
اگر امروز یک بات پشتیبانی مشتری دارید که پاسخهای غلط میدهد، احتمالاً مشکل از هوش مدل نیست، بلکه مدل شما دارد از یک «برگه تقلب» اشتباه جواب میدهد. باید بدانید که در بسیاری از موارد، مدل زبانی شما بهدرستی استدلال میکند، اما دادههای ورودی به آن چنان ناقص یا نادرست است که نتیجهای غلط تولید میشود. این یافته که در یک تحلیل فنی عمیق در ۵ جولای ۲۰۲۶ در وبسایت dev.to منتشر شد، نشان میدهد که مدل زبانی بزرگ (LLM) شما در واقع باهوشتر نمیشود؛ بلکه صرفاً برگه مرجع بهتری برای پاسخگویی دریافت میکند. این رویکرد در واقع تلاشی است برای تبدیل حافظه ایستا به جستوجوی زنده تا توهمات مدلها متوقف شود، موضوعی که در تحلیل جامع ما درباره مکانیسمهای RAG برای توقف توهمات بهطور مفصل بررسی شده است.
برای مهندسان بکاند، این تغییر رویکرد به معنای فاصله گرفتن از دستکاریهای جزئی در پرامپتها و حرکت به سمت «مشاهدهپذیری خط لوله داده» (Data Pipeline Observability) است. اگر یک بات پشتیبانی، قانونی قدیمی را نقل میکند، مدل لزوماً دچار توهم (Hallucination) — یا همان حالتی که مدل با اطمینان چیزی میگوید که وجود ندارد، شبیه به دوستی که خاطرهای را اشتباه تعریف میکند — نشده است؛ بلکه به احتمال زیاد تکهای منسوخ از یک پایگاهداده برداری (Vector Database) را بازیابی کرده است که بهروزرسانیهای اخیر را دریافت نکرده بود. این یعنی باید با «دانش» هوش مصنوعی به عنوان یک مسئلهی کوئری توزیعشده برخورد کرد، نه یک مسئلهی زبانشناختی. وظیفه شما این است که با RAG مانند هر خط لوله داده دیگری برخورد کنید: قابل اندازهگیری، قابل مشاهده و در هر مرحله قابل آزمایش.
معماری بازیابی
سیستم RAG برای عبور از محدودیتهای پیشبینی احتمالی توکنها، ذخیرهسازی دانش را از تولید زبان جدا میکند. طبق راهنمای dev.to، این فرآیند از یک خط لوله سختگیرانه پیروی میکند: اسناد ابتدا پارس میشوند، تکهبندی (Chunking) میشوند و در حالت آفلاین به یک ایندکس برداری تبدیل (Embedding) میشوند؛ سپس در حالت آنلاین، بازیابی شده و پیش از رسیدن به LLM، بازرتبهبندی (Re-rank) میشوند.
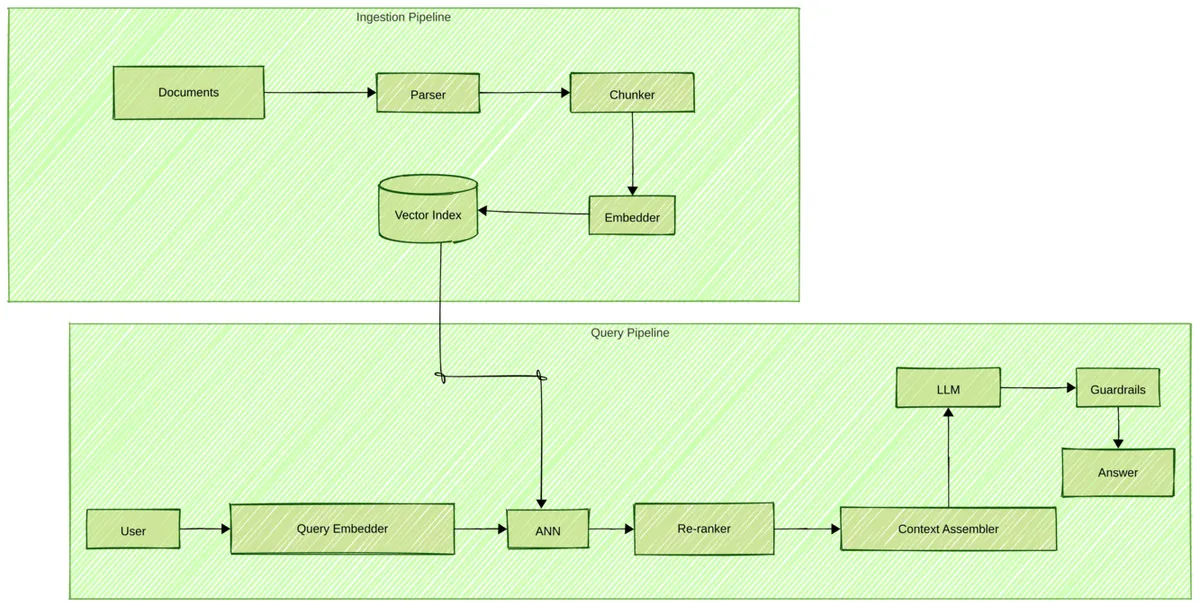
الگوهای سادهی RAG (Naive RAG) — که صرفاً تکههای بازیابی شدهی برتر (Top-K) را در پرامپت میریزند — اغلب به صورت خاموش شکست میخورند. این اتفاق زمانی میافتد که تکهها بیش از حد بزرگ باشند و پاسخها زیر تپهای از نویز دفن شوند، یا آنقدر کوچک باشند که جداول حیاتی را در مرزهای تکهبندی نصف کنند. مدلهای Embedding نیز ممکن است قصد معنایی را بهطور کامل درک نکنند، بهویژه زمانی که با اصطلاحات تخصصی در زمینههای پزشکی یا حقوقی مواجه میشوند. این چالشها نشان میدهند که چرا صرفاً افزایش اندازه مدلها نمیتواند خطاهای تخصصی را حل کند، همانطور که در بررسی دلایل عدم موفقیت مقیاسپذیری در درمان توهمات حقوقی اشاره کردیم. سایر موارد شکست شامل ایندکسهای منسوخ پس از بهروزرسانی مستندات یا سرریز شدن بافت (Context Overflow) است که باعث میشود تکهای که حاوی پاسخ واقعی است، بریده (Truncate) شود.
تجزیه و تحلیل اجزای RAG
برای عیبیابی این خطاها، باید نقش هر جزء را بهدقت شناخت:
- جذب داده (Ingestion): پارس کردن، تکهبندی و تبدیل اسناد به بردار. حالتهای شکست در اینجا شامل تکههای بد (Bad Chunks) و از دست رفتن ساختار سند است.
- ایندکس (Index): ذخیره بردارها برای جستوجوی شباهت. شکستها شامل بردارهای منسوخ یا استفاده از معیار شباهت (Similarity Metric) غلط است.
- بازیابی (Retrieval): یافتن گذرگاههای کاندید. شکستها به صورت نرخ فراخوانی (Recall) پایین یا بازیابی همسایگان اشتباه ظاهر میشوند.
- بازرتبهبندی (Re-ranking): مرتبسازی کاندیدها بر اساس میزان ارتباط. شکستها شامل نادیده گرفتن این مرحله یا جهشهای ناگهانی در تأخیر (Latency) است.
- تولید (Generation): ترکیب پاسخ نهایی. شکستها شامل نادیده گرفتن بافت ارائه شده یا توهم فراتر از متن بازیابی شده است.
استراتژیهای تکهبندی و بردارسازی
مهندسان باید استراتژی تکهبندی را بر اساس ساختار داده انتخاب کنند. تکههای با اندازه ثابت (مثلاً ۵۱۲ توکن) ساده هستند اما ریسک بالایی دارند زیرا ممکن است جملات و جداول را در نقاط نامناسب قطع کنند. تکهبندی معنایی (Semantic Chunking) که بر اساس مرزهای پاراگراف یا بخشها انجام میشود، انسجام بهتری ایجاد میکند. روش پیشرفتهتر، «تکهبندی والد-فرزند» (Parent-child chunking) است که در آن تکههای کوچک برای دقت (Precision) بازیابی میشوند، اما بافت بزرگتر والد برای مدل تولیدکننده تزریق میشود تا معنای کامل حفظ شود. برای کسانی که به دنبال راهکارهای پیشرفتهتر هستند، رویکرد تکهبندی عاملمحور روشی نوین برای اصلاح بافتهایe شکسته در سیستمهای RAG ارائه میدهد.
همپوشانی (Overlap) — که معمولاً ۱۰ تا ۲۰ درصد اندازه تکه است — برای کاهش آثار مرزی (Boundary Artifacts) در جایی که یک پاسخ در دو تکه پخش شده است، حیاتی است. علاوه بر این، انتخاب مدل Embedding اغلب بیشتر از مدل تولیدکننده اهمیت دارد. عدم تطابق بین مدل و دامنه (مانند حقوق، پزشکی یا کدنویسی) بهشدت به Recall آسیب میزند، زیرا مدل نمیتواند متن را به بردارهایی تبدیل کند که در آنها «شباهت کسینوسی» بهدرستی بازتابدهندهی ارتباط معنایی باشد.
بهبود Recall از طریق جستوجوی ترکیبی
جستوجوی برداری متراکم (Dense Vector Search) به تنهایی اغلب در مواجهه با شناسههای دقیق مانند SKUها، کدهای خطا یا نام توابع دچار مشکل میشود. برای رفع این مشکل، توسعهدهندگان باید «جستوجوی ترکیبی» (Hybrid Search) را پیاده کنند که جستوجوی کلیدواژهای BM25 را با بازیابی متراکم ترکیب میکند. این کار تضمین میکند که اصطلاحات فنی خاص حتی در صورت پایین بودن شباهت برداری، شناسایی شوند.
بازرتبهبندی (Re-ranking) یکی از مراحل ضروری است که اغلب نادیده گرفته میشود. یک جستوجوی تقریبی نزدیکترین همسایه (ANN) ممکن است گذرگاههایی را برگرداند که از نظر معنایی نزدیک اما برای تکلیف مورد نظر نامرتبط هستند. یک Cross-encoder یا بازرتبهبند سبک میتواند این کاندیدها را مجدداً مرتب کند تا مرتبطترین بافت در ابتدای پرامپت قرار گیرد.
مکانیسمهای داخلی و اجرا
فرآیند RAG در دو فاز متمایز عمل میکند:
فاز آفلاین: اسناد پارس، تکهبندی و تبدیل به بردار میشوند. سپس در یک ایندکس برداری ذخیره شده و اغلب با فیلترهای متادیت (Metadata Filters) همراه میشوند.
فاز آنلاین: پرسش کاربر با استفاده از همان مدل زمان جذب، به بردار تبدیل میشود. یک جستوجوی ANN نتایج برتر (Top-K) را برمیگرداند. اگر بازرتبهبندی وجود داشته باشد، جفتهای پرسش-گذرگاه را امتیازدهی میکند. در نهایت، پرامپت با دستورات سیستمی، گذرگاههای بازیابی شده و سوال کاربر ترکیب میشود. LLM سپس پاسخی را تولید میکند که توسط این بافت محدود شده است.
به عنوان مثال، اگر کاربر بپرسد: «مهلت استرداد وجه برای طرحهای سالانه چقدر است؟»، سیستم کوئری را بردار میکند، ۵ تکه برتر را از طریق شباهت کسینوسی مییابد، آنها را برای اولویت دادن به صورت صورتحساب سالانه بازرتبهبندی میکند و از این قانون پرامپت استفاده میکند: «فقط از بافت پاسخ بده. اگر پاسخ ناشناخته است، این را ذکر کن». استفاده از دمای پایین (۰.۱ تا ۰.۳) پایداری پاسخ را تضمین میکند. اگر بازیابی فقط تکههای مربوط به طرحهای ماهانه را برگرداند، مدل با اطمینان اما غلط پاسخ خواهد داد؛ این دقیقاً دلیلی است که چرا باید ابتدا بازیابی را دیباگ کنید.
مثال پیادهسازی
برای یک حلقه RAG حداقلی در پایتون، میتوانید از sentence-transformers و numpy استفاده کنید. یک پیادهسازی پایه شامل کدگذاری اسناد (مثلاً «طرحهای سالانه: استرداد وجه تا ۱۴ روز») و استفاده از ضرب داخلی (Dot Product) بردارهای نرمال شده برای محاسبه امتیازات است. در حالی که این روش برای دموها کاربرد دارد، سیستمهای عملیاتی (Production) به پایگاهدادههای برداری تخصصی برای مدیریت مقیاس، فیلترهای متادیت و خطوط لوله تکهبندی پیچیده نیاز دارند.
چکلیست عملیاتی و معیارها
ارسال RAG به محیط عملیاتی نیازمند یک مجموعه ارزیابی سختگیرانه با حداقل ۱۰۰ جفت پرسش-سند برچسبخورده است. شما باید «همپوشانی جذب» (Ingestion Idempotency) را تأیید کنید (مطمئن شوید اجرای مجدد جذب روی یک سند، همان شناسهها را تولید میکند) و نسخهی مدل Embedding را روی هر بردار ذخیره نمایید.
معیارهای کلیدی برای رهگیری عبارتند از:
- Recall@K: آیا سند مرتبط در بین K نتیجه اول است؟ (هدف: بالاتر)
- MRR (Mean Reciprocal Rank): رتبه اولین سند مرتبط کجاست؟ (هدف: بالاتر)
- nDCG: اندازهگیری رتبهبندی ارتباط درجهبندی شده. (هدف: بالاتر)
- Faithfulness: آیا پاسخ صرفاً بر متن بازیابی شده تکیه دارد؟ (هدف: بالاتر)
- Answer Correctness: دقت سرتاسری در مقایسه با یک مجموعه طلایی (Gold Set). (هدف: بالاتر)
- Latency: آیا p95 بازیابی زیر SLA است؟ (معمولاً کمتر از ۲۰۰ میلیثانیه بدون احتساب LLM). (هدف: پایینتر)
مدیریت تازگی دادهها
منسوخ شدن ایندکس یکی از اصلیترین حالتهای شکست است. پیچیدگی و سرعت بهروزرسانیها بسته به الگو متفاوت است:
- دستهای شبانه (Nightly Batch): پیچیدگی کم، اما دادهها میتوانند تا چندین ساعت قدیمی باشند.
- رویداد-محور (Event-driven): پیچیدگی متوسط، بهروزرسانی با تغییر سند تحریک میشود و تازگی را به سطح چند دقیقه میرساند.
- نوشتار-مستقیم (Write-through): پیچیدگی بالا، بهروزرسانیهای تقریباً لحظهای هنگام انتشار.
برای اسناد قیمتگذاری یا سیاستهای شرکت، هزینه مهندسی یک سیستم رویداد-محور معمولاً به دلیل نیاز به دقت بالا توجیه میشود.
موازنههای طراحی: اندازه تکه
انتخاب پنجره مناسب یک بازی تعادل است:
- ۱۲۸-۲۵۶ توکن: بازیابی دقیق را ارائه میدهد اما ممکن است بافت محیطی لازم را نداشته باشد.
- ۵۱۲-۱۰۲۴ توکن: یک مقدار پیشفرض خوب برای متون نثر است، اگرچه جداول ممکن است بهطور نامناسب تقسیم شوند.
- ۲۰۰۰+ توکن: بافت کامل بخش را فراهم میکند اما نویز را افزایش و دقت (Precision) را کاهش میدهد.
مستندات حقوقی و API اغلب به تکهبندیهای «ساختار-آگاه» (Structure-aware) بر اساس سرتیترها یا عملیات OpenAPI نیاز دارند، نه پنجرههای ثابت توکن.
محدودیتهای RAG
با وجود کاربرد زیاد، RAG با دادههای تراکنشی لحظهای (Real-time)، استدلالهای پیچیده چندمرحلهای (Multi-hop) بین اسناد متعدد و محاسبات دقیق ریاضی (جایی که مدلها اغلب توهم میزنند) دست و پنجه نرم میکند. در این موارد، راهنما پیشنهاد میکند بهجای جستوجوی برداری از ابزارها یا SQL استفاده کنید. ترکیب RAG با ابزارهای پروتکل زمینه مدل (MCP) به سیستم اجازه میدهد بهجای اتکا به یک ایندکس ایستا، به وضعیت زنده دسترسی داشته باشد.
عیبیابی «پاسخ اشتباه»
وقتی کاربر پاسخی نادرست دریافت میکند، اولین گام بررسی لاگهای بازیابی است، نه پرامپت. اگر کاربر بپرسد «آیا طرحهای سالانه شامل پشتیبانی تلفنی میشوند؟» و مدل نقل کند «پشتیبانی ایمیلی اولویتدار»، لاگهای بازیابی را چک کنید. اگر تکه با بالاترین امتیاز مربوط به طرحهای ماهانه باشد در حالی که طرح سالانه در تکهای با رتبه پایینتر قرار دارد، احتمالاً مدل Embedding این دو اصطلاح را اشتباه گرفته است.
برای رفع این مشکل، از دستکاری پرامپت خودداری کنید. در عوض:
۱. یک فیلتر متادیت (مثلاً plan_type=annual) اضافه کنید وقتی طبقهبندیکننده کوئری، قصد پرداخت را تشخیص میدهد.
۲. یک بازرتبهبند (Reranker) اضافه کنید.
۳. مجموعه کوئریهای ارزیابی را گسترش دهید.
مشاهدهپذیری و الگوهای ضد-پال
برای اینکه RAG قابل دیباگ باشد، این فیلدها را برای هر درخواست لاگ کنید: query_text_hash، embedding_model_version، retrieved_chunk_ids (همراه با امتیازات)، rerank_scores، prompt_token_count و answer_faithfulness_score.
از این الگوهای ضد-پال (Anti-patterns) رایج دوری کنید:
- تخلیه ویکی (Wiki Dump): ارسال ۵۰ صفحه تصادفی بهجای بازیابی هدفمند.
- عدم ارجاع: عدم اجازه به کاربران برای تأیید پاسخها که باعث سلب اعتماد میشود.
- تک ایندکس برای همه: استفاده از یک مدل Embedding واحد برای هر دو مورد کد و نثر.
- نادیده گرفتن ACLها: بازگرداندن اسنادی که کاربر اجازه دسترسی به آنها را ندارد. لیستهای کنترل دسترسی (ACL) باید در زمان بازیابی اعمال شوند و همگامسازی ACL باید هنگام حذف سند رخ دهد.
خلاصه: RAG یک خط لوله جستوجو است که یک LLM در انتهای آن قرار دارد. با تکهبندی، بردارسازی، ایندکسگذاری و بازیابی به عنوان مسائل مهندسی درجهیک برخورد کنید. کیفیت بازیابی را پیش از تنظیم تولید اندازهگیری کنید. سیستم RAG شما تنها به اندازه لایه جستوجوی زیرین آن خوب است.
گام بعدی شما
- لاگهای بازیابی (Retrieval Logs) خود را بررسی کنید تا ببینید آیا مدل واقعاً توهم میزند یا دادههای غلط دریافت میکند.
- اگر از جستوجوی برداری ساده استفاده میکنید، یک لایه بازرتبهبندی (Reranker) یا جستوجوی ترکیبی (Hybrid Search) اضافه کنید.
- برای هر یک از سناریوهای کلیدی، مجموعهای از دادههای مرجع (Gold Set) ایجاد کنید تا نرخ Recall را اندازه بگیرید.
اما داستان سختافزاری این تحول و مدیریت حافظه در مقیاس کلان حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.



گفتگو