
تصور کنید مدلی با یکچهارم حجم حافظه، بتواند هوشمندتر از رقیب غولپیکر خود باشد. اگر هنوز باور دارید که برای رسیدن به دقت بالاتر فقط باید تعداد پارامترها را افزایش دهید، IBM شما را به اشتباه انداخته است.
در ۲۹ آوریل ۲۰۲۶، شرکت IBM از خانواده مدلهای Granite 4.1 پردهبرداری کرد؛ مجموعهای از مدلهای وزنهای باز (Open Weights) با معماری decoder-only در ابعاد ۳، ۸ و ۳۰ میلیارد پارامتر. به نقل از مستندات فنی منتشر شده در Hugging Face، این مدلها بر روی ۱۵ تریلیون توکن و طی یک خط لوله پنجمرحلهای بسیار سختگیرانه آموزش دیدهاند.

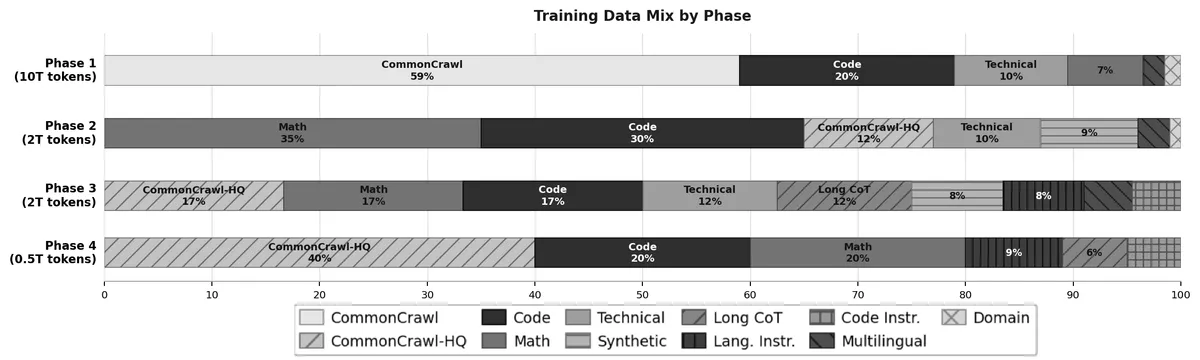
استراتژی آموزشی این مدلها بهگونهای طراحی شده که بهتدریج از دادههای گسترده وب به سمت دادههای باکیفیت «تبخاری» (Annealing) و گسترش بافتار (Context) حرکت کند. طبق اعلام IBM، در مرحله نهایی، پنجره بافتار برای مدلهای ۸ و ۳۰ میلیارد پارامتری به ۵۱۲ هزار توکن افزایش یافت. برای تضمین قابلیت اطمینان، این شرکت از یک چارچوب «مدل بهعنوان داور» (LLM-as-Judge) برای گلچین کردن ۴.۱ میلیون نمونه باکیفیت جهت تنظیم دقیق (Fine-tuning) نظارتشده استفاده کرد.
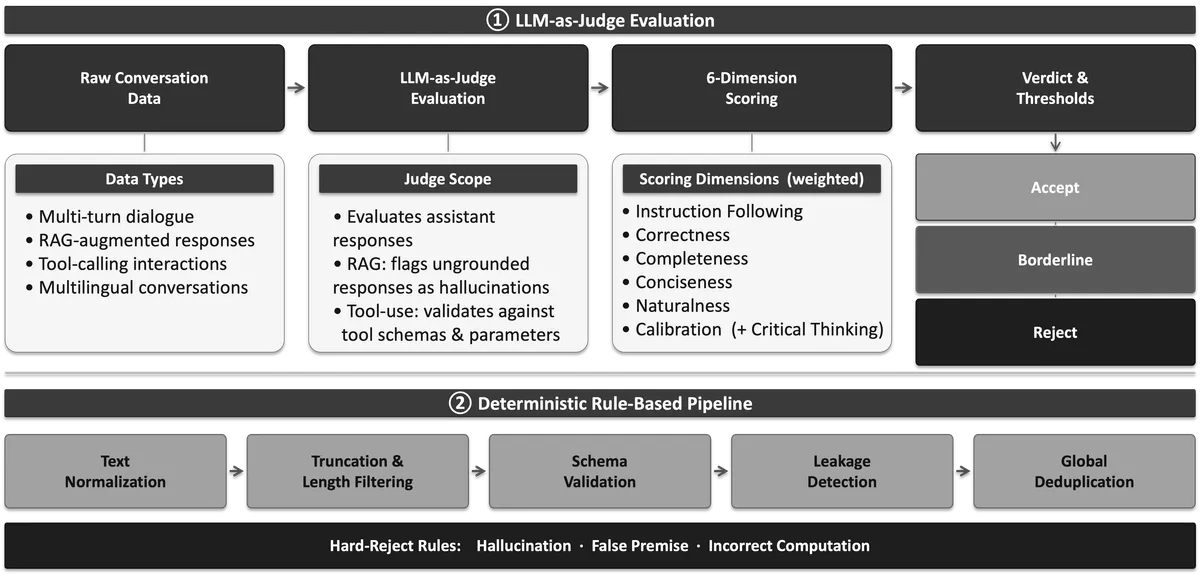
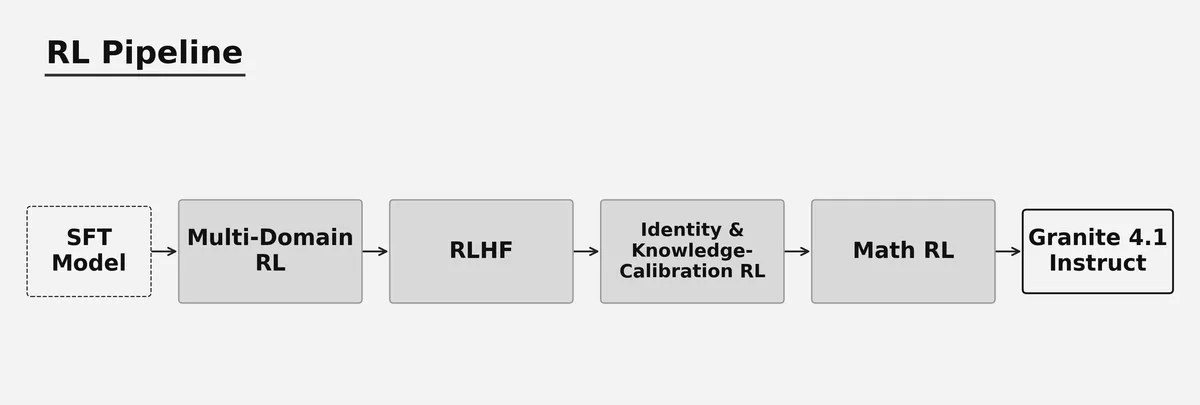
فرآیند پس از آموزش شامل یک خط لوله یادگیری تقویتشده چندمرحلهای با استفاده از بهینهسازی سیاست نسبی گروهی (GRPO) و تابع زیان DAPO بود. این توالی — که حوزههای مختلف RL، همراستاسازی با بازخورد انسانی (RLHF)، کالیبراسیون هویت و یک مرحله بازیابی تخصصی ریاضی را شامل میشد — باعث شد تا مدلها بدون دچار شدن به «فراموشی فاجعهبار»، تواناییهای استدلالی خود را به حداکثر برسانند.
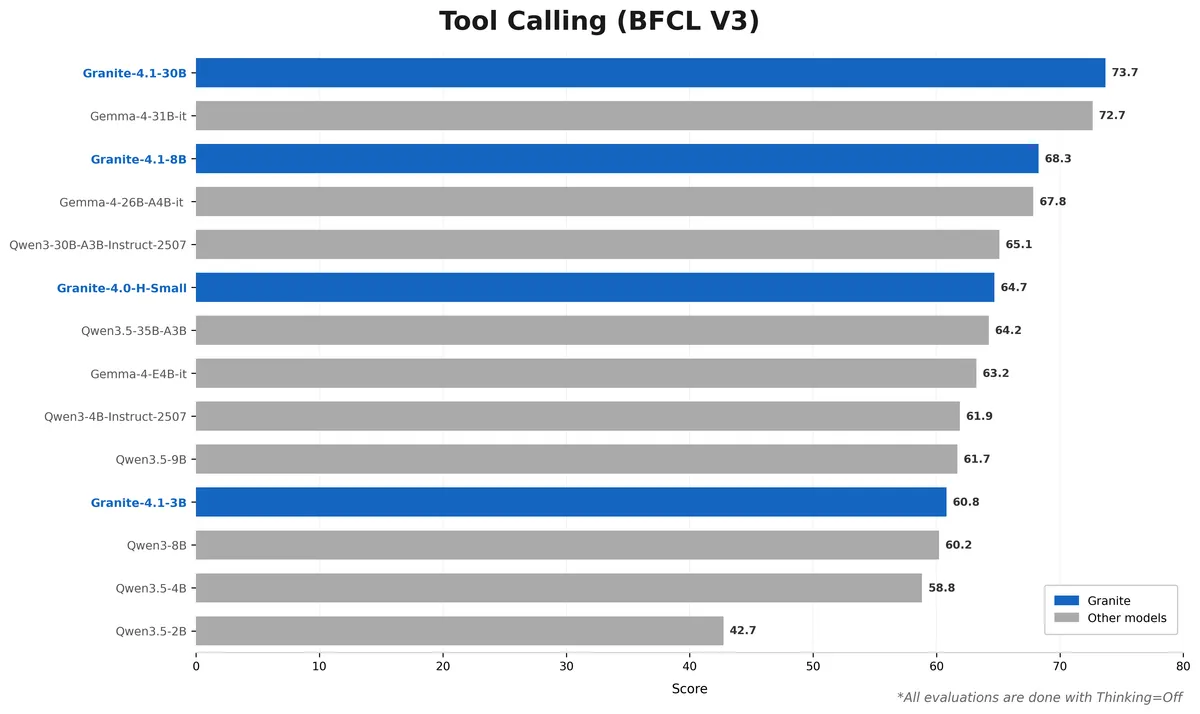
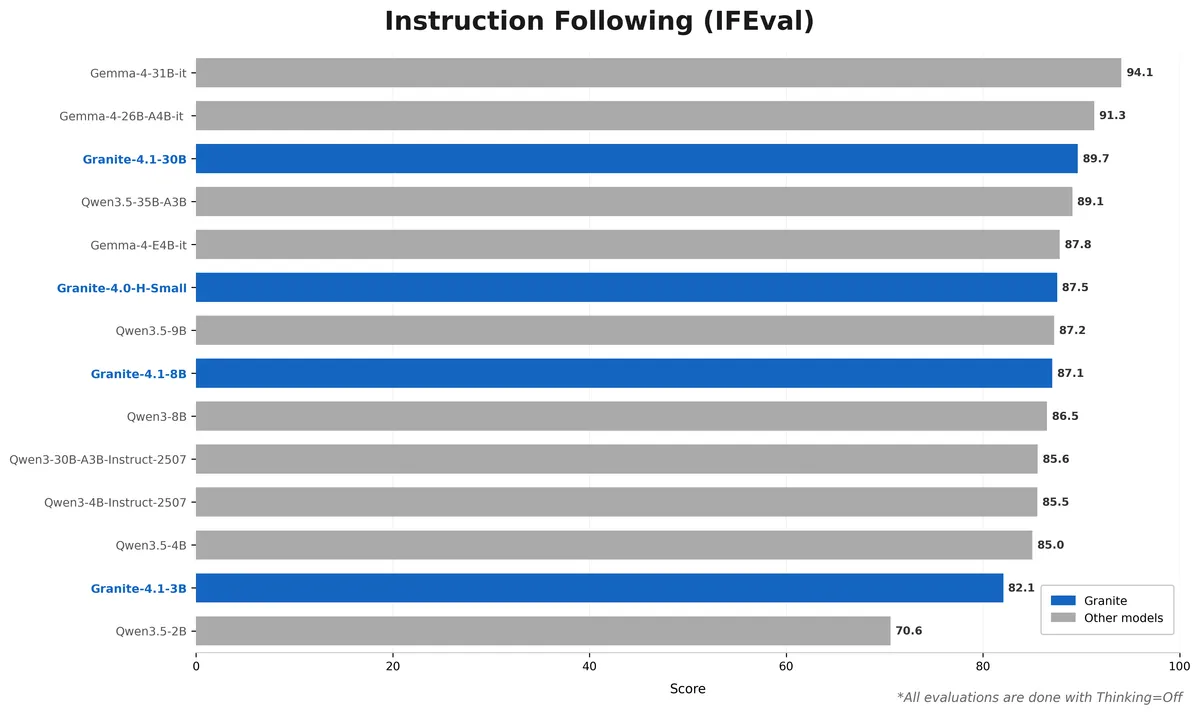
نتایج بهدستآمده، قوانین مقیاسپذیری (Scaling Laws) متداول را به چالش میکشد. مدل متراکم Granite 4.1-8B در بنچمارکهای کلیدی مانند IFEval، GSM8K و MMLU-Pro، بهطور مداوم با مدل Granite 4.0-H-Small (که یک مدل ۳۲ میلیارد پارامتری MoE است) برابری کرده یا حتی از آن پیشی گرفته است.
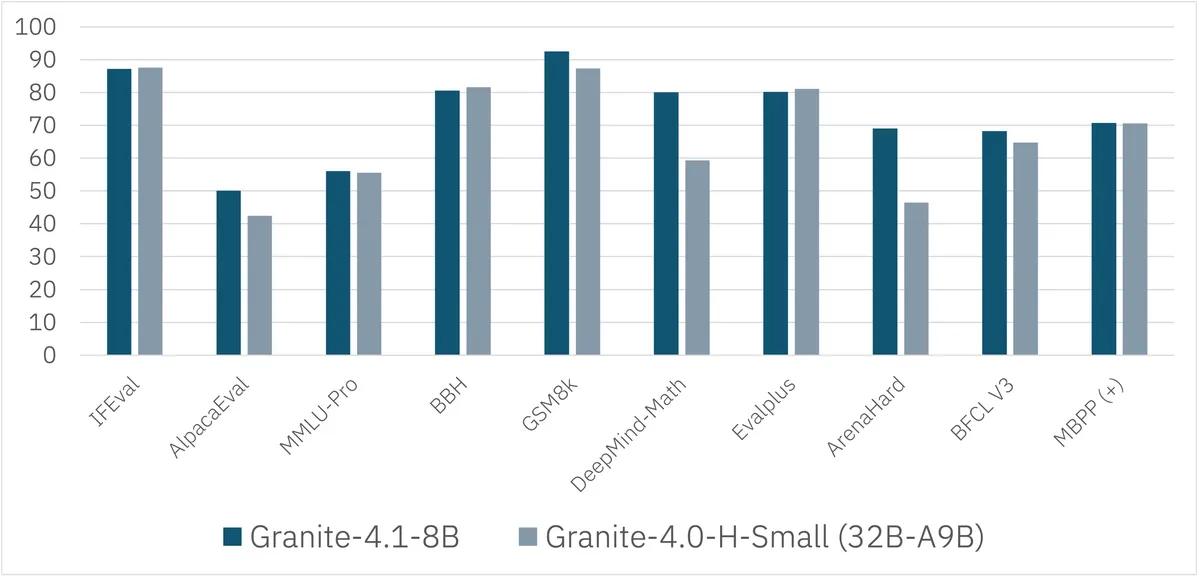
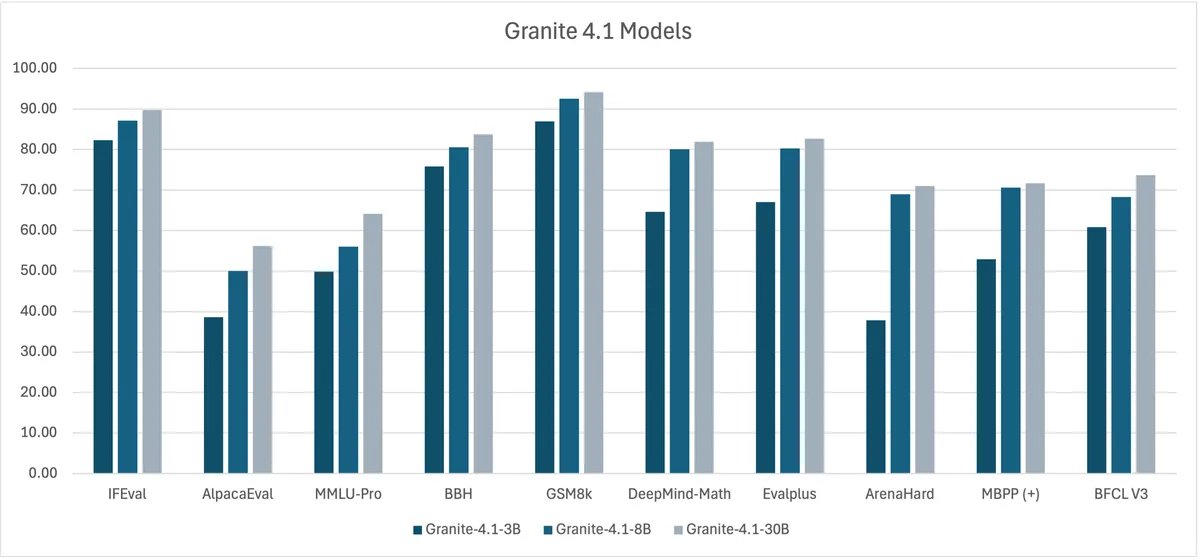
همانطور که در بحثهای گذشتهی ما دربارهی بهینهسازی مدلهای زبانی کوچک اشاره کردیم، مسیر تکامل هوش مصنوعی زاینده (Generative AI) از کمیت به سمت کیفیت حرکت میکند. Granite 4.1 با حذف ردپاهای استدلالی طولانی، تأخیر پیشبینیپذیری و هزینههای عملیاتی کمتری را برای بارهای کاری سازمانی فراهم میکند و در واقع از بروز خطاها در همان مرحله آموزش جلوگیری میکند.
اما این تنها آغاز ماجراست؛ اثر موجگونهی این رویکرد بر معماریهای سختافزاری آینده را در گزارش بعدی بررسی خواهیم کرد.
گام بعدی شما
- مدلهای Granite 4.1 را برای وظایفی با بافتار طولانی (تا ۵۱۲ هزار توکن) آزمایش کنید.
- استراتژی «مدل بهعنوان داور» را برای پالایش دادههای آموزشی خود پیادهسازی کنید.
- بررسی کنید که آیا مدلهای متراکم کوچکتر میتوانند جایگزین سیستمهای MoE در زیرساخت شما شوند.



گفتگو