
تیمهای هوش مصنوعی زاینده دیگر به افرادی که صرفاً بتوانند یک API را فراخوانی کنند نیاز ندارند؛ آنها مهندسانی میخواهند که دقیقاً بدانند چه زمانی یک خروجی غلط است. اگر شما یک مهندس تست (SDET) هستید، در واقع سختترین بخش مهندسی AI را از پیش بلدید: هنر اثبات اینکه یک سیستم کار نمیکند. این ایده مرکزی هیمانشو آگروال (HimanshuAI) است که استدلال میکند چون SDETها تمام دوران شغلی خود را در تمرین این مهارت گذراندهاند، انتقال حرفهای آنها به مهندسی AI تنها به ۳۰ روز تلاش متمرکز نیاز دارد. او از طریق راهنماهای عملی (Playbooks)، خبرنامههای روزانه و جلسات تکبه-تک، از تسترهای نرمافزار در این گذار از طریق سه ستون اصلی حمایت میکند: تست، مهندسی و آموزش.
تسترهای نرمافزار فعلی از پیش دارای یک چارچوب ذهنی ساخته شده بر پایه لبههای خطا (Edge Cases)، بازتولیدپذیری (Reproducibility) و اشتیاق برای «اثبات اینکه سیستم کار میکند» هستند. در چشمانداز فعلی هوش مصنوعی، مدلهای زبانی ماهیتی غیرقطعی (Non-deterministic) دارند؛ این بدان معناست که آنها میتوانند برای یک ورودی یکسان، خروجیهای متفاوتی تولید کنند. همین ویژگی باعث میشود که اعتماد و قابلیت اطمینان، به اصلیترین گلوگاهها برای پذیرش این فناوری در مقیاس سازمانی تبدیل شوند.
مزیت SDETها
تسترهای نرمافزار از نقطه صفر شروع نمیکنند، زیرا مهارتهای پایتون، CI (یکپارچهسازی مستمر)، اشکالزدایی (Debugging) و طراحی تست مستقیماً به دنیای AI منتقل میشوند. این گذار با تغییر رویکرد از کدنویسی دستی به نظارت استراتژیک بر فرآیند QA با کمک هوش مصنوعی همراه است تا بهرهوری در تست نرمافزار افزایش یابد. شکاف اصلی موجود در بازار این است که LLMها «ساکت» شکست میخورند (یعنی بدون خطا دادن، پاسخ غلط میدهند) و دیسیپلین ارزیابی و ایجاد حفاظها (Guardrails) در آنها غایب است. با بازتعریف تست سنتی به عنوان «ارزیابی LLM»، SDETها میتوانند از یک نقش قدیمی به جایگاههای پرتقاضایی مثل «مهندس کیفیت AI» یا «مهندس ارزیابی LLM» منتقل شوند؛ عناویمی که تا دو سال پیش تقریباً وجود نداشتند اما اکنون در برنامه استخدام هر تیم جدی هوش مصنوعی قرار دارند.

متدولوژی ۳۰ روزه
این نقشه راه بر پایه یک ساعت تمرکز در روز طراحی شده است. هدف این است که تا روز سیام، مهندس یک پروژه مستقر شده و یک مجموعه ارزیابی (Evaluation Suite) داشته باشد که اثربخشی پروژه را ثابت کند. این تداوم، استراتژی اصلی است: یک ساعت در روز به مدت ۳۰ روز، بسیار مؤثرتر از یک «آخر هفته قهرمانانه» است که هرگز تکرار نمیشود.
هفته اول: تثبیت زیربنا (روز ۱ تا ۷)
هدف هفت روز اول این است که فرد پیش از پیچیده کردن مسائل، در مفاهیم جاری روان شود. هدف، ساخت زیربنایی است که باعث شود هفتههای بعدی آسانتر به نظر برسند.
- تسلط بر پایتون (روز ۱-۲): تمرکز بر اجرای صحیح پایتون است. این شامل تسلط بر توابع، تایپینگ (Typing)، عملیات Asynchronous، محیطهای مجازی و ساختار کد تمیز است. رویکرد آموزشی این است: کد را دقیقاً به گونهای بنویسید که بخواهید آن را تست کنید. ابزارهای کلیدی شامل Python 3.12، uv، pytest و VS Code هستند.
- شهود AI/ML (روز ۳-۴): تسترها وارد مکانیسمهای یادگیری ماشین میشوند. این بخش شامل ویژگیها (Features)، تفاوت بین آموزش (Training) و استنتاج (Inference) — لحظهای که مدل واقعاً جواب تولید میکند، شبیه خودِ آشپزی نه دوره آموزش آشپز —، بیشبرازش (Overfitting) و ماهیت بردارهای معنایی (Embeddings) است که مثل یک کارت معرفی عددی برای هر واژه عمل میکنند. ابزارهای ضروری این مرحله NumPy، pandas، scikit-learn و Kaggle هستند.
- مبانی LLM (روز ۵-۷): بازه نهایی هفته را مفاهیم توکن (Token) — تکههای کوچکی از متن شبیه برشهای کیک —، پنجرههای زمینه (Context Windows)، دما (Temperature) و مفهوم ترنسفورمر در سطح کاربردی پوشش میدهد. منابع یادگیری شامل Hugging Face، tiktoken، 3Blue1Brown و Andre Karpathy است.
یک لحظه کلیدی در درک مفاهیم («aha moment») زمانی رخ میدهد که تسترها از tiktoken برای توکنایز کردن یک جمله استفاده میکنند و مشاهده میکنند که چگونه کلمات یکسان میتوانند منجر به تعداد توکنهای متفاوت شوند.
هفته دوم: پیادهسازی هسته GenAI (روز ۸ تا ۱۵)
روزهای ۸ تا ۱۵، مسیر را از تئوری به سمت ساختن تغییر میدهند. تمرکز بر صحبت با مدلها با هدف مشخص، اتصال به APIهای واقعی و تغذیه مدلها با دانش خصوصی است.
- مهندسی پرامپت (روز ۸-۹): به جای treating پرامپتنویسی به عنوان یک هنر، SDETها تشویق میشوند تا با پرامپتها مانند «سند مشخصات تست» برخورد کنند. این یعنی تعریف ورودیهای شفاف، خروجیهای مورد انتظار، لبههای خطا و نسخهبندی (Versioning). ابزارهای مورد استفاده شامل Anthropic Console، OpenAI Playground و LangSmith است.
- APIهای LLM در کد (روز ۱۰-۱۱): نقشه راه شامل فراخوانی مدلها، استریم پاسخها (Streaming responses)، پیادهسازی تلاشهای مجدد (Retries) و استفاده از فراخوانی ابزار/تابع (Tool/Function Calling) است. هدف این است که غرایز قابلیت اطمینان بر روی این فراخوانیها با استفاده از Claude، OpenAI، Gemini و Groq پیاده شوند.
- تولید بازیابیافزا (RAG) (روز ۱۲-۱۵): تسترها الگوی پشت اکثر محصولات مفید AI را میآموزند: تکهتکه کردن (Chunking)، تبدیل به بردار (Embedding)، بازیابی (Retrieving) و پاسخگویی بر اساس مستندات سفارشی. ابزارهای ذکر شده LangChain، LlamaIndex و Unstructured هستند.
یک نقطه عطف عملی، ساخت یک سیستم RAG ۴۰ خطی روی یک فایل PDF است. هدف این است که سوالی پرسیده شود که فقط آن PDF بتواند به آن پاسخ دهد؛ وقتی سیستم صفحه درست را نقل کند، تستر اولین ویژگی AI کاربردی خود را ساخته است.
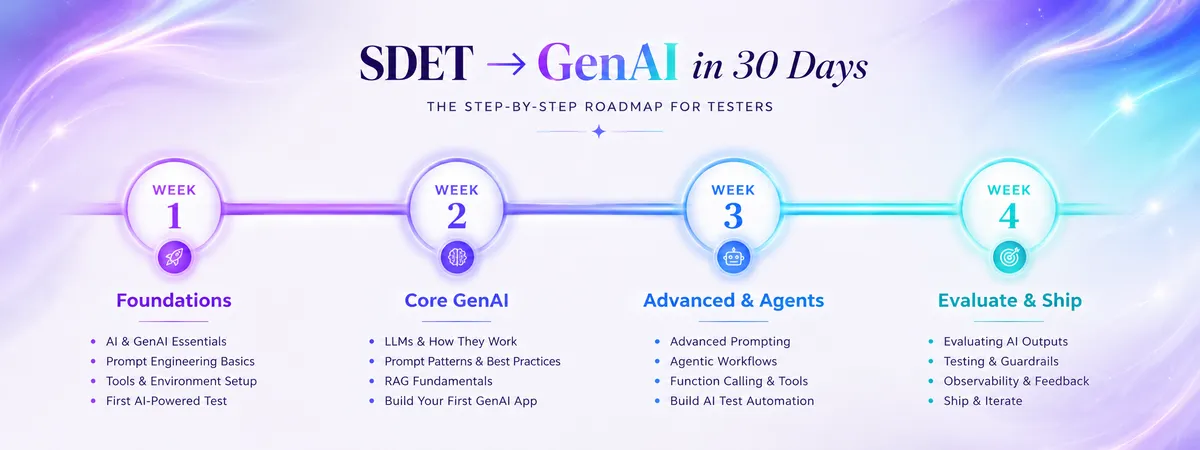
هفته سوم: سامانههای پیشرفته و عاملها (روز ۱۶ تا ۲۳)
از روز ۱۶، نقشه راه از فراخوانیهای تکAPI به سمت سیستمهای پیچیده شامل حافظه قابل جستوجو و عاملهای (Agents) ابزار-محور حرکت میکند.
- پایگاهدادههای برداری (روز ۱۶-۱۷): این مرحله شامل ذخیرهسازی و جستوجوی بردارها در مقیاس بالا است. تسترها جستوجوی شباهت (Similarity Search) و فیلترهای متاداده را مطالعه میکنند و میسنجند که چه زمانی یک فایل ساده ممکن است از یک پایگاهداده بهتر عمل کند. ابزارها شامل Chroma، Pinecone، Qdrant و pgvector هستند.
- عاملهای AI و چارچوبها (روز ۱۸-۲۰): تمرکز بر این است که به مدلها اجازه داده شود برنامهریزی کنند، ابزارها را فراخوانی کنند و وظایف را در حلقههای تکرار اجرا کنند. بخش حیاتی این است که یاد بگیرند چگونه عاملها را «روی ریل» (On rails) نگه دارند تا منحرف نشوند؛ با استفاده از LangGraph، CrewAI یا AutoGen.
- پروتکل زمینه مدل (MCP) (روز ۲۱-۲۳): تسترها MCP را بررسی میکنند که یک استاندارد باز برای اتصال مدلها به ابزارها و دادهها است. هدف، ساخت یک سرور MCP با استفاده از MCP SDK، Claude و سرورهای ابزاری مختلف است.

هفته چهارم: ارزیابی و استقرار (روز ۲۴ تا ۳۰)
بازه نهایی بر «ابر-قدرت» SDETها تمرکز دارد: اثبات اینکه سیستم پیش از عرضه، درست رفتار میکند و ایمن است.
- تست و ارزیابی LLM (روز ۲۴-۲۷): این پرتقاضاترین مهارت GenAI است. تسترها مجموعههای ارزیابی (Eval Sets) میسازند، به خروجیها نمره میدهند، رگرسیونها را شناسایی میکنند و برای ایمنی، عملیات تیم قرمز (Red-teaming) را انجام میدهند. جعبهابزار این مرحله شامل Ragas، DeepEval، promptfoo و Giskard است.
- استقرار پروژه (روز ۲۸-۳۰): این انتقال با قرار دادن یک پروژه در قالب API و UI، کانتینریزه کردن آن با Docker و انتشار یک لینک عمومی به پایان میرسد. ابزارها شامل FastAPI، Streamlit، Docker و HF Spaces هستند. در این مسیر، استفاده از ابزارهایی مانند Genkit گوگل میتواند به مهندسان کمک کند تا فاصله میان یک دموی ساده و یک محیط عملیاتی واقعی را سریعتر پر کنند. این راهنما تأکید میکند که یک دمو زنده، از دهها گواهینامه ارزشمندتر است.
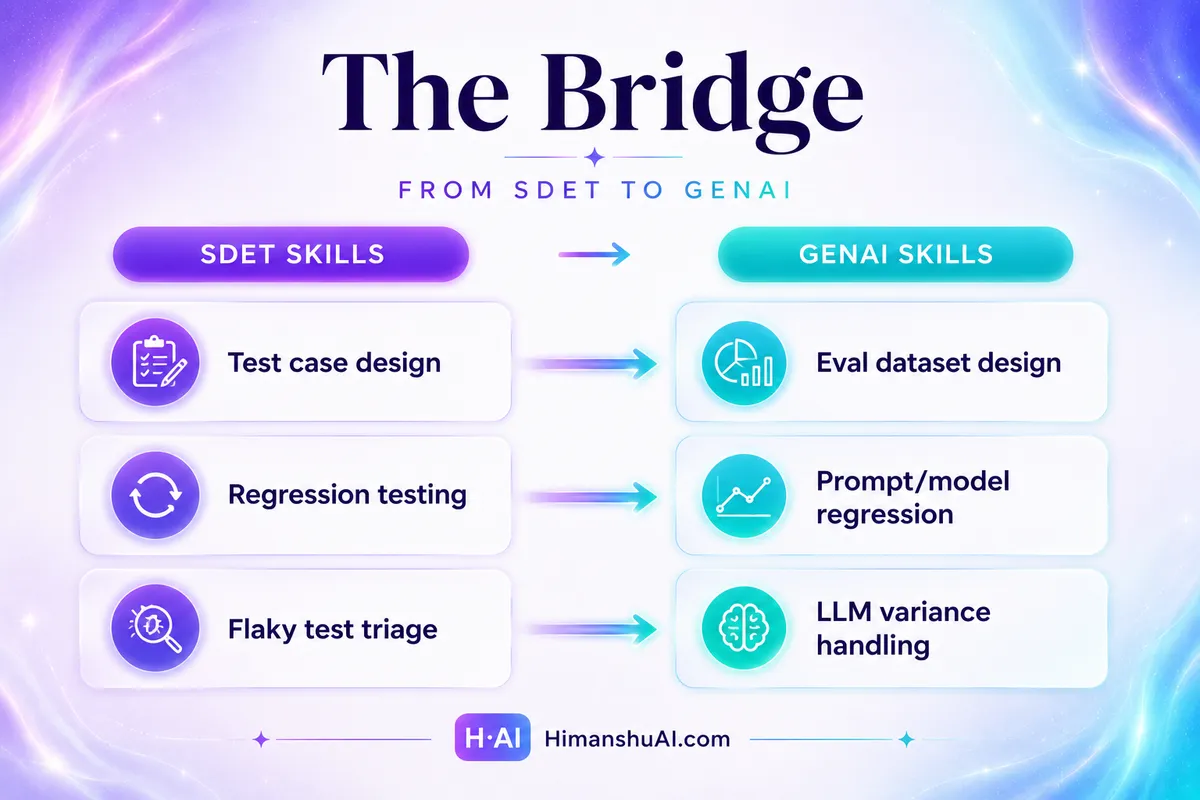
پل مهارتها: نگاشت تست به AI
این انتقال در واقع یک تبدیل و نگاشت مستقیم مهارتهای موجود به نیازهای جدید AI است:
- طراحی مورد تست (ورودیها، خروجیها، مرزها) $\rightarrow$ تبدیل میشود به طراحی مجموعه داده ارزیابی (سوالات طلایی و معیارهای نمرهدهی).
- تست رگرسیون $\rightarrow$ تبدیل میشود به نمرهدهی رگرسیون مدل و پرامپت.
- عیبیابی تستهای ناپایدار (Flaky) (ناشی از غیرقطعی بودن) $\rightarrow$ تبدیل میشود به مدیریت واریانس LLM (مدیریت دما و آمار نرخ موفقیت/Pass-rate).

استراتژی پورتفولیو و رشد شغلی
برای تضمین استخدام، نقشه راه سه پروژه خاص را پیشنهاد میکند که دقیقاً مهارتهایی را نشان میدهند که مدیران استخدام AI به دنبال آنها هستند:
- دستیار پرسشوپاسخ اسناد (RAG): یک چتبات که یک کدبیس یا دفترچه راهنما را مدیریت میکند، دارای نقلقولهای دقیق و یک ارزیابی دقت کوچک برای اثبات کارکرد.
- هارنس رگرسیون پرامپت (Prompt Regression Harness): یک ابزار CLI که نسخههای مختلف پرامپت را در برابر یک «مجموعه طلایی» نمرهدهی میکند و اگر رگرسیونی شناسایی شود، بهطور خودکار بیلد (Build) را رد میکند. این پروژه تجسم کامل «انرژی خالص یک SDET» است.
- عامل دستهبندی خودکار (Triage Agent): عاملی که گزارشهای باگ را میخواند، شدت (Severity) را برچسب میزند و پیشنویس بازتولید باگ را آماده میکند، در حالی که همگی توسط حفاظهای (Guardrails) سفارشی کنترل میشوند.
برای بهترین نتیجه، توصیه میشود برای هر پروژه یک پست شفاف نوشته شود که مشکل، رویکرد و نحول اندازهگیری موفقیت را توضیح دهد. در هنگام مصاحبه، کاندیداها تشویق میشوند که با «هارنس رگرسیون پرامپت» شروع کنند، زیرا ارزیابی دقیقاً همان مشکلی است که مدیران AI در حال حاضر با آن دستوپنجه نرم میکنند.
جعبهابزار جامع
برای اجرای این نقشه راه، ابزارهای زیر در چرخه حیات پروژه توصیه میشوند:
- زیربنا: Python, uv, pytest, Jupyter
- مدلها و APIها: Claude, OpenAI, Gemini, Ollama
- ارکستراسیون: LangChain, LlamaIndex, LangGraph, MCP
- برداری و بازیابی: Chroma, Pinecone, Qdrant, pgvector
- ارزیابی: Ragas, DeepEval, promptfoo, Giskard
- انتشار: FastAPI, Streamlit, Docker, HF Spaces
منابع یادگیری و آموزش
برای کسانی که به دنبال دانشی عمیقتر از نقشه راه روزانه هستند، منابع رایگان زیر توصیه شده است:
- Neural Networks: Zero to Hero — دوره ویدئویی رایگان آندره کارپاتی.
- 3Blue1Brown — سری ویدئوهای بصری درباره شبکههای عصبی و ترنسفورمرها.
- Hugging Face LLM Course & docs — مستندات بهروز و کاربردی.
- «Attention Is All You Need» (Vaswani et al., 2017) — مقاله بنیادین ترنسفورمر.
- مستندات ارائهدهندگان — راهنماهای رسمی Anthropic، OpenAI و Google.
- راهنماهای ارزیابی — مستندات شروع سریع для Ragas، DeepEval و promptfoo.
مسیرهای هدایتشده تکمیلی از طریق Playbookهای منتخب در دسترس هستند. برای شروع، GenAI SDET Career Pack (مجموعه ۴ کتاب) توصیه میشود. کاربران پیشرفته میتوانند RAG for SDETs Pack (۷ کتاب) یا MCP Mastery Pack را بررسی کنند. برای کسانی که به سمت سیستمهای سطح تولید (Production-grade) حرکت میکنند، Enterprise LLM Engineering Vault مفاهیم معماری، استقرار، ارزیابی و حاکمیت را پوشش میدهد. بستههای تخصصی دیگر شامل AI Test Automation Pack، AI Governance & Compliance Pack و Complete AI Testing & GenAI Engineering Master Bundle (۱۸ کتاب) است.
این رویکرد اساساً این فرض را که مهندسی AI مختص دارندگان PhD است، تغییر میدهد. این ثابت میکند که دیسیپلین «اثبات اینکه سیستم کار میکند»، حیاتیترین حلقه گمشده در چرخه تولید GenAI است.
گام بعدی شما
- ابزار promptfoo را برای تست مقایسهای نسخههای مختلف پرامپتهای خود امتحان کنید.
- یک سیستم RAG ساده ۴۰ خطی روی یک PDF تخصصی پیادهسازی کنید تا قدرت بازیابی داده را بسنجید.
- روی ساخت یک «هارنس رگرسیون پرامپت» تمرکز کنید؛ چرا که این دقیقاً همان چیزی است که مدیران AI برای تضمین کیفیت میخواهند.
اما زیرساختهای اجرای این مدلها در مقیاس صنعتی پیچیدگیهای بیشتری دارد — به تحلیل ما دربارهی مدیریت هزینههای استنتاج در محیطهای سازمانی مراجعه کنید.



گفتگو