
مدیران تبلیغات معمولاً ساعتها وقت خود را صرف گشتزدن دستی در داشبوردها میکنند تا فقط به یک پرسش پاسخ دهند: چرا این کمپین شکست خورد؟ Campaign Failure Intelligence (CFI) — پروژهای که برای هکاتون H0 با استفاده از Vercel v0 و ادغام پایگاههای داده AWS توسعه یافته است — این فرآیند تشخیص را بهجای بررسی موارد پراکنده، به یک سیستم مدیریت دانش تبدیل میکند. هدف این سیستم این است که شکستهای کمپینها را به جای حوادثی مجزا، به عنوان دانشهای قابل استفاده و تکرار در آینده مدیریت کند.
بسیاری از آژانسهای تبلیغاتی از یک «شکاف زمینهای» رنج میبرند؛ وضعیتی که در آن راهکار کاهش افت عملکرد، فقط در ذهن یک مدیر یا در رشتهپیامهای فراموششدهی Slack است. پاسخ صادقانه این است که تشخیص علت ریشهای یک مشکل معمولاً چندین ساعت یا حتی یک تا دو روز زمان میبرد تا معیارهای عملکردی با گزارشهای تاریخی مقایسه شده و بررسی شوند. این بررسی دستی، یک گلوگاه جدی در مقیاسپذیری است؛ بهطوری که آژانسها با رشد بیشتر، مدام همان مشکلات تکراری را حل میکنند چون حافظه سازمانی آنها در صفحات گسترده (Spreadsheets)، مستندات پراکنده و ابزارهای مختلف پخش شده است.
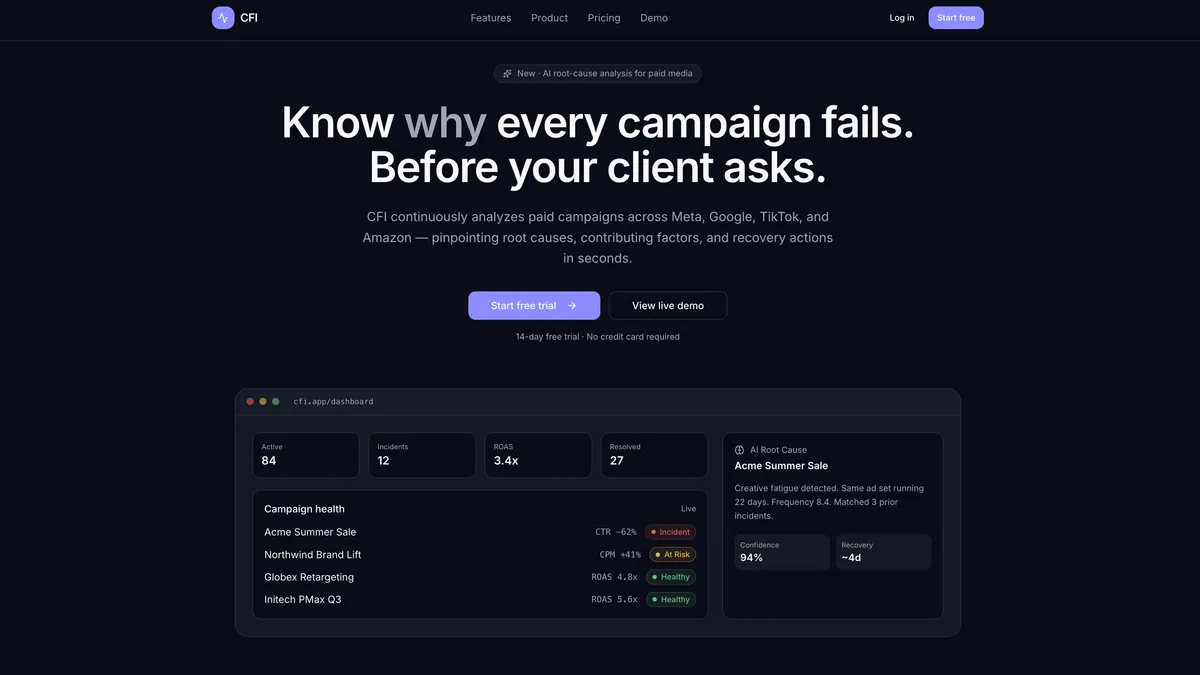
CFI این شکاف را با تحلیل سیگنالهای عملکردی دنیای واقعی میپوشاند. طبق مستندات پروژه، این سیستم معیارهایی مانند ROAS (بازگشت سرمایه تبلیغاتی)، CTR (نرخ کلیک)، CPM (هزینه هر هزار نمایش)، CPC (هزینه هر کلیک)، فرکانس (Frequency)، دسترسی (Reach)، میزان هزینه (Spend) و زمینههای فصلی را رصد میکند تا بر اساس قوانین تجاری قابل تنظیم، نقاط ضعف و افت عملکرد را شناسایی کند.
بستر عملیاتی
سیستم CFI به عنوان یک ابزار B2B طراحی شده است که سه وظیفه اصلی را بر عهده دارد:
- تشخیص (Detection): شناسایی کمپینهایی که شروع به افت عملکرد کردهاند، از طریق تعریف آستانههایی (Thresholds) مانند افزایش CPM یا جهش ناگهانی در فرکانس نمایش.
- عیبیابی (Diagnosis): تحلیل الگوهای رفتاری و اعتبارسنجی آنها در برابر موقعیتهای مشابه تاریخی برای یافتن علت ریشهای (Root Cause).
- توصیه (Recommendation): پیشنهاد راهکارهای اصلاحی که در موقعیتهای مشابه گذشته موفق بودهاند. این توصیهها بر اساس اثربخشی تاریخی رتبهبندی میشوند، نه اینکه صرفاً دستورالعملهای کلی و عمومی (Best Practices) را ارائه دهند.
موتور فنی
توسعهدهندگان برای ساخت موتور تشخیص، از یک مجموعهداده عمومی Kaggle شامل تقریباً ۱۸۰۰ مشاهده روزانه از Google Ads، Meta Ads و TikTok Ads استفاده کردند. این کار تضمین میکند که هوش مصنوعی بهجای دادههای مصنوعی، از رفتار واقعی کمپینها در صنایع مختلف یاد بگیرد. این مجموعه داده نهایی شامل ۵ مشتری، ۶۰ کمپین و حدود ۶۰ موقعیت (Situation) شناساییشده است.
یک پایپلاین داده با Python و pandas گزارشهای خام را به یک پایگاه دانش ساختاریافته تبدیل میکند. این مسیر دادهها را به یک طرحواره رابطهای (Relational Schema) به صورت زیر نقشهبرداری میکند: مشتریان ← کمپینها ← معیارهای روزانه ← موقعیتها ← بردارهای معنایی موقعیت ← قوانین ریسک ← فصلهای کمپین.
مکانیزمهای کلیدی در این پایپلاین عبارتند از:
- منطق ماشه (Trigger Logic): هر روزی از کمپین که در آن ROAS به زیر ۲.۰ برسد، به عنوان یک «موقعیت» علامتگذاری میشود.
- سطوح شدت (Severity Tiers): مشکلات بر اساس میزان انحراف عملکرد از هدف تعیین شده، در دستههای «بحرانی» (Critical)، «بالا» (High) یا «متوسط» (Medium) قرار میگیرند.
- تحلیل علت ریشهای (RCA): سیستم الگوهای متری را به نتایج پیوند میدهد. برای مثال، ترکیب فرکانس بالای طولانیمدت و افت CTR به عنوان «خستگی خلاق» (Creative Fatigue) طبقهبندی میشود، در حالی که کاهش دسترسی (Reach) همزمان با افزایش فرکانس، نشاندهنده «اشباع مخاطب» (Audience Saturation) است.
- گروهبندی فصلی (Seasonal Grouping): کمپینها در دستههای فصلی مانند «بازگشت به مدرسه»، «حراج تابستانی»، «جمعه سیاه»، «سه ماهه اول/سال نو» و «پرتاب بهاری» گروهبندی میشوند. این قابلیت به ابزار اجازه میدهد تا روندهای مشترک بین مشتریان مختلف را که ممکن است مدیران به صورت فردی متوجه نشوند، آشکار کند.
معماری AWS
بخش بکاِند برای اجرای استدلالهای تولید بازیابیافزا (RAG) از یک استک صنعتی AWS بهره میبرد. هر موقعیت شناساییشده با استفاده از Amazon Titan Embeddings v2 از طریق AWS Bedrock به یک بردار معنایی (Embedding) تبدیل شده و در Amazon Aurora PostgreSQL Serverless v2 ذخیره میشود. با استفاده از افزونه pgvector، بردارهای معنایی مستقیماً داخل پایگاه داده رابطهای قرار میگیرند و نیاز به استفاده از یک دیتابیس برداری مجزا حذف میشود.
وقتی یک افت عملکرد جدید رخ میدهد، گردش کار دقیقاً این مراحل را طی میکند:
۱. بردارسازی (Embedding): سیستم زمینه جدید، شامل متریها، پلتفرم، فصل و الگوی ماشه را بردارسازی میکند.
۲. بازیابی (Retrieval): یک جستوجوی شباهت با pgvector روی بردارهای ذخیرهشده اجرا میشود تا ۳ مورد مشابه از تاریخچه، شامل علتها، راهکارهای اصلاحی و بازه زمانی حل مشکل، استخراج شود.
۳. استدلال (Reasoning): زمینه جدید و موارد بازیابیشده به یک عامل هوش مصنوعی قدرتگرفته از Amazon Nova Lite از طریق Bedrock ارسال میشود.
۴. خروجی (Output): عامل هوش مصنوعی، علت ریشهای احتمالی، شواهد پشتیبان و راهکارهای عملیاتی توصیهشده را بر اساس آنچه قبلاً جواب داده است، بازمیگرداند.
رابط کاربری و استک فنی
رابط کاربری که با Vercel v0 ساخته شده است، یک اپلیکیشن Next.js آماده تولید است. این UI بر اساس گردش کار واقعی یک مدیر طراحی شده است: شروع از نمای کلی، ورود به جزئیات متری، تحلیل علت ریشهای و در نهایت اعمال راهکار. این بخش شامل داشبوردهای کمپین، نماهای بررسی موقعیت، خطوط زمانی عیبیابی و پنلهای توصیه است.
استک کامل فنی عبارت است از:
- فرانت-اِند: TanStack Start (برای SSR و مسیریابی مبتنی بر فایل)، React 19 و Vite 8 با استفاده از npm.
- استایلدهی: Tailwind CSS 4، shadcn/ui و Radix UI primitives، به همراه حالت تاریک (Dark Mode) پیشفرض.
- آیکونها و بصریسازی: Lucide React و Recharts.
- بکاِند: Amazon Aurora PostgreSQL Serverless v2 (با pgvector) و AWS Bedrock (شامل Titan Embeddings و Nova Lite).
برای کاربر، این تغییر به معنای گذار از «حدسهای واکنشی» به «بهینهسازی مبتنی بر شواهد» است. آژانسها اکنون میتوانند بهجای تکیه بر دستورالعملهای کلی «بهترین روشها»، دقیقاً همان راهکار خاصی را اجرا کنند که برای مشتری مشابهی در فصل جمعه سیاه یا حراج تابستانی سال پیش جواب داده است.
این معماری ثابت میکند ارزش هوش مصنوعی در بازاریابی فقط در تولید متن تبلیغاتی نیست، بلکه در مدیریت حافظه عملیاتی آژانس است. این سیستم تاریخچهای پراکنده از شکستها را به یک دارایی ساختاریافته و قابل پرسوجو تبدیل میکند.
شما میتوانید با دنبال کردن آخرین بهروزرسانیهای قابلیتهای Agentic در Amazon Bedrock، بررسی کنید که ابزارهای تشخیص مبتنی بر RAG چگونه در سایر عملیاتهای تجاری ادغام میشوند.



گفتگو