
تصور کنید یک مدل هوش مصنوعی بسیار کوچک و ارزان، دقیقاً همان کاری را انجام دهد که پیش از این فقط مدلهای غولپیکر و گرانقیمت قادر به آن بودند. اگر هنوز فکر میکنید برای کارهای پیچیده کدنویسی به مدلهای با میلیاردها پارامتر نیاز دارید، باید بدانید که قواعد بازی در حال تغییر است.
طبق اعلام تیم قرمز هوش مصنوعی انویدیا (NVIDIA AI Red Team) در ۸ مه ۲۰۲۶، استفاده از رمزگشایی با محدودیت گرامری (Grammar-constrained decoding) — تشبیه روزمره: مثل این است که به نویسنده بگوییم فقط از کلمات موجود در یک لیست خاص استفاده کند تا غلط املایی نکند — میتواند مدلهای زبانی کوچک (Small Language Models یا SLM) — تشبیه روزمره: مثل یک دستیار متخصص که فقط یک کتابچه راهنمای کوچک را حفظ کرده اما در آن موضوع استاد است — را به قطعاتی قابلاعتماد در سیستمهای عاملمحور (Agentic) — تشبیه روزمره: مثل کارمندی که فقط جواب نمیدهد، بلکه میتواند خودش ابزارها را بردارد و کار را پیش ببرد — تبدیل کند.
به نقل از مستندات developer.nvidia.com، این تیم روی ۱۳ مدل مختلف آزمایش کردند و متوجه شدند نرخ موفقیت آنها در اجرای دستورات Bash از ۶۲.۵٪ به ۷۵.۲٪ رسیده است. جزئیات فنی این دستاورد به شرح زیر است:
- Qwen3-0.6B خیرهکنندهترین پیشرفت را داشت و نرخ موفقیتش از ۱۶.۷٪ به ۵۹.۲٪ جهش کرد.
- بیشترین بهبود در وظایف سطح ۱ (پایه ورودی/خروجی) و سطح ۲ (فیلتر و تبدیل) دیده شد.
- این سیستم از ابزاری به نام grammargen برای تبدیل مستندات به گرامرهای Lark استفاده میکند.
- فرآیند استنتاج (Inference) — تشبیه روزمره: لحظهای که مدل واقعاً جواب تولید میکند — مثل خودِ آشپزی، نه دورهی آموزش آشپز — از طریق llguidance در llama.cpp مدیریت میشود.
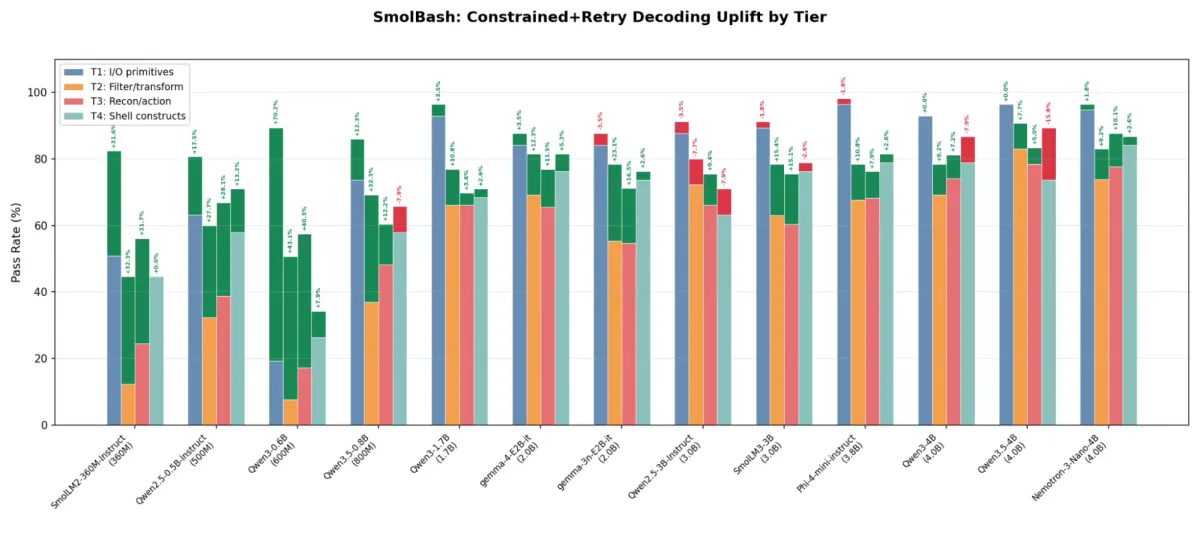
همانطور که در تحلیلهای قبلی ما دربارهی بهینهسازی مدلهای لبه (Edge AI) اشاره کردیم، هدف نهایی کاهش وابستگی به ابرهای پردازشی عظیم است. این پژوهش ثابت میکند که برای استفاده از ابزارهای تخصصی، «دقت مرز خروجی» بسیار حیاتیتر از «اندازه مدل» است. در واقع، با کدگذاری قوانین سینتکس مستقیماً در فرآیند رمزگشایی، میتوان عملکرد مدلهای کوچک را به سطح مدلهایی برسانیم که دو برابر آنها حجم دارند.
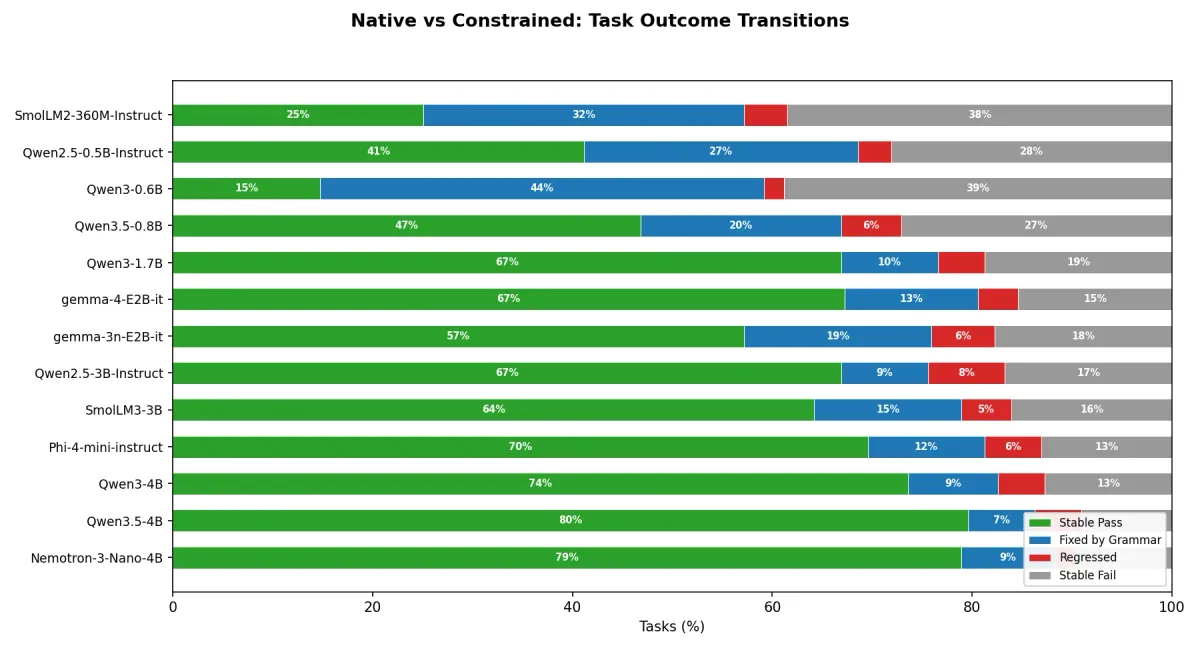
با این حال، این روش معجزه نمیکند؛ به گزارش انویدیا، ساختارهای پیچیده مانند حلقهها (Loops) همچنان برای این مدلها دشوار است. برای ارتقای امنیت، پیشنهاد میشود مدلهایی مثل NVIDIA Nemotron 3 Nano را با لایههای حفاظتی NVIDIA NeMo Guardrails ترکیب کنید.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.
گام بعدی شما
- اگر از مدلهای کوچک برای اتوماسیون استفاده میکنید، کتابخانه llguidance را برای محدود کردن خروجیها بررسی کنید.
- برای کاهش خطاهای سینتکسی در Bash، از ابزارهای تبدیل JSON به گرامرهای Lark استفاده کنید.
- مدلهای زیر ۱ میلیارد پارامتر را با محدودیتهای گرامری تست کنید تا هزینههای GPU خود را کاهش دهید.



گفتگو