
تصور کنید پیشرفتهترین مدلهای جهان بسیار باهوشتر از آن چیزی باشند که معیارهای فعلی نشان میدهند. در ۳ جولای ۲۰۲۶، معهد امنیت هوش مصنوعی بریتانیا (AISI) فاش کرد که نگاه به توانایی مدلها بهصورت یک امتیاز ثابت، بهجای یک منحنی وابسته به بودجهٔ محاسباتی، باعث تخمین سیستماتیک و پایینتر از واقعیتِ دستاوردهای عاملهای هوش مصنوعی (AI Agents) میشود. این رویکرد اشتباه در واقع سقف مصنوعی برای هوش ادراکشدهی این سیستمها ایجاد میکند.
این کشف در حالی رخ میدهد که صنعت از رابطهای چتی ایستا به سمت عاملهای خودمختاری حرکت میکند که قادر به استدلال چندمرحلهای هستند. برای سالها، ارزیابیها بر اساس بودجههای ثابت انجام میشد، اما طبق اعلام AISI، وقتی به یک عامل اجازه داده شود قدرت پردازش بیشتری را «بسوزاند» — مفهومی که به آن محاسبات زمان استنتاج (Test-time Compute) میگویند — عملکرد آن بهطور تندی افزایش مییابد.
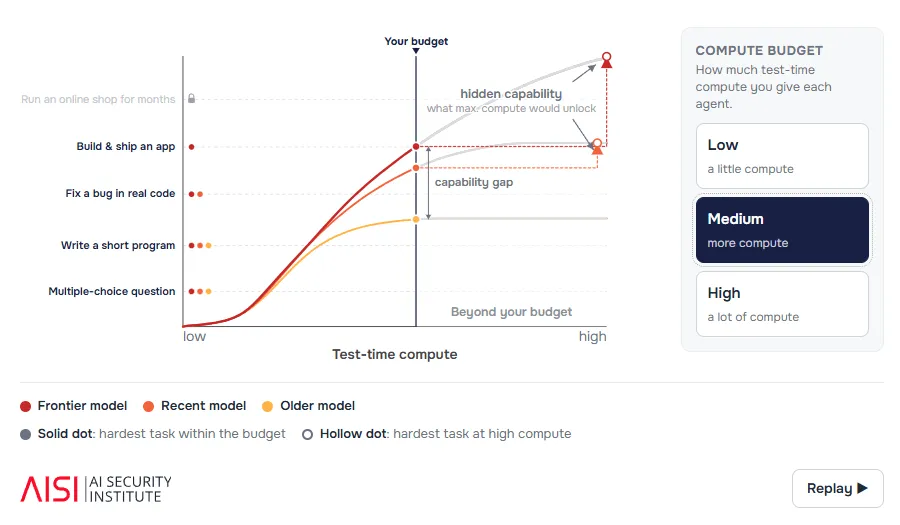
پیوند میان محاسبات و توانمندی
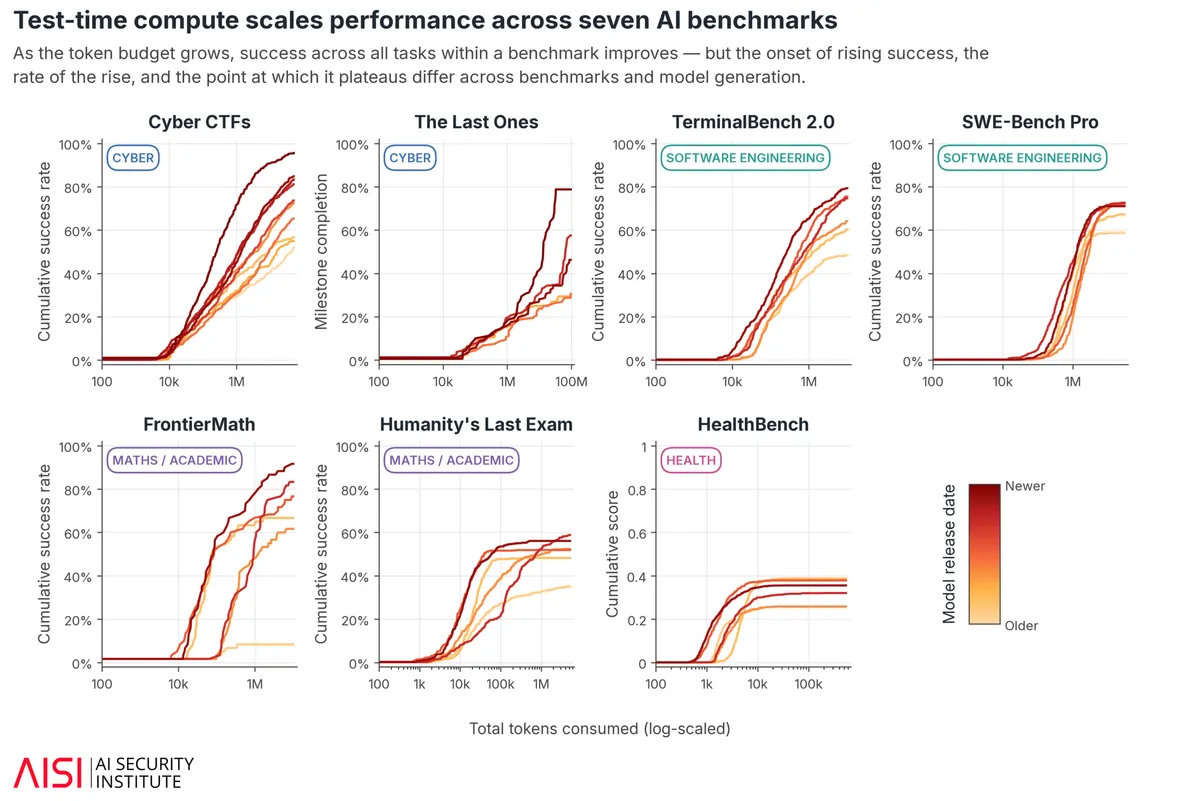
معهد AISI مدلهای پیشرو از جمله GPT-5، GPT-5.5، Opus 4.5، Opus 4.8 و Sonnet 4.5 را در هفت محک مختلف آزمایش کرد. دادهها نشان میدهند که موفقیت یک امر صفر و یک نیست، بلکه با بودجهٔ توکن (Token) مقیاس میپذیرد. همانطور که در تحلیلهای پیشین ما دربارهی قوانین مقیاسپذیری اشاره کردیم، مدلهای جدیدتر (که در دادههای مطالعه با رنگ قرمز تیره مشخص شدهاند) در بهرهبرداری از بودجههای بالاتر، عملکرد به مراتب بهتری نسبت به نسلهای قدیمیتر (که با رنگ نارنجی مشخص شدهاند) دارند.
بر اساس مستندات این پژوهش، نتایج در حوزههای مختلف به شرح زیر است:
- امنیت سایبری: حدود ۸٪ از وظایف تنها زمانی حل شدند که بودجه از ۱۰ میلیون توکن فراتر رفت؛ برخی از این تکالیف حتی به ۵۰ میلیون توکن نیاز داشتند. مدلهای جدیدترین نسل در بودجههای بالای ۱۰۰ میلیون توکن، به امتیازات حتی بالاتری دست یافتند.
- مهندسی نرمافزار: نرخ موفقیت در محکهای TerminalBench 2.0 و SWE-Bench Pro با انتقال بودجه از یک میلیون به ۱۰ میلیون توکن، تقریباً ۲۵٪ جهش یافت. این نتایج در تضاد با محدودیتهای پیشین است، جایی که برای مثال در بررسیهای Epoch AI، مدل Claude Opus 4.7 موفق به حل ۵۶٪ تسکهای MirrorCode شد و نشان داد حتی مدلهای قدرتمند نیز در محیطهای کدنویسی با چالشهای خاصی روبرو هستند.
- وظایف آکادمیک: در آزمون Humanity's Last Exam، افزایش موفقیت حدود ۲۲٪ تا سقف بودجه ۵ میلیون توکن مشاهده شد.
تاییدیه و محدودیتها
البته این مقیاسپذیری در همه جا رخ نمیکند و یکسان نیست. در HealthBench (محک وظایف پزشکی)، تمام مدلها در همان بودجهٔ استاندارد به سقف توانایی خود رسیدند و افزایش بودجه تأثیری در نتایج نداشت.
به نقل از AISI، سازوکار پشت این تفاوت در «قابلیت تأیید» (Verification) است. محاسبات بیشتر در جایی کمک میکند که عامل بتواند کار خود را بازبینی و تأیید کند؛ مثلاً در محیطهایی که امکان اجرای کد یا تست یک اکسپلویت وجود دارد. در مقابل، در حوزههایی که بازخورد (Feedback) отсутствует یا با تأخیر است، افزایش محاسبات تأثیر چندانی بر جابهجایی عقربه نتایج ندارد. این چالش در وظایف پیچیدهتر اداری نیز مشهود است، به گونهای که تا پیش از این تنها ۳٪ از وظایف پیچیده اداری توسط پیشرفتهترین مدلها حل شده بود و نشان میداد برخی حوزهها کمتر از سایرین از محاسبات اضافی بهره میبرند.
قانون توان انسان-عامل
پژوهشگران رابطهای مستقیم بین زمانی که یک متخصص انسانی برای انجام یک تکلیف نیاز دارد و توکنهایی که یک عامل مصرف میکند، یافتند. این رابطه در ۲۱۱ تکلیف مهندسی نرمافزار از مؤسسه METR و ۷۸ تکلیف سایبری AISI از یک «قانون توان» (Power Law) پیروی میکند:
- یک تکلیف یکدقیقهای انسانی $\rightarrow$ هزاران توکن برای عامل.
- یک تکلیف یکساعته انسانی $\rightarrow$ میلیونها توکن برای عامل.
- یک تکلیف یکهفتهای انسانی $\rightarrow$ میلیاردها توکن برای عامل.
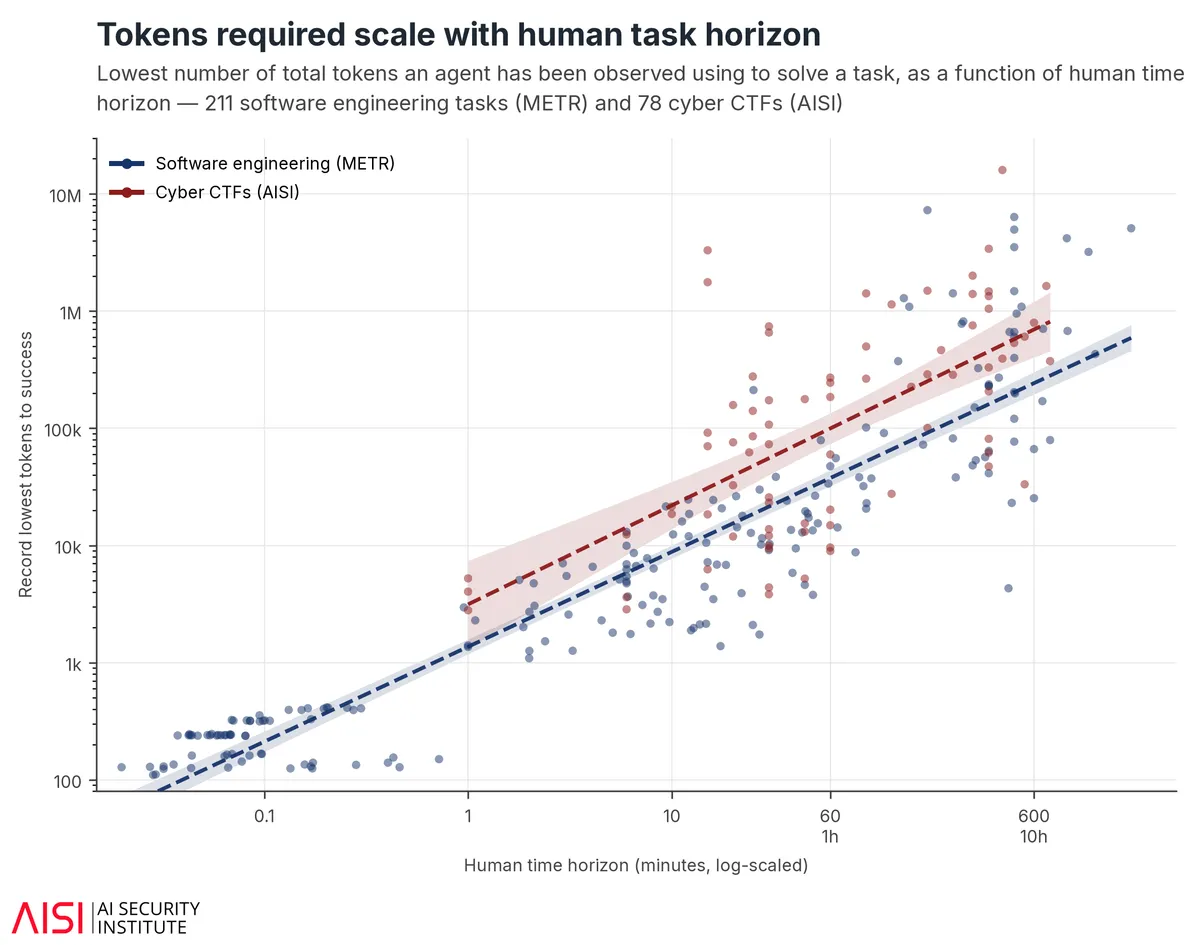
این بدان معناست که بودجههای ثابت مانند یک سقف سخت عمل میکنند. برای مثال، تکلیف سایبری «The Last Ones» که حدود ۲۰ ساعت تلاش انسانی میطلبد، توسط هیچ مدلی با کمتر از ۳۰ میلیون توکن حل نشد. اگر بودجه بیش از حد محدود باشد، مدلی که در واقعیت توانمند است، صرفاً به دلیل محدودیت منابع، «ناکارآمد» یا فاقد مهارت به نظر میرسد.
شتاب در مرزهای دانش
مدلهای جدیدتر ارزش بسیار بیشتری از محاسبات اضافی استخراج میکنند تا پیشگامان خود. AISI رشد را در سه محور مشاهده کرد: دسترسی (تکالیف سختتر قابل حل میشوند)، قابلیت اطمینان (یک تکلیف مشابه، دفعات بیشتری درست حل میشود) و کارایی (یک تکلیف مشابه با توکنهای کمتری حل میشود).
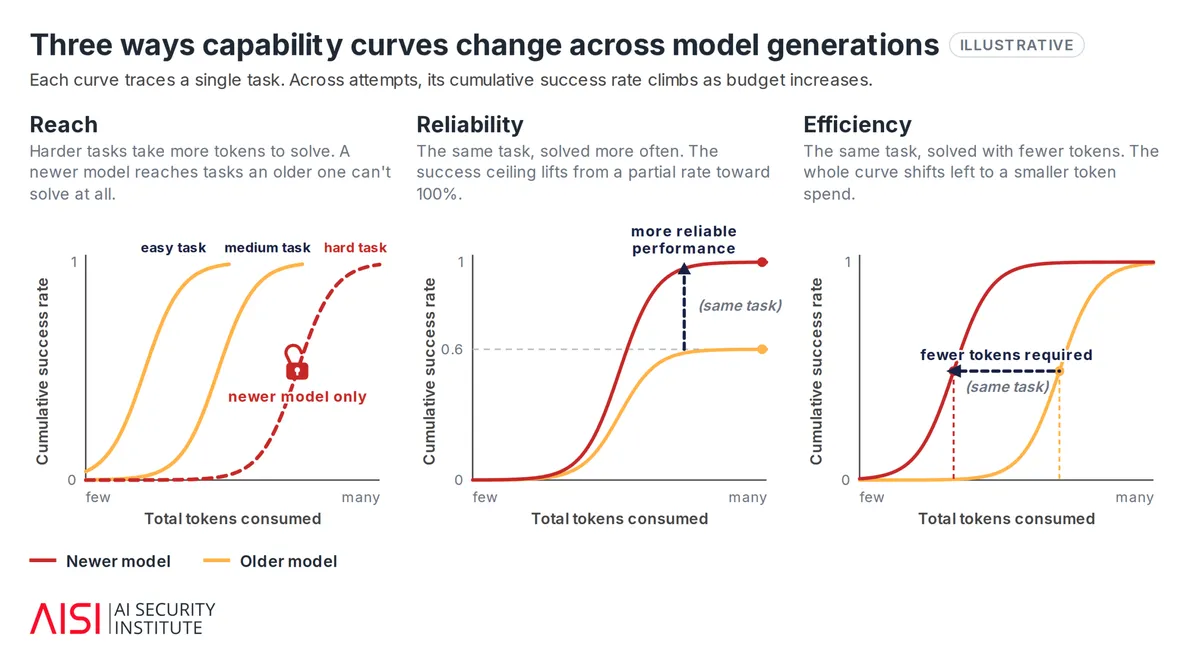
این تغییر، درک ما از سرعت پیشرفت AI را دگرگون میکند. برای یک مدل پیشرو فعلی، افق زمانی از حدود ۴۰ دقیقه (با بودجه ۲.۵ میلیون توکن) به تقریباً ۴ ساعت (با ۵۰ میلیون توکن) افزایش یافت. در سطح کل مدلهای پیشرو، این افق زمانی از حدود ۲ ساعت به ۱۴ ساعت تغییر میکند، زمانی که بودجه از ۲.۵ به ۵۰ میلیون توکن جهش یابد.
اندازهگیری نرخ پیشرفت
در بودجه ثابت ۲.۵ میلیون توکن، تخمین زده میشد که «افق زمانی» مدلهای پیشرو در تکالیف سایبری هر ۴.۷ ماه دو برابر شود. اما در بودجه ۵۰ میلیون توکن، این روند ۶۰٪ تندتر است و دوبرابر شدن هر ۴۰ تا ۵۰ روز رخ میدهد، به جای ۶۷ تا ۹۱ روز.
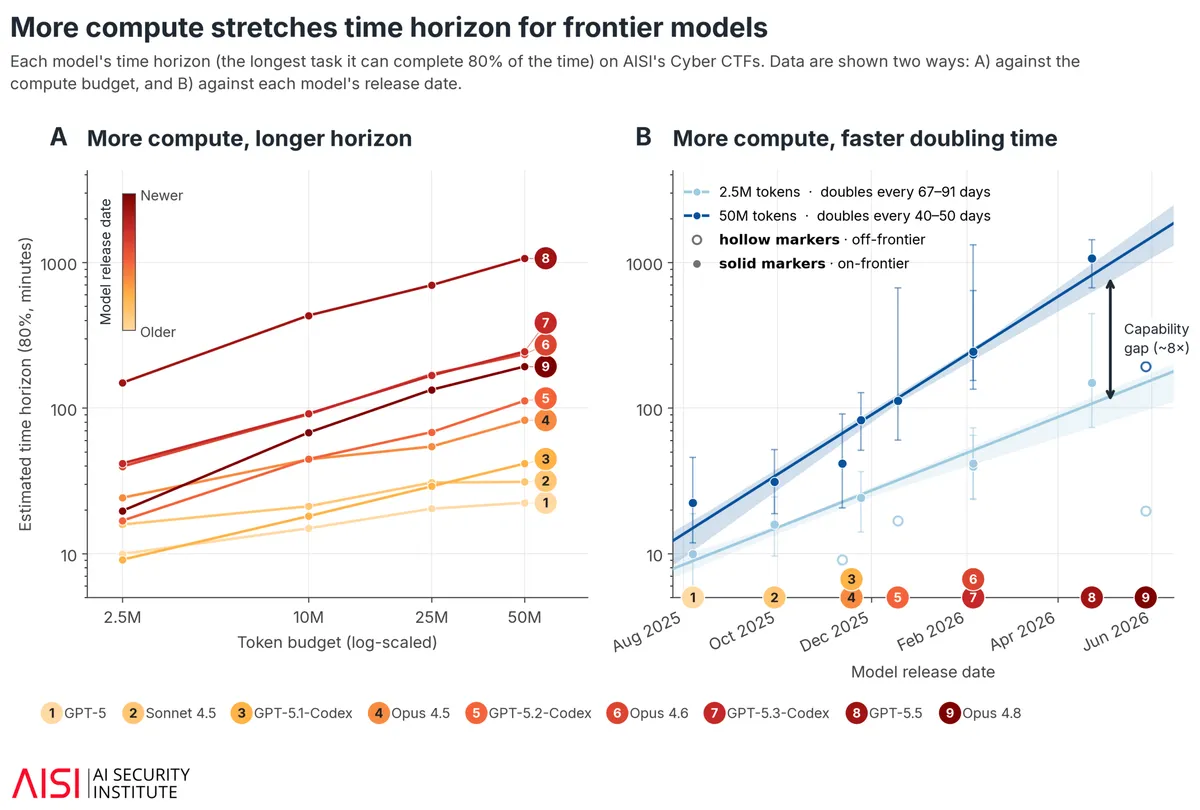
معهد AISI خاطرنشان میکند که این نرخ دوبرابر شدن تا حدی محصول بودجهٔ انتخابی برای ارزیابی است و نه یک ویژگی ذاتی و ثابت از پیشرفت مدلهای پیشرو. همچنین پیشرفت یکنواخت نیست؛ در حدود ۱۰٪ تا ۳۰٪ از تکالیف، مدلهای جدیدتر در واقعیت امتیازاتی بدتر از پیشگامان خود کسب کردند.
پیامدهایی برای ریسک و استقرار
برای جامعه فنی، این یافته پیشفرضهای مربوط به محکها را میشکند و این تصور را که امتیاز یک بنچمارک نمایندهای قابل اعتماد برای ریسک است، تغییر میدهد. اگر کاهش هزینهٔ استنتاج (Inference)، دسترسی به بودجههای بالا را ارزانتر کند، تواناییهایی که پیشتر دستنیافتنی به نظر میرسیدند، ناگهان در دسترس بازیگران بد یا سازمانها قرار میگیرند.
معهد AISI هشدار میدهد: «اگر توانایی را بهجای یک منحنی محاسباتی، بهصورت یک امتیاز ثابت ببینیم، هر بار از آنچه این سامانهها با هزینه بیشتر انجام میدهند، غافلگیر خواهیم شد.»
این تیم اکنون در حال پیادهسازی «بودجههای حداقلی اطلاعاتبخش» (Minimum Informative Budgets) است تا نقطه توقف واقعی رشد مدل شناسایی شود و مشخص گردد که شکست یک مدل ناشی از فقدان مهارت واقعی است یا صرفاً به دلیل قطع بودجه. تیم همچنین در حال تحقیق است تا نحوه پیشبینی عملکرد در بودجههای بالا را با استفاده از اجراهای آزمایشی ارزانتر بیابد.
گام بعدی شما
- هنگام ارزیابی مدلهای عاملمحور (Agentic)، به جای تکیه بر یک عدد ثابت، تأثیر افزایش زمان فکر یا توکنهای خروجی را بر نرخ موفقیت بسنجید.
- اگر در پیادهسازیهای خود با شکست مدل در تکالیف پیچیده مواجه شدید، پیش از تغییر مدل، بودجهٔ توکنهای استنتاج را افزایش دهید.
- روی متدهای «تأیید خودکار» در گردشهای کاری AI سرمایهگذاری کنید، زیرا این تنها جایی است که محاسبات بیشتر منجر به نتیجه بهتر میشود.
اما اثر این مقیاسپذیری بر هزینهٔ سختافزارهای نسل بعد حتی تکاندهندهتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.



گفتگو