
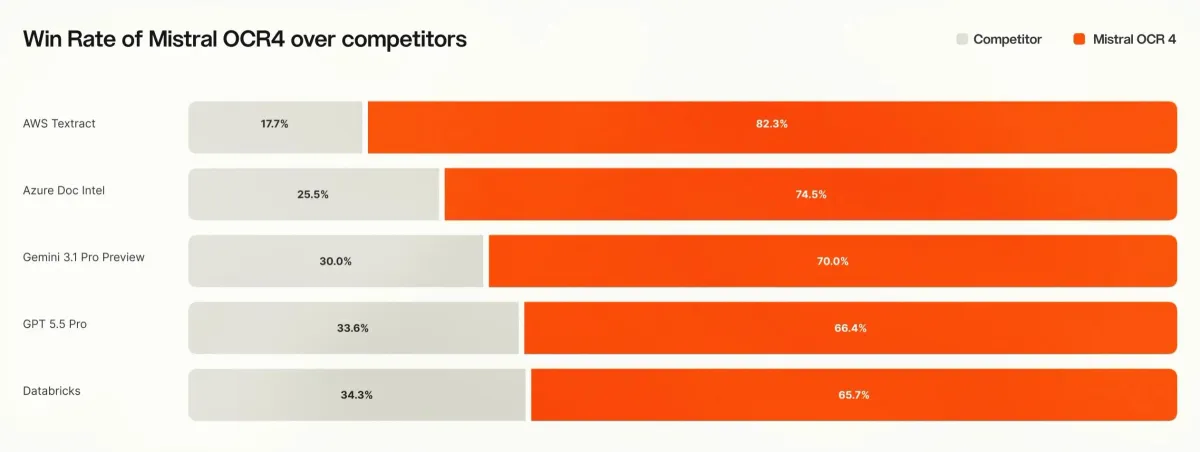
اگر امروز برای استخراج داده از اسناد پیچیده هزینه میکنید، احتمالاً با مشکل «تکه تکه شدن» اطلاعات در سیستمهای بازیابی مواجه هستید. مدل Mistral OCR 4 دقیقاً برای حل همین گره کور آمده است تا اسناد را نه فقط بخواند، بلکه آنها را نقشهبرداری کند. این موتور جدید استخراج، در ارزیابیهای رودرروی انسانی، نرخ برد میانگین ۷۲ درصدی را در برابر سیستمهای پیشرو هوش مصنوعی مستندات (Document AI) به دست آورده است.
این انتشار، نقطه تمرکز را از تبدیل ساده متن به یک نمایش کامل و ساختارمند از اسناد تغییر میدهد. این مدل به گونهای طراحی شده است که یک مدل کوچک و متمرکز باشد و به عنوان یک جزء حیاتی برای ورود دادهها (Ingestion) در جستوجوی سازمانی، RAG و خط لولههای بازیابی تخصصی عمل کند.
بسیاری از سازمانها با مشکل «آخرین مایل» در پذیرش اسناد دست و پنجه نرم میکنند؛ جایی که فایلهای PDF و تصاویر به رشتههای متنی بههمریخته تبدیل میشوند که باعث شکست خط لولههای RAG میگردد. با تکیه بر پوششهای قبلی ما در مورد اینکه چگونه ابزارهایی مانند mistral.rs مهارتهای محلی عاملها را فعال میکنند، OCR 4 بدنه ساختاری لازم را فراهم میکند تا عاملهای هوشمند بتوانند واقعاً روی اسناد عمل کنند، نه اینکه صرفاً آنها را بخوانند. این رویکرد بهینهسازی عملکرد در مدلهای کوچکتر، یادآور تلاشهای مشابه در پروژههایی مانند AliyunConsoleAgent است که نشان داد چگونه میتوان به عملکرد مدلهای پیشرو با هزینهای بهمراتب کمتر دست یافت.
تصور کنید یک عامل AI را دارید که فقط یک بلوک متن را نمیبیند، بلکه دقیقاً میداند یک امضا در کجا قرار دارد، کدام بخش یک جدول است و مدل با چه میزان اطمینانی یک کلمه خاص را تشخیص داده است. این سطح از جزئیات، یک PDF خام را به یک نقشه ماشینخوان تبدیل میکند و به عاملها اجازه میدهد تا وظایف پیچیدهای مانند پر کردن فرمها، پردازش صورتحسابها و بررسیهای تطبیقی (Compliance) را انجام دهند.
قابلیتهای فنی و خروجیهای ساختارمند
مدل Mistral OCR 4 با فاصله گرفتن از نسلهای قبلی، چیزی فراتر از Markdown برمیگرداند. در حالی که مدلهای قبلی بر تبدیل صفحه به متن و جداول تمیز متمرکز بودند، OCR 4 یک نمایش ساختارمند ارائه میدهد که در آن هر بلوک متنی مکانیابی (Localized) و طبقهبندی شده است. این امر به سیستمهای پاییندستی اجازه میدهد تا نه تنها بدانند سند چه میگوید، بلکه بدانند هر عنصر در کجا قرار دارد و چه نقشی ایفا میکند.
طبق مستندات فنی، هر درخواست شامل محتوای استخراجشده، کادرهای محدودکننده (Bounding Boxes)، نوع بلوک و امتیاز اطمینان (Confidence Score) است. این ویژگیها چندین گردش کار خاص در مراحل پاییندستی را پشتیبانی میکنند:
- تکهبندی معنایی برای RAG: بلوکهای تمیز و طبقهبندیشده به واحدهای بازیابی (Retrieval Units) بهتری تبدیل میشوند.
- مبانی ساختاری برای عاملها: امکان انتقال از مرحله «خواندن» به «عمل کردن» (به عنوان مثال، پردازش صورتحساب یا پر کردن فرم).
- محتوای ساختارمند برای رابطها (Connectors): ارائه خروجیهای سازگار و دارای نوع (Typed Output) برای خط لولههای نمایهسازی.
ویژگیهای کلیدی خروجی عبارتاند از:
- کادرهای محدودکننده (Bounding Boxes): مکانیابی دقیق متن برای هایلایت کردن در بستر متن (In-context highlighting) و ایجاد خط لولههای دادهای قابل اعتماد. این قابلیت، بیشترین درخواست کاربران از میسترال بود.
- طبقهبندی بلوکها: دستهبندی المانها به بلوکهای تایپشدهی خاص، از جمله عناوین (Titles)، جداول، معادلات، امضاها و موارد دیگر.
- امتیاز اطمینان (Confidence Scores): معیارهای داخلی که برای هر صفحه و هر کلمه تولید میشوند. این امتیازات باعث میشوند استنادات مدل مستند به منبع باشد و امکان سانسور (Redaction) و تایید توسط انسان (Human-in-the-loop) فراهم شود.
دامنه چندزبانه و پشتیبانی از فرمتها
این مدل از ۱۷۰ زبان در ۱۰ گروه زبانی متمایز پشتیبانی میکند. طبق گزارش میسترال، پیشرفتهای قابلاندازهای در زبانهای نادر و کممنبع مشاهده شده است؛ از جمله زبانهای گرجی، بنگالی، ارمنی، عبری، یونانی، گجراتی، تامیل، مالایالم، کناڈا، تلوگو، هندی و ژاپنی. در این زبانها، بسیاری از سیستمهای رقیب معمولاً دچار افت کیفیت میشوند، اما OCR 4 دقت بالایی را در تمامی این خطوط متنوع حفظ میکند.
علاوه بر زبان، Mistral OCR 4 طیف وسیعی از فرمتهای رایج سازمانی را میپذیرد تا با سیلوهای دادهای شرکتها سازگار باشد. فرمتهای پشتیبانی شده عبارتاند از:
- DOC
- PPT
- OpenDocument
بنچمارکهای جامع و عملکرد
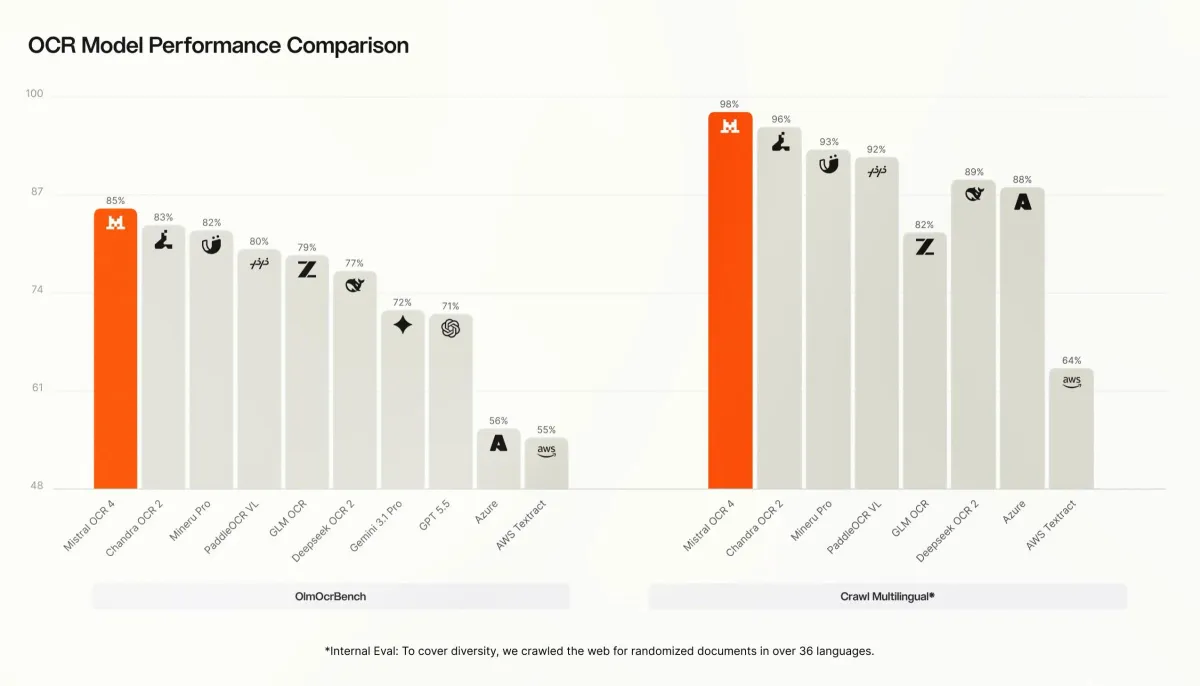
برای ارزیابی OCR 4، میسترال آن را با مدلهای پیشرو OCR بومی (AI-native)، مدلهای چندمنظوره پیشرو (Frontier Models)، سرویسهای مستندات سازمانی و نسخه قبلی یعنی Mistral OCR 3 مقایسه کرد. بر اساس گزارش mistral.ai، مدل OCR 4 به امتیاز کلی ۸۵.۲۰ در بنچمارک عمومی OlmOCRBench و امتیاز ۹۳.۰۷ در OmniDocBench دست یافت. همچنین این مدل با امتیاز ۰.۹۸ در ارزیابی داخلی Crawl Multilingual پیشتاز است.
با این حال، میسترال هشدار میدهد که این اعداد کلی به دلیل مصنوعات (Artifacts) خاص هر بنچمارک میتوانند گمراهکننده باشند. هنگام بررسی عدم تطابقها، شرکت دریافت که بسیاری از آنها خطای مدل نبودند، بلکه ناشی از موارد زیر بودند:
- خطاهای دادهی مرجع (Ground-truth): حاشیهنویسیهای مرجعی که نادرست هستند؛ مثلاً نام نویسنده در مرجع غلط تایپ شده اما مدل آن را درست از روی صفحه خوانده است، یا موارد مربوط به مناطق سانسور شده.
- نمایههای ریاضی معادل: رشتههای مختلف LaTeX که یکسان رندر میشوند، اغلب توسط ابزارهای مقایسه رشتهای (String Comparison) به عنوان عدم تطابق شناسایی میشوند، در حالی که معادله رندر شده درست است.
- بخشبندی معادلات: اینکه یک عبارت به صورت یک معادله واحد باشد یا به قطعات درونخطی تقسیم شود، بر امتیاز تطابق اثر میگذارد، حتی اگر محتوای رندر شده یکسان باشد، زیرا تطبیقدهنده نمیتواند قطعات را تراز کند.
- ترتیب خواندن چندستونی: استخراج صحیح کلماتی که در مرز ستونها تقسیم شدهاند (مانند "certifi-cates")، اغلب بر اساس پیشفرضهای ترتیب ستونها به عنوان شکست امتیازدهی میشوند.
- تخصیص نوع بلوک: بنچمارکها اغلب انتظار سربرگها (Headers) یا پانویسها (Footers) را ندارند. حذف آنها میتواند باعث شود بنچمارک به اشتباه عنوان گمشده یک صفحه را علامتگذاری کند.
این مصنوعات بهطور خاص در اسناد ریاضی، علمی و چندستونی متمرکز هستند و اغلب خروجیهای صحیح را جریمه میکنند. برای دور زدن این اثرات، شرکت یک مطالعه کور (Blind Study) با ارزیابان مستقل روی بیش از ۶۰۰ سند واقعی در بیش از ۱۲ زبان (که از تامینکنندگان شخص ثالث تهیه شده بود) انجام داد. ارزیابان در اکثر موارد در تمامی سیستمهای تست شده، OCR 4 را ترجیح دادند.
بهرهوری در دنیای واقعی نیز چشمگیر است. ایدان دونوهو، مهندس AI در Rogo، اشاره کرد که OCR 4 در یک مجموعهداده پرسوجوی مالی (Financial QA) که سرشار از نمودار و شکل بود، به دقتی معادل پارسرهای عاملمحور رسید، در حالی که هزینه آن تقریباً ۸ برابر کمتر و تأخیرش ۱۷ برابر پایینتر بود. به همین ترتیب، ایوان میخائیلوف از Anaqua گزارش داد که این مدل در هر صفحه تقریباً ۴ برابر سریعتر از تامینکننده قبلی آنها است، که برای گردشهای کاری با حجم بالای پروندهها (Docketing) و زمانبندیهای مالکیت معنول (IP) حیاتی است.
گزینههای استقرار و مدلهای قیمتگذاری
یکی از تاثیرگذارترین ویژگیهای OCR 4 ردپای (Footprint) آن است. این مدل به قدری فشرده است که در یک کانتینر واحد اجرا میشود. این ویژگی به سازمانهایی با الزامات سختگیرانه در مورد محل استقرار دادهها (Data-residency)، حاکمیت داده و انطباق قانونی اجازه میدهد تا دادههای اسناد خود را بهطور کامل در زیرساختهای خود میزبانی کنند. استقرار مدیریتشده توسط کاربر (Self-managed) بهطور خاص برای مشتریان سازمانی در دسترس است.
برای کسانی که از API استفاده میکنند، مدل از طریق Mistral Studio، Amazon SageMaker و Microsoft Foundry در دسترس است. همچنین این مدل بهزودی به Snowflake Parse Document اضافه خواهد شد. کیمی گروال، معاون مشارکتهای اکوسیستم AI در مایکروسافت، اشاره کرد که در دسترس بودن Document AI با OCR 4 در Microsoft Foundry، نقطه عطفی در این مشارکت برای ارائه راهکارهای مقیاسپذیر و قابلاعتماد است.
ساختار قیمتگذاری برای پشتیبانی از هر دو نوع پردازش تعاملی و دستهای با حجم بالا طراحی شده است:
- API استاندارد: ۴ دلار بهازای هر ۱,۰۰۰ صفحه.
- API دستهای (Batch): ۲ دلار بهازای هر ۱,۰۰۰ صفحه (۵۰٪ تخفیف برای کارهای با throughput بالا).
- Document AI: ۵ دلار بهازای هر ۱,۰۰۰ صفحه (یک مسیر بدون کد در سطح اپلیکیشن با لایههای ساختارمند اضافه میکند).
ادغام با Mistral Search Toolkit
مدل Mistral OCR 4 به عنوان یک جزء اصلی ورود داده برای Mistral Search Toolkit عمل میکند؛ یک چارچوب جستوجوی متنباز و ترکیبپذیر که در اجلاس AI Now معرفی شد. با ارائه بلوکهای طبقهبندی شده، این مدل «تکهبندی معنایی» را ممکن میسازد، جایی که بلوکهای تمیز و طبقهبندی شده به واحدهای بازیابی برتری برای RAG و جستوجوی سازمانی تبدیل میشوند.
این خروجی ساختارمند، ورودیهای آماده برای استناد (Citation-ready) را به گردش کار گستردهتر ورود، بازیابی و ارزیابی ابزار جستوجو میرساند. توسعهدهندگان میتوانند بین دو حالت تعاملی اصلی انتخاب کنند:
۱. حالت استخراج خالص (Pure Extraction Mode): برای جایگذاری استخراج سریع مستقیماً در یک اپلیکیشن یا عامل استفاده میشود. توسعهدهندگان با پاسخهای خام، کادرهای محدودکننده و امتیازات اطمینان کار میکنند تا منطق پاییندستی سفارشی خود را پیش ببرند. این حالت برای کاربرانی که کنترل کامل روی throughput و هزینه از طریق Batch API میخواهند، ایدهآل است.
۲. حالت Document AI: از طریق همان نقطه اتصال (Endpoint) با پارامترهای اضافی قابل دسترسی است. این حالت باعث فراخوانی مدل mistral-small-2603 میشود تا خروجی OCR را به یک طرح JSON تعریفشده توسط کاربر تغییر شکل دهد. همچنین میتواند تصاویر شناسایی شده را از طریق یک فراخوانی اضافی مدل بینایی-زبان (Vision-Language Model) برای هر تصویر، با JSON ساختارمند حاشیهنویسی کند، یا با یک پرامپت سفارشی برای هدایت نحوه تفسیر یا خلاصهسازی کل سند استفاده شود.
موارد استفاده توصیه شده و محدوده
مدل OCR 4 برای خط لولههای با حجم بالا و گردشهای کاری تعاملی در چندین بخش طراحی شده است. کاربران اولیه در حال حاضر از آن برای دیجیتالسازی آرشیوهای شرکت، تبدیل صورتحسابها به فیلدهای ساختارمند و استخراج متن تمیز از گزارشهای فنی و علمی استفاده میکنند.
حوزههای کاربردی خاص عبارتاند از:
- حقوق، مالی و بهداشت: ارائه مبانی ساختاری برای گردشهای کاری عاملمحور مانند پردازش صورتحساب و بررسیهای تطبیقی.
- خط لولههای RAG: تولید پاسخهای مستند به منبع از طریق محتوای ساختاریافته و آماده استناد. با Search Toolkit، خروجی میتواند مستقیماً به خط لولههای بازیابی ارسال شود.
- خط لولههای داده: استفاده از امتیازات اطمینان برای ایجاد صفهای بازبینی انسانی کارآمد برای سانسورها و استخراج فرمها.
- پایگاههای دانش سازمانی: عمل به عنوان یک جزء منبع داده برای ورود دادههای سفارشی و استخراج موجودات (Entity Extraction).
بسیار مهم است که موارد خارج از محدوده (Out-of-scope) را بدانیم. OCR 4 یک مدل درک مستند است، نه یک تصمیمگیرنده. این مدل برای تشخیص پزشکی، مشاوره یا قضاوت حقوقی، تصمیمات مالی با ریسک بالا، سیستمهای حساس به ایمنی، پردازشهای حساس به تأخیر/در لحظه (Real-time) یا ورودیهای غیرمستندی مانند صوت و ویدیو خام طراحی نشده است.
تحلیل: تغییر به سمت حاکمیت مستندات
این انتشار نشاندهنده گذار از «هوش مصنوعی به عنوان سرویس» به «هوش مصنوعی به عنوان یک دستگاه» (Appliance) است. با کوچک کردن یک مدل SOTA OCR در یک کانتینر واحد، میسترال بخشهای با انطباق بالا — حقوقی، بهداشت و مالی — را هدف قرار داده است؛ جایی که ارسال اسناد حساس به یک ابر (Cloud) شخص ثالث غیرقابل پذیرش است. این حرکت، پردازش دستهای با هزینه کم و throughput بالا را در حالی که حاکمیت کامل دادهها حفظ میشود، ممکن میسازد.
برای کاربر نهایی، برد نه تنها در دقت، بلکه در قابلیت اطمینان است. گنجاندن امتیازهای اطمینان به این معنی است که توسعهدهندگان راستی راستی میتوانند «صفهای استثنا» (Exception Queues) بسازند؛ جایی که AI حدود ۹۵٪ از صورتحسابها را بهطور خودکار پردازش میکند و تنها ۵٪ از صفحاتی که اطمینان پایینی دارند را برای بررسی انسانی علامتگذاری میکند. این امر بهطور مؤثر قمار «همه یا هیچ» در خط لولههای فعلی OCR را از بین میبرد.
گام بعدی
توسعهدهندگان باید «کتابچه راهنمای شروع کار با OCR 4» (Cookbook) را برای پیادهسازی منطق کادرهای محدودکننده و طبقهبندی بلوکها در برنامههای خود بررسی کنند. علاوه بر این، یک وبینار عملیاتی برای ۷ جولای ساعت ۱۸:۰۰ به وقت اروپا برنامهریزی شده است تا موارد جدید این انتشار را با دموهای زنده و پرسش و پاسخ پوشش دهد.



گفتگو