
تصور کنید تمام محدودیتهای سختافزاری شما برای ساخت یک مدل پزشکی دقیق، تنها به دلیل یک کتابخانه نرمافزاری باشد. اگر هنوز فکر میکنید برای رسیدن به دقتهای بالینی حتماً باید از GPUهای انویدیا استفاده کنید، باید بدانید که بازی تغییر کرده است.
در ۸ می ۲۰۲۶، پروژه MedQA یک خط لوله (Pipeline) کامل برای تنظیم دقیق (Fine-tuning) مدل Qwen3-1.7B را معرفی کرد. به نقل از گزارش huggingface.co، این فرآیند بهطور کامل روی سختافزار AMD Instinct MI300X و محیط ROCm 6.1 اجرا شده و هیچ وابستگی به CUDA نداشته است.
این موفقیت مدیون ظرفیت عظیم سختافزاری تراشه MI300X است که دارای ۱۹۲ گیگابایت حافظه HBM3 است. این فضای گسترده باعث شد تا تیم توسعهدهنده از روشهای رایج برای کاهش مصرف حافظه دست بکشند:
- دقت بالا: آموزش در حالت کامل fp16 انجام شد و دیگر نیازی به ترفندهای کوانتیزاسیون (Quantization) ۴ بیتی یا ۸ بیتی نبود.
- بهینهسازی: با استفاده از روش لورا (LoRA) از طریق کتابخانه PEFT، تنها حدود ۲.۲ میلیون پارامتر (۰.۱۵٪ از مدل) آموزش دیدند.
- سرعت خیرهکننده: آموزش روی ۲,۰۰۰ نمونه از مجموعه داده MedMCQA تنها ۵ دقیقه زمان برد.
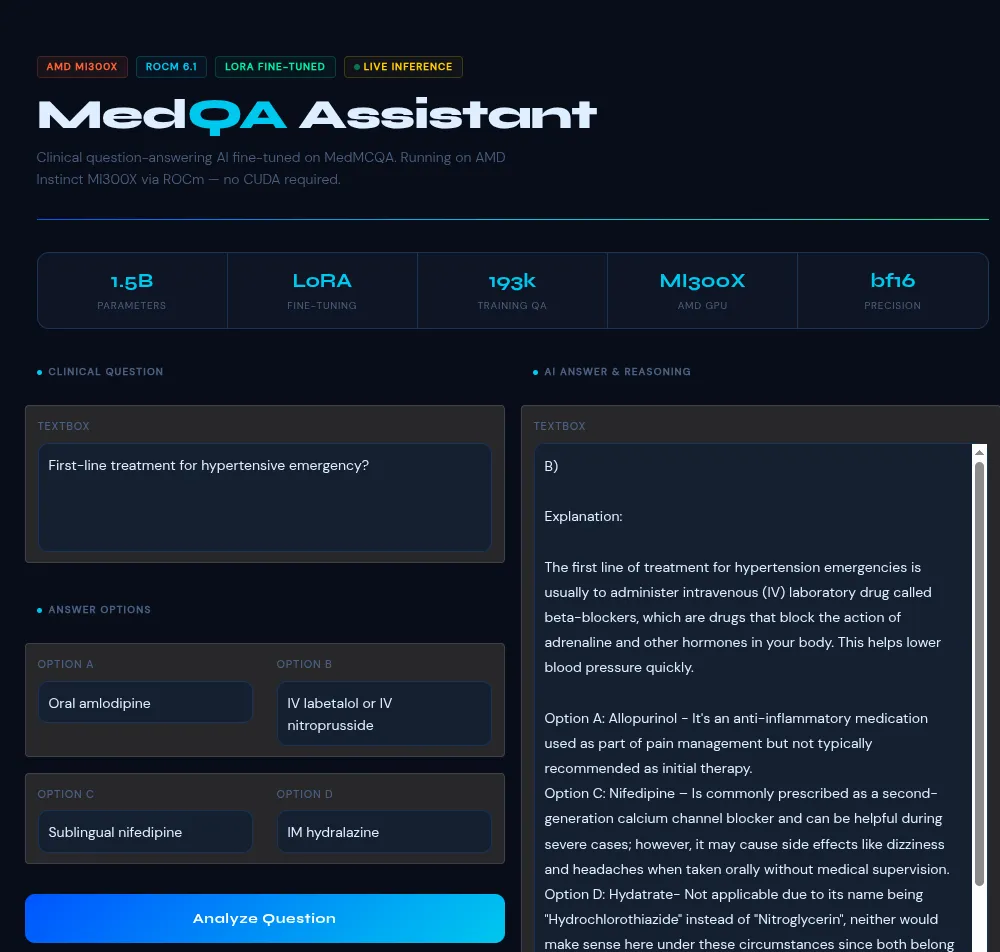
بر اساس مستندات این پروژه، مدل نهایی فراتر از انتخاب گزینههای چهارگزینهای عمل میکند و استدلالهای بالینی خود را نیز توضیح میدهد. برای مثال، در مواجهه با درمانهای اورژانس فشار خون، مدل بهدرستی داروی لابتالول وریدی را شناسایی کرد و توضیح داد که چرا داروهای خوراکی برای چنین شرایط بحرانی بسیار کند هستند.
همانطور که در تحلیلهای قبلی ما دربارهی دموکراتیزه شدن قدرت محاسباتی (Compute) اشاره کردیم، شکستن انحصار سختافزاری یک ضرورت است. MedQA با اثبات سازگاری کامل اکوسیستم HuggingFace (شامل Transformers، PEFT و Accelerate) با ROCm، مانع بزرگی را برای پژوهشگرانی که از سختافزارهای AMD استفاده میکنند، از میان برداشت.
اما این تنها شروع مسیر است؛ ادغام این مدلها با سیستمهای تولید بازیابیافزا (RAG) میتواند استانداردهای تشخیص پزشکی را دگرگون کند.
گام بعدی شما
- اگر از سختافزارهای AMD استفاده میکنید، محیط ROCm 6.1 را برای اجرای مدلهای زبانی بررسی کنید.
- برای کاهش هزینههای آموزش، متد LoRA را جایگزین آموزش کامل پارامترها کنید.
- نتایج مدلهای آموزشدیده روی مجموعه داده MedMCQA را با مدلهای عمومی مقایسه کنید.



گفتگو