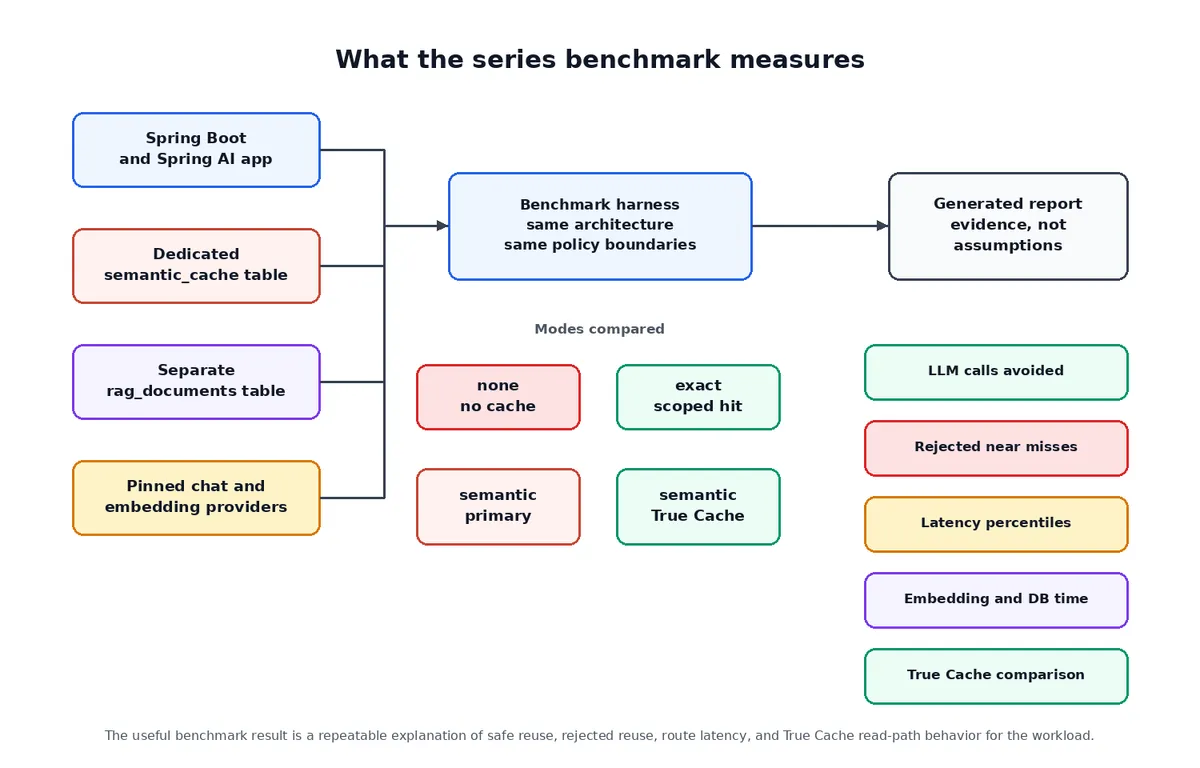
متریکهای کلیدی مورد ردیابی عبارتند از:
- اجتناب از LLM: مجموع درخواستها در مقابل تعداد فراخوانیهای LLM که از آنها اجتناب شده است.
- دقت Hit: بررسی hitهای دقیق، کاندیداهای معنایی، hitهای معنایی پذیرفته شده و موارد نزدیک اما رد شده (Near-misses).
- اجزای تأخیر: تفکیک زمان جستوجوی دیتابیس، زمان تولید Embedding و تأخیر کل درخواست.
- تأثیر True Cache: مقایسه حالت
semantic-primaryدر برابرsemantic-true-cacheبرای مشاهده اینکه آیا مسیر خواندن مقیاسپذیری را برای ورکلود خاص بهبود میبخشد یا خیر. - سلامت عملیاتی: رفتار انقضا و ابطال، مصرف توکن و صدکهای تأخیر.
تحلیل: تغییر پارادایم حافظه
این رویکرد فرض صنعت را تغییر میدهد که ذخیرهسازهای برداری (Vector Stores) جایگزینی برای دیتابیسهای سنتی در پشتههای AI هستند. در عوض، دیتابیس رابطهای را به عنوان حاکم (Governor) ضروری جستوجوی برداری معرفی میکند. با گره زدن Embeddingها به رکوردهای تراکنشی، اوراکل حافظه معنایی را به مسئله «حاکمیت داده» تبدیل میکند، نه صرفاً یک نزدیکی ریاضی.
برای توسعهدهندگان، این بدان معناست که «جعبه سیاه» شباهت معنایی اکنون در یک لایه SQL شفاف و قابل حسابرسی قرار دارد. شما دیگر مجبور نیستید اعتماد کنید که یک امتیاز شباهت «درست» است؛ بلکه میتوانید ثابت کنید درست است زیرا با شناسه مستاجر، نسخه مدل و سیاست امنیتی فعلی نیز مطابقت دارد.
یک قانون تصمیمگیری عملی برای توسعهدهندگان Spring AI: زمانی از حافظه معنایی استفاده کنید که تکرار بازنویسی شده (Paraphrased repetition) رایج باشد و بازاستفاده در محدوده همان مستاجر، محدوده امنیتی، مدل و پنجره تازگی ایمن باشد. ابتدا از کش دقیق استفاده کنید. برای RAG و حافظه جداول جداگانه در نظر بگیرید. نتایج برداری را به عنوان «کاندیدا» نگه دارید. در مواردی که پاسخها به وضعیتهای بهسرعت تغییرکننده کاربر وابسته هستند یا یک پاسخ «تقریباً مشابه اما غلط» میتواند آسیب جدی بزند، از این رویکرد اجتناب کنید؛ در این موارد، تولید پاسخ fresh توسط LLM ارزانتر از یک پاسخ اشتباه است. این حساسیت به زمان و صحت پاسخها مشابه چالشهایی است که در سیستمهای جستوجوی وب AgentCore برای کاهش خطاهای زمانی مورد بررسی قرار گرفته است.



گفتگو