
اگر امروز برای هر درخواست به مدلهای زبانی هزینه میپردازید، احتمالاً نیمی از بودجه شما صرف پاسخ دادن به سؤالاتی میشود که قبلاً هزار بار پاسخ داده شدهاند. این اتلاف منابع، نقطهٔ شکست مالی بسیاری از استارتآپهای هوش مصنوعی در مسیر مقیاسپذیری است. زمانی که یک برنامه AI رشد میکند، اغلب به نقطهای میرسد که هزینه فراخوانیهای تکراری مدلهای زبانی (LLM) از درآمد به ازای هر کاربر پیشی میگیرد.
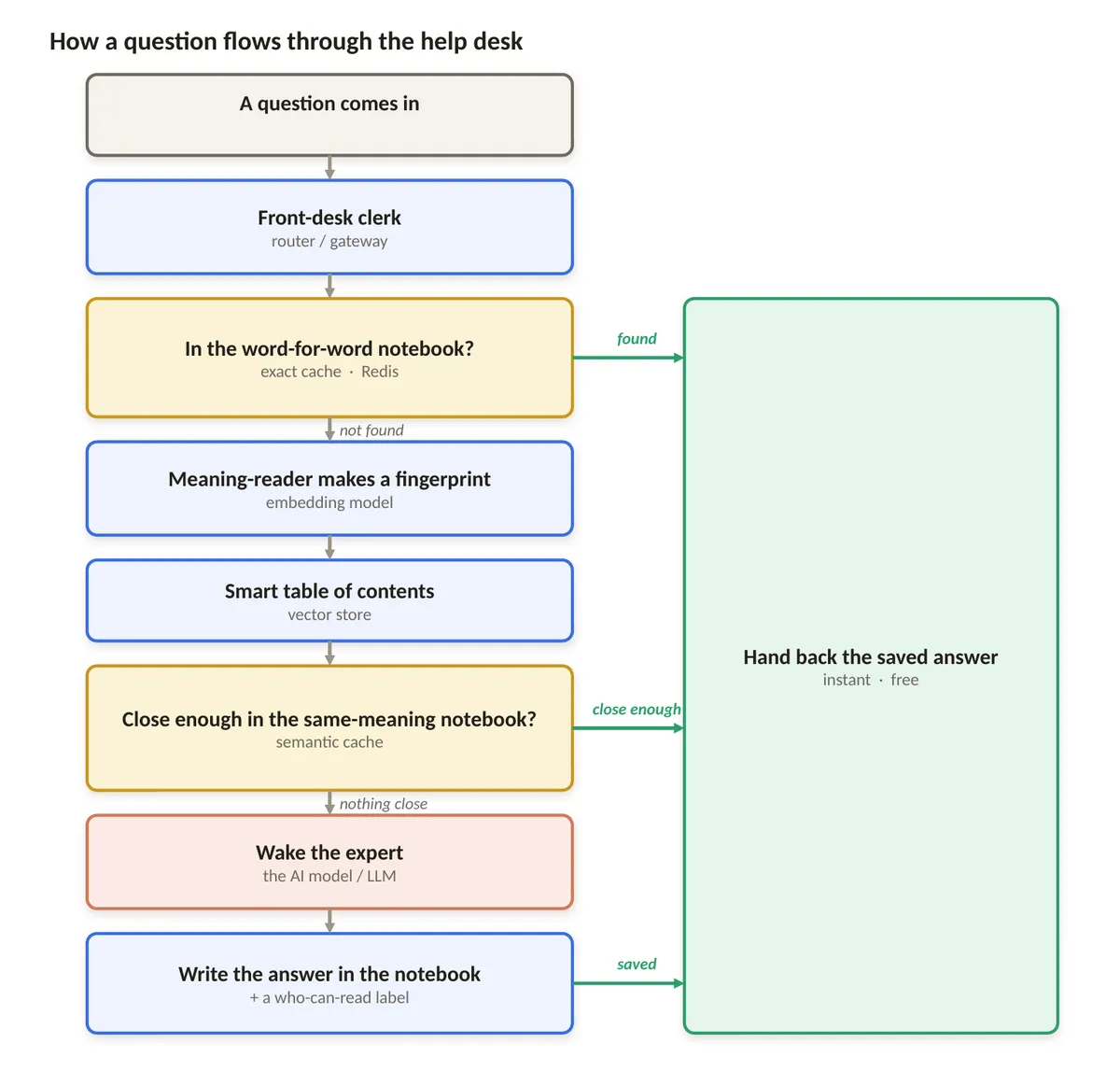
طبق گزارش technical breakdown منتشر شده در ۲۲ ژوئن ۲۰۲۶ در وبسایت dev.to، معماری یک «میز کمک» (Help Desk) میتواند با رهگیری پرسشهای تکراری پیش از رسیدن به مدلهای گرانقیمت، این بحران هزینه را حل کند. اکثر برنامهها با مشکل تکرار مواجهاند؛ هزاران کاربر پنج سؤال مشابه را با کلمات متفاوت میپرسند. بدون حافظه موقت، هر درخواست یک چرخه کامل استنتاج (Inference) — شبیه به خودِ آشپزی، نه دورهی آموزش آشپز — را فعال میکند که منجر به هزینههای خطی و غیرقابلتحمل میشود. این روند باعث میشود مقیاسپذیری گسترده برای اکثر استارتآپها از نظر مالی ناپایدار شود.
تصور کنید در یک میز پذیرش، متصدی ابتدا دفترچههای پاسخهای قبلی را بررسی میکند. بهجای اینکه برای هر پرسشی، متخصص ارشد را در اتاق پشتی بیدار کند، متصدی ابتدا سری از دفترچهها را که حاوی پاسخهای حلشده قبلی است، چک میکند. اگر تطابق پیدا شود، پاسخ فوراً تحویل داده میشود و متخصص undisturbed (بدون مزاحمت) باقی میماند. همانطور که در تحلیل قبلی ما دربارهی بهینهسازی هزینههای مدلهای بازمتن اشاره کردیم، حذف پردازشهای تکراری، کلید بقای تجاری در عصر مدلهای بزرگ است.
معماری چندلایهی حافظه
برای اجرای این سیستم، توسعهدهندگان از پشتهای از سرویسها استفاده میکنند که در واقع نقش آن «متصدی» و «دفترچهها» را ایفا میکنند:
- مسیریاب (Router): ابزارهایی مثل Portkey، Helicone یا Cloudflare AI Gateway هر درخواست را دریافت کرده و تصمیم میگیرند که آیا باید حافظه موقت بررسی شود یا پرسش مستقیماً به مدل AI ارسال گردد. این متصدی مانند یک مدیر ترافیک عمل میکند و تصمیم میگیرد که سؤالات ساده به یک «متخصص جونیور» (ارزانتر) یا سؤالات دشوار به «متخصص ارشد» ارجاع یابند. این رویکرد در واقع بخشی از تغییر پارادایم از مهندسی پرامپت ساده به سمت معماریهای پیچیدهی گردش کار است که در آن مدیریت جریان داده اهمیت بیشتری نسبت به تکتک دستورات دارد.
- حافظه دقیق (Exact Cache): با استفاده از Redis یا Valkey، سیستم سریعاً رشتههای متنی یکسان را جستوجو میکند. اگر کاربر دقیقاً همان عبارت قبلی را تایپ کند، پاسخ در چند میلیثانیه باز میگردد. این سریعترین و ارزانترین لایه است که به صورت کلمه-به-کلمه (Word-for-Word) عمل میکند.
- حافظه معنایی (Semantic Cache): برای سؤالاتی که عبارت متفاوتی دارند اما معنای یکسانی میرسانند، از ابزارهایی مثل Redis LangCache، RedisVL یا GPTCache استفاده میشود. این لایه مانع میشود مدل دوباره پاسخ دهد که «چگونه یک رشته را معکوس کنیم؟» وقتی کاربر جدید میپرسد «چطور یک رشته را برعکس کنم؟» (How do I flip a string?).
- متخصص (LLM): مدلهایی مثل GPT، Claude یا Gemini که نابغه در اتاق پشتی هستند. آنها میتوانند تقریباً به هر چیزی پاسخ دهند اما کند و گراناند. قانون طلایی این میز پذیرش است که متخصص را فقط برای سؤالاتی بیدار کنند که هرگز قبلاً پاسخ داده نشدهاند.
سازوکار تطبیق معنایی
حافظه معنایی برای تشخیص شباهت دو پرسش، بر یک فرآیند دو مرحلهای تکیه دارد. ابتدا یک مدل بردار معنایی (Embedding Model) — مثل کارت معرفی عددی برای هر واژه که میگوید این کلمه «همسایهی» چه کلمات دیگری است — مانند مدل text-embedding-3-small شرکت OpenAI، پرسش را به یک «اثر انگشت معنایی» یا بردار (Vector Embedding) تبدیل میکند. این اثر انگشت، جوهره مفهومی پرسش را بدون توجه به کلمات خاص بهکار رفته نمایش میدهد. دو پرسش با معنای یکسان، اثر انگشتهای تقریباً مشابهی میگیرند.
در مرحله دوم، یک پایگاهداده برداری (Vector Store) مانند Redis Search، pgvector، Qdrant یا Pinecone به عنوان یک فهرست هوشمند (Smart Table of Contents) عمل میکند. بهجای اسکن کردن تکتک پاسخهای ذخیره شده، پایگاهداده برداری مستقیماً به مشابهترین اثر انگشتها میپرد. این مکانیزم باعث میشود سرعت جستوجو حتی زمانی که میلیونها پاسخ ذخیره شده است، بسیار بالا بماند.
تنظیم درجهٔ «به اندازه کافی مشابه»
یک مؤلفه حیاتی در اینجا، «درجه شباهت» یا آستانه شباهت (Similarity Threshold) است. بر اساس راهنمای dev.to، نزدیکی دو مفهوم با معیار شباهت کسینوسی (Cosine Similarity) بین ۰ تا ۱ اندازهگیری میشود. یک نقطه بهینه (Sweet spot) رایج برای این آستانه، بهویژه برای مدلهایی مانند text-embedding-3-small، بین ۰.۸۵ و ۰.۹۰ است.
- آستانه پایین/سست (Too Loose): اگر درجه بیش از حد سست باشد، سیستم پاسخهایی را برمیگرداند که فقط «شبیه» به سؤال بودند اما معنای متفاوتی داشتند، که منجر به ارائه پاسخهای غلط میشود.
- آستانه بالا/سختگیر (Too Strict): اگر سیستم بیش از حد سختگیر باشد، تطابقهای واقعی را نادیده میگیرد و متخصص را بی دلیل بیدار میکند که منجر به اتلاف هزینه و زمان میشود.
توصیه میشود این درجه برای هر موضوع (Topic) بهطور مجزا تنظیم شود: برای تعاریف ساده، حالت سست و برای هر موردی که پاسخ غلط در آن هزینه یا ریسک بالایی دارد، حالت سختگیرانه اعمال شود. زمانی که یک تطابق فقط به سختی از آستانه عبور میکند، سیستم باید بهجای اعتماد کورکورانه، آن را مجدداً بررسی کند.
چرخهٔ حیات یک درخواست
هر سؤال وقتی به میز پذیرش میرسد، برای به حداقل رساندن فراخوانی متخصص، این مسیر سختگیرانه را طی میکند:
۱. نرمالسازی (Normalization): متصدی سؤال را مرتب میکند؛ تبدیل متن به حروف کوچک و حذف فضاهای خالی (Trim). برخی تیمها «کلمات توقف» (Stop-words) مانند the, a, یا please را حذف میکنند تا حافظه دقیق بدون نیاز به مدل بردار، هوشمندانهتر تطبیق یابد.
۲. جستوجوی دقیق (Exact Lookup): بررسی دفترچه کلمه-به-کلمه در Redis/Valkey. اگر یافت شود، پاسخ فوراً بازگردانده میشود. این مرحله به قدری ارزان است که همیشه در اولویت است.
۳. انگشتگذاری (Fingerprinting): در صورت شکست مرحله قبل، مدل بردار معنایی یک اثر انگشت (بردار) ایجاد میکند.
۴. جستوجوی معنایی (Semantic Search): از اثر انگشت برای پرسوجو در پایگاهداده برداری استفاده میشود. در اینجا فیلترهایی اعمال میشود تا کاربر فقط صفحاتی را ببیند که بر اساس برچسب (Label) آنها، اجازه دسترسی دارد.
۵. بررسی آستانه (Threshold Check): اگر امتیاز شباهت کسینوسی از حد نصاب (مثلاً ۰.۸۵+) بیشتر باشد، پاسخ ذخیره شده بازگردانده میشود.
۶. اجرای متخصص (Expert Execution): تنها در صورت شکست تمام مراحل قبلی، مدل LLM (مانند GPT, Claude, Gemini) بیدار میشود. متخصص پاسخ جدیدی میدهد که سپس با یک برچسب محدوده و تاریخ انقضا برای استفاده کاربران آینده در دفترچهها ذخیره میگردد.
بررسی عمیق: درون یک صفحهٔ ذخیره شده
در طراحی سطح پایین (LLD)، هر پاسخ ذخیره شده به عنوان یک «صفحه» واحد در دفترچه در نظر گرفته میشود. برای سازماندهی و امنیت سیستم، هر صفحه باید متادیتای خاصی را نگه دارد:
- پرسش اصلی: متن دقیقی که باعث تولید پاسخ شد (مثلاً: "how do I reverse a string in python").
- پاسخ متخصص: خروجی کامل ارائه شده توسط مدل LLM.
- اثر انگشت معنایی: ردیف طولانی از اعداد (Vector Embedding) که برای تطبیق معنایی استفاده میشود.
- برچسب (Label): یک تگ محدوده (Scope tag) که مشخص میکند این صفحه برای «همه» (General) است یا برای یک کاربر خاص (مثلاً: "Only Abhi").
- تاریخ انقضا (Expiration Date): یک Timestamp که نشان میدهد صفحه چه زمانی باید پاک شود تا از «پوسیدگی دادهها» (Data Rot) و قدیمی شدن اطلاعات جلوگیری شود.
حریم خصوصی و امنیت: جداسازی کاربران با برچسبها
حریم خصوصی از طریق «برچسبهای محدوده» (Scope Tags) یا برچسبهای مستاجر (Tenant Labels) مدیریت میشود. اینگونه سیستم تضمین میکند کاربری که وضعیت سفارش خود را میپرسد، هرگز پاسخ ذخیره شدهای متعلق به مشتری دیگر را دریافت نکند. امنیت در لحظه ذخیرهسازی در برچسب تزریق میشود؛ بنابراین فهرست مطالب (Table of Contents) هرگز صفحات خصوصی را به کاربران اشتباه نشان نمیدهد و نیازی به تصمیمگیری در زمان واقعی (Real-time) هنگام جستوجو نیست.
برای تصمیمگیری درباره اینکه چه چیزی در دفترچه مشترک «همگانی» ذخیره شود، سیستم میپرسد: «آیا این پاسخ برای همه یکسان است یا فقط برای این شخص؟»
- نشانههای خصوصی (Private Clues): سیستم به دنبال کلمات کلیدی مانند «مال من»، «این» یا «من دارم دریافت میکنم» (I'm getting) میگردد.
- نیازمندیهای دادهای: اگر فرآیند پاسخدهی مستلزم دسترسی به دادههای خصوصی فرد (مانند جستوجوی یک سفارش) بوده باشد، بهطور خودکار برچسب «فقط این شخص» میخورد.
- داور کوچک (The Small Judge): برای موارد واقعاً مبهم، از یک «داور کوچک» (یک طبقهبندیکننده LLM ارزانقیمت) استفاده میشود. این داور فقط برای موارد مشکوک فراخوانی میشود، زیرا اجرای داور برای هر سؤال، هزینهای برابر با کل صرفهجوییهای سیستم خواهد داشت.
اگر سیستم همچنان درباره عمومی یا خصوصی بودن اطلاعات نامطمئن باشد، پیشفرض را بر روی «عدم اشتراک» (Don't share) قرار میدهد. پرسیدن مجدد از متخصص بسیار بهتر از ارائه پاسخ اشتباه یا خصوصی به کاربر است.
مقیاسپذیری در حجم میلیونها کاربر
بسیاری از توسعهدهندگان نگران این هستند که دفترچهها بیش از حد حجیم شوند. اما دفترچه مشترک بر اساس تعداد «پرسشهای متفاوت» رشد میکند، نه تعداد کل کاربران. حتی با میلیونها کاربر، تمایل این است که آنها همان سؤالات محبوب را مکرراً بپرسند، به این معنی که دفترچه نسبتاً کوچک میماند.
برای مدیریتپذیر نگه داشتن سیستم، استراتژیهای زیر به کار میروند:
- TTL (Time-to-Live): برخی یادداشتها روی «کاغذهای یادداشت منقضیشونده» (حافظه نشست یا Session memory) برای گفتگوهای کوتاهمدت نوشته میشوند. اینها بهطور خودکار پس از مدتی حذف میشوند تا انباشته نشوند.
- قطعهبندی (Sharding): دفترچههای بزرگ با استفاده از Redis Cluster بین چندین «متصدی» تقسیم میشوند. این کار اجازه میدهد سیستم با افزودن کمکیهای موازی، بهصورت افقی مقیاسپذیر شود.
- اندیسگذاری هوشمند (Smart Indexing): پایگاهداده برداری تضمین میکند که سیستم هرگز تمام میلیونها صفحه را نمیخواند؛ بلکه اندیس مستقیماً به محتملترین تطابقها میپرد.
- حفاظت در برابر هجوم (Cache Stampede Protection): وقتی یک سؤال «ویروسی» میشود (مثلاً ۱۰,۰۰۰ نفر همزمان یک سؤال جدید را میپرسند)، سیستم از Request Coalescing (Single-flight) استفاده میکند. اولین کاربر متخصص را بیدار میکند و ۹,۹۹۹ نفر دیگر لحظهای منتظر میمانند تا پاسخ همان صفحه تازه نوشته شده را بخوانند. اینگونه ۱۰,۰۰۰ فراخوانی متخصص به یک فراخوانی تبدیل میشود.
تخفیف ارائهدهندگان در برابر دفترچه شخصی
بسیار مهم است که این معماری را از «حافظه پیشوندی» (Prefix Caching) ارائه شده توسط OpenAI، Anthropic یا Gemini متمایز کنیم. در حالی که حافظه ارائهدهنده تخفیفی کوچک برای متنهای طولانی پیشزمینه (Background text) که مدل لحظاتی پیش خوانده است میدهد، تفاوتهای کلیدی وجود دارد:
- تولید (Generation): در حافظه پیشوندی، متخصص همچنان هر بار یک پاسخ تازه مینویسد. اما دفترچه شخصی، متخصص را بهطور کامل دور میزند.
- طول عمر (Lifespan): تخفیفهای ارائهدهنده کوتاهمدت هستند و معمولاً طی چند دقیقه غیرفعال بودن منقضی میشوند. دفترچه شخصی شما میتواند پاسخها را تا هر زمانی که بخواهید نگه دارد.
یک حافظه معنایی اختصاصی، تأخیر را در مقایسه با پاسخ معمولی ۳ تا ۱۰ ثانیهای LLM، تا ۹۹٪ کاهش داده و به زیر ۵۰ میلیثانیه میرساند. جایی که تخفیف ارائهدهنده یک پسانداز کوچک است، دفترچه شخصی یک میانبر (Bypass) کامل است.
اثرات مالی و عملکردی
برای برنامهای با ۱۰۰ هزار سؤال در ماه و هزینه ۰.۰۱ دلار به ازای هر فراخوانی (تقریباً ۱,۰۰۰ دلار ماهانه)، حافظهای که ۵۰٪ ترافیک را جذب کند، حدود ۵۰۰ دلار در ماه صرفهجویی میکند. در این مدل، اولین کسی که سؤال جدید میپرسد، کل هزینه و تأخیر را «پرداخت» میکند؛ اما تمام کاربران بعدی بهصورت رایگان و سریع پاسخ را دریافت میکنند. این تغییر، مدل هزینه AI را از «پرداخت به ازای هر فکر» به «پرداخت به ازای هر نوآوری» تغییر میدهد.
موارد شکست و حفاظها
هیچ سیستمی کامل نیست. راهنمای dev.to سه حالت شکست اصلی و حفاظهای متناظر آنها را برجسته میکند:
- پاسخهای قدیمی (Out-of-date): جهان تغییر میکند اما دفترچه پاسخ قدیمی را نگه داشته است. حفاظ: تاریخهای انقضای سختگیرانه و پاک کردن صفحات زمانی که حقایق زیربنایی تغییر میکنند.
- نشت حریم خصوصی (Privacy leaks): فرد اشتباه پاسخ شخصی را میبیند. حفاظ: سیستم برچسبگذاری محدوده؛ صفحات شخصی در طول فرآیند جستوجو برای سایر کاربران بهطور منطقی نامرئی هستند.
- خطاهای سستی (Looseness errors): یک تطبیق معنایی بیش از حد آزاد است و پاسخ غلط میدهد. حفاظ: تنظیم دقیق آستانه شباهت، بازبینی مجدد تطابقهای مرزی و پیشفرض «پرسیدن از متخصص» در صورت تردید.
توسعهدهندگان باید ترتیب ساخت را رعایت کنند: ابتدا دفترچه کلمه-به-کلمه (سادهترین و بیشترین سود)، سپس دفترچه معنایی، بعد پیادهسازی برچسبها برای امنیت و در نهایت قطعهبندی (Sharding) زمانی که حجم کاربران ایجاب کند. هدف نهایی این است که متخصص گرانقیمت فقط و فقط سؤالات واقعاً جدید را ببیند.
گام بعدی شما
- اگر هزینه API شما در حال رشد سریع است، ابتدا یک لایه Exact Cache با Redis پیاده کنید تا سادهترین تکرارها حذف شوند.
- برای پیادهسازی Semantic Cache، مدل text-embedding-3-small را با آستانه شباهت ۰.۸۷ تست کنید و بر اساس نرخ خطا آن را تنظیم کنید.
- سیستم برچسبگذاری (Labeling) را از همان روز اول طراحی کنید تا در آینده مجبور به بازنویسی کل پایگاهداده برداری برای امنیت نشوید.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell و تأثیر آنها بر هزینه استنتاج مراجعه کنید.



گفتگو