
تصور کنید یک عامل هوش مصنوعی با اطمینان کامل بخشی از کد شما را تغییر میدهد، اما در واقع هیچ ارتباطی بین آن دو فایل وجود نداشته است. این شکاف میان شباهت متنی و حقیقت ساختاری، یک شکست بحرانی در عاملهای کدنویسی AI است که بازیابیهای سنتی مبتنی بر جاسازی (Embedding) نمیتوانند آن را حل کنند. این شکستهای ساختاری در کدنویسی، نقطهی کور ابزارهای فعلی است که فقط بر اساس شباهت متنی عمل میکنند. پیش از این، شکافهای بازیابی در پایههای کد بزرگ به عنوان یکی از دلایل اصلی شکست عاملهای کدنویس مورد بررسی قرار گرفته بود.
بسیاری از ابزارهای فعلاً از تولید بازیابیافزا (RAG) — که شبیه دانشآموزی است که قبل از جواب دادن، اول کتاب درسی را باز میکند و از آن نقل میآورد — استفاده میکنند. طبق گزارش توسعهدهندهٔ این پروژه در dev.to، این روش یک سقف ساختاری دارد و صرفاً به عنوان یک خط پایه (Baseline) مفید عمل میکند. برای مثال، شباهت کسینوسی (Cosine Similarity) میتواند بگوید کدام متن «مشابه» است، اما نمیتواند تشخیص دهد کدام ۲۰ فایل از میان ۲۰۰۰ فایل، ستونهای اصلی و «حامل بار» (Load-bearing) سیستم هستند، یا اینکه یک فراخوانی در فرانتاند دقیقاً به کدام هندلر در بکاند میرسد. اینها پرسشهای گراف و تاریخچه هستند، نه پرسشهای جستجو. در واقع انتخاب میان RAG و روشهای جایگزین، بخشی از چالشهای استقرار AI در سال ۲۰۲۶ است که هر کدام محدودیتهای خاص خود را دارند.
برای حل این مشکل، در ۲۷ ژوئن ۲۰۲۶ ابزار forensic-deepdive منتشر شد. این ابزار که تحت لایسنس Apache-2.0 است و به صورت متنباز عرضه شده، یک گراف دانش داخلی و پایدار را در مسیر <repo>/.deepdive/graph.lbug میسازد. سیستم استخراج دادهها در این ابزار به گونهای طراحی شده که در طول فرآیند استخراج، از فراخوانیهای LLM اجتناب میکند. استخراج کاملاً محلی است و برای تجزیهٔ نه زبان مختلف، از tree-sitter و یک نقشه شبیه به PageRank برای تعیین مرکزیت مخزن استفاده میکند. استخراج دادهها به هیچ شبکه یا کلید API نیاز ندارد، هرچند ویژگیهای ابری و معنایی (Semantic) صرفاً به صورت اختیاری (Opt-in) ارائه میشوند.
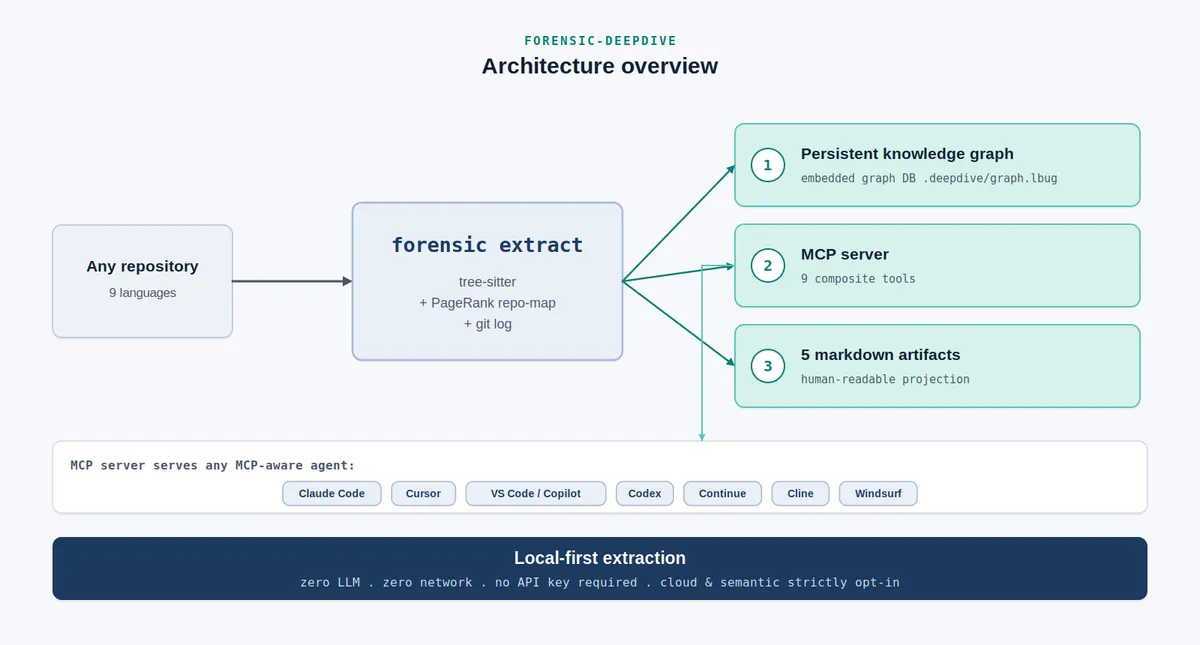
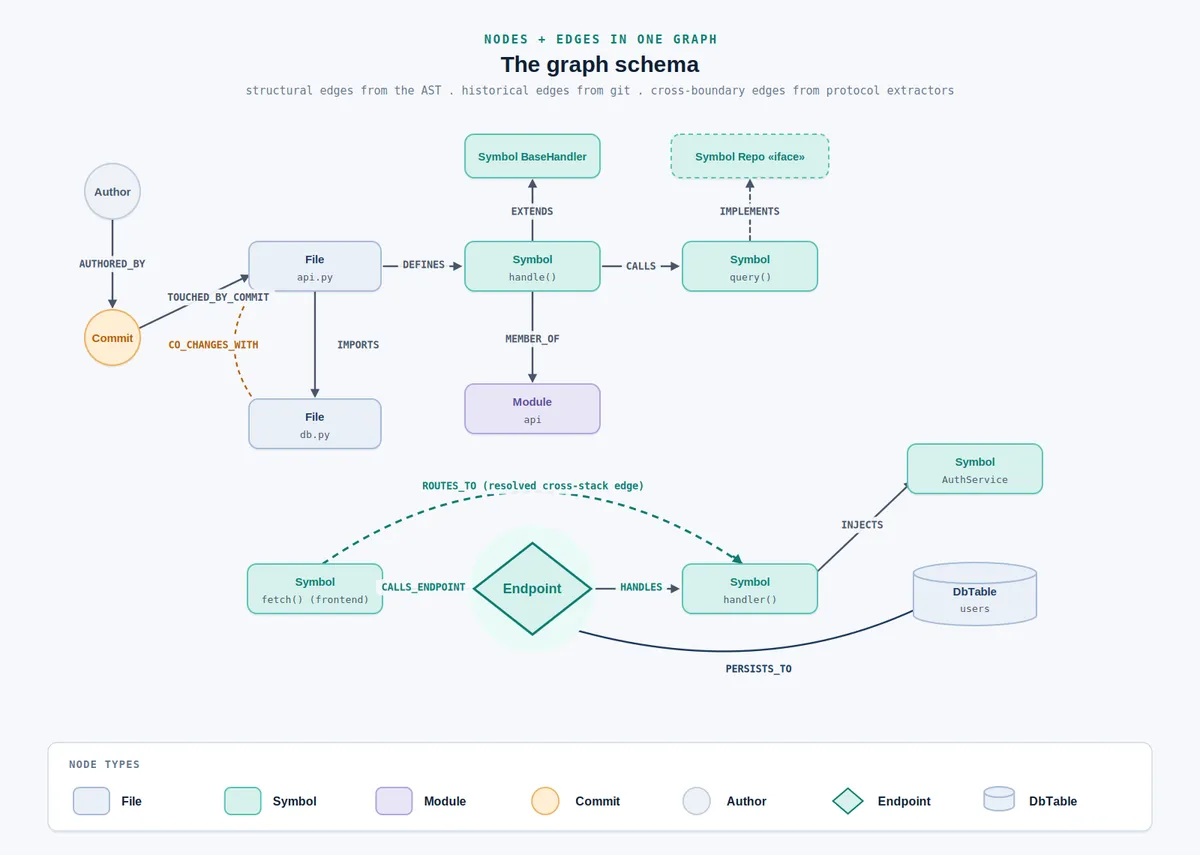
بر اساس مستندات پروژه، این ابزار لایههای ساختاری و تاریخی را ترکیب میکند تا یک دید جامع ایجاد کند. این ابزار از یک اسکیمای گراف پیچیده شامل انواع مختلف گرهها و یالها استفاده میکند:
- انواع گرهها (Node Types): شامل File (فایل)، Symbol (نماد)، Module (ماژول)، Commit (کامیت)، Author (نویسنده)، Endpoint (نقطه انتهایی) و DbTable (جدول پایگاه داده) است.
- یالهای ساختاری (Structural Edges): روابطی مثل DEFINES (تعریف میکند)، MEMBER_OF (عضو است)، IMPORTS (وارد میکند)، CALLS (فراخوانی میکند) و EXTENDS (توسعه میدهد) که مستقیماً از تحلیل AST استخراج میشوند.
- یالهای تاریخی (Historical Edges): روابطی مانند TOUCHED_BY_COMMIT (تغییر یافته توسط کامیت)، AUTHORED_BY (نوشته شده توسط) و CO_CHANGES_WITH (فایلهایی که همیشه با هم تغییر میکنند) که از لاگهای git استخراج میشوند.
- یالهای عبور از مرز (Cross-Boundary Edges): روابطی چون IMPLEMENTS (پیادهسازی میکند)، HANDLES (مدیریت میکند)، CALLS_ENDPOINT (فراخوانی نقطه انتهایی)، ROUTES_TO (مسیریابی به)، INJECTS (تزریق میکند) و PERSISTS_TO (ذخیره میکند).
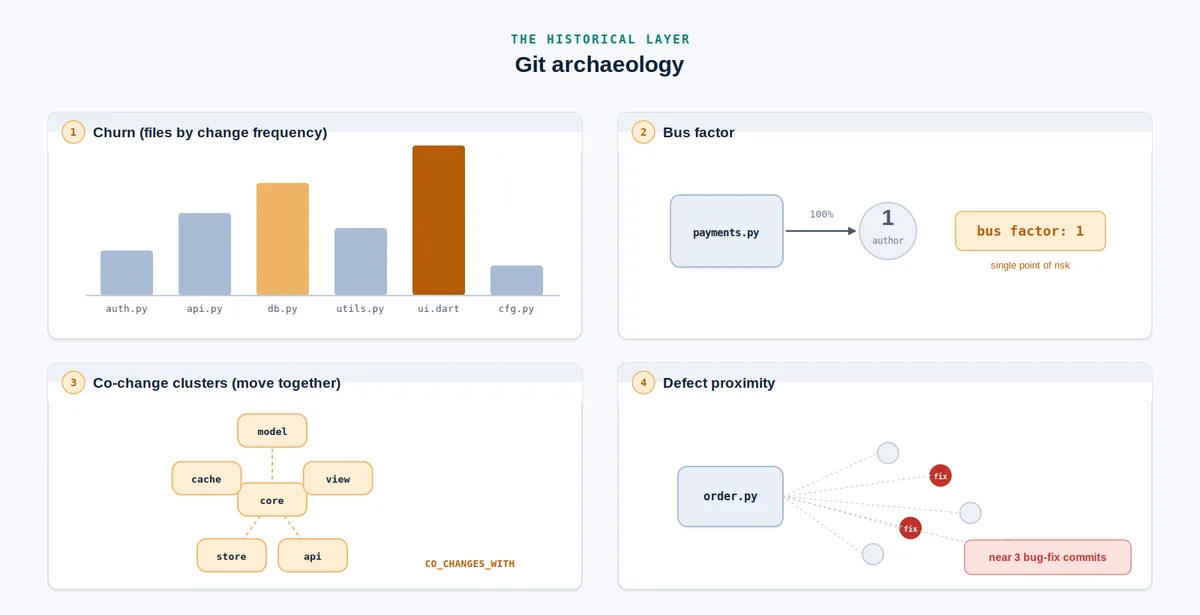
این معماری به عامل اجازه میدهد دادههای ساختاری و تاریخی را به طور همزمان کوئری کند. این قابلیت باعث میشود عامل بتواند «نرخ تغییر» (Churn) را تحلیل کند، نویسندگان اصلی را با درصد مشارکت شناسایی کرده و «عامل اتوبوس» (Bus Factor) را برای ماژولهای خاص محاسبه کند. همچنین این لایه باستانشناختی، نزدیکی عیوب (Defect Proximity) را بررسی کرده و نمادهایی که نزدیک به کامیتهای رفع باگ هستند را شناسایی میکند. این امر کمک میکند تا متوجه شویم ریسک در کجای کد متمرکز است و دقیقاً از چه کسی باید کمک گرفت.
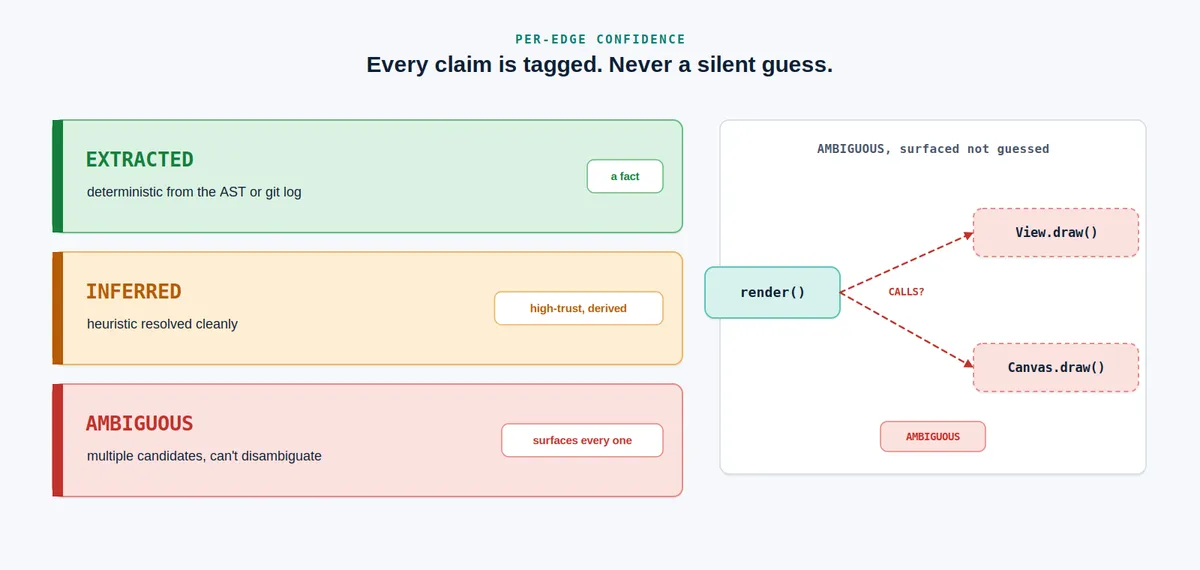
یکی از خطرناکترین حالتهای شکست در عاملهای خودگردان، «اطمینان خاموش» (Silent Confidence) است؛ جایی که ابزار با اطمینان ادعا میکند رابطهای وجود دارد (مثلاً یک یال CALLS)، اما در واقع این رابطه فقط به دلیل وجود دو نماد با نام یکسان در دو فایل مختلف است. اگر یک عامل به یک مثبت کاذب اعتماد کند، ممکن است کدی را «اصلاح» کند که هرگز نیازی به تغییر نداشته است.
برای مقابله با این موضوع، forensic-deepdive برای هر یال و ادعا یک برچسب اطمینان تعیین میکند:
- EXTRACTED: واقعیتهای قطعی استخراج شده از AST یا لاگ git که حقایق مطلق تلقی میشوند.
- INFERRED: استنتاجات با اعتماد بالا، مانند پیمایش گراف واردات (Import-graph walks)، استنتاج نوع گیرنده (Receiver-type inference) یا مواردی که تنها یک کاندید با نام مشابه وجود دارد.
- AMBIGUOUS: مواردی که چندین کاندیدا وجود دارد و تحلیلگر نمیتواند آنها را تفکیک کند. در اینجا ابزار بهجای حدس زدن، تمام کاندیدها را نمایش میدهد.
این سیستم تضمین میکند که اگر عاملی با برخورد نامهای مشابه روبرو شود، آن را به عنوان یک ادعای «مبهم» بشناسد، نه یک حقیقت. قابلیت HOTPATHS دقیقاً شامل یک ستون «ترکیب اطمینان» است تا نمادهایی که بهراحتی حل شدهاند را از نمادهایی که در تداخلات نام غرق شدهاند، تفکیک کند.
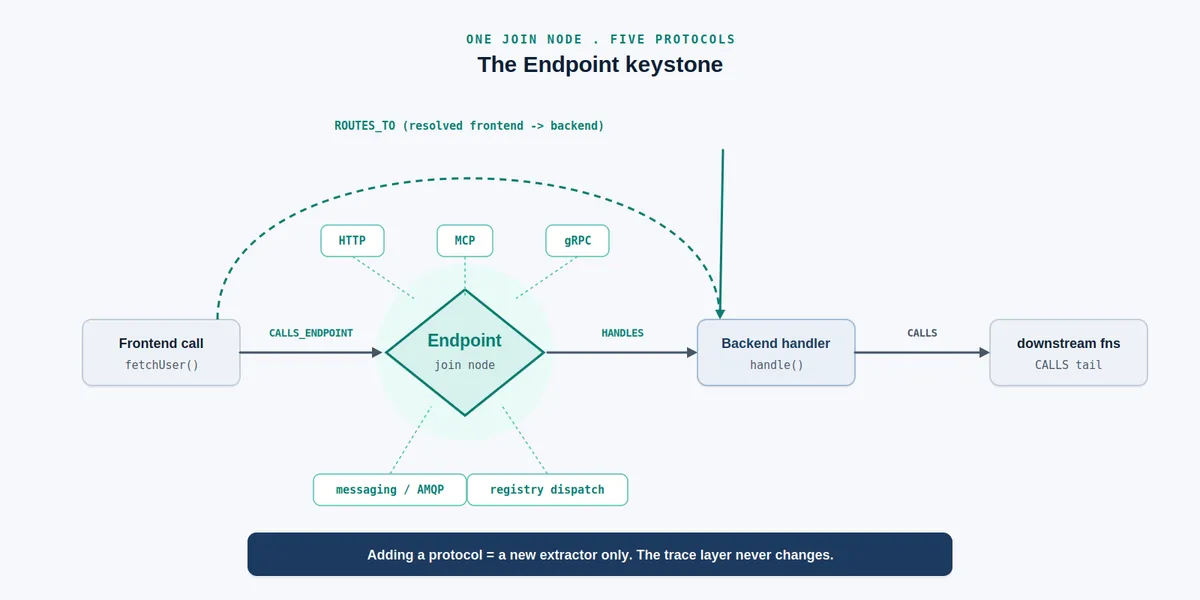
در زمینه ردیابی فراخوانیها بین پروتکلهای مختلف، اکثر ابزارها شکست میخورند چون امضای هر پروتکل متفاوت است. forensic-deepdive تمام پروتکلها را از طریق یک گره واسط به نام «Endpoint» هدایت میکند.
این معماری پنج پروتکل مجزا را انتزاع میکند:
- HTTP
- ابزارهای MCP
- Registry dispatch
- gRPC
- Messaging/AMQP
به دلیل این ساختار که لایه نمایش را «نابینا نسبت به پروتکل» (Protocol-blind) میکند، یک دستور trace(symbol) میتواند از یک فراخوانی فرانتاند، از طریق یال CALLS_ENDPOINT، به هندلر بکاند و در نهایت به فراخوانیهای انتهایی (Tail calls) برسد، بدون اینکه اهمیت دهد پروتکل زیرساختی چیست. افزودن پروتکل ششم تنها نیازمند یک key-builder جدید و استخراجکنندههای تامینکننده/مصرفکننده است و هرگز به لایههای trace، emit یا serve دست نمیزند.
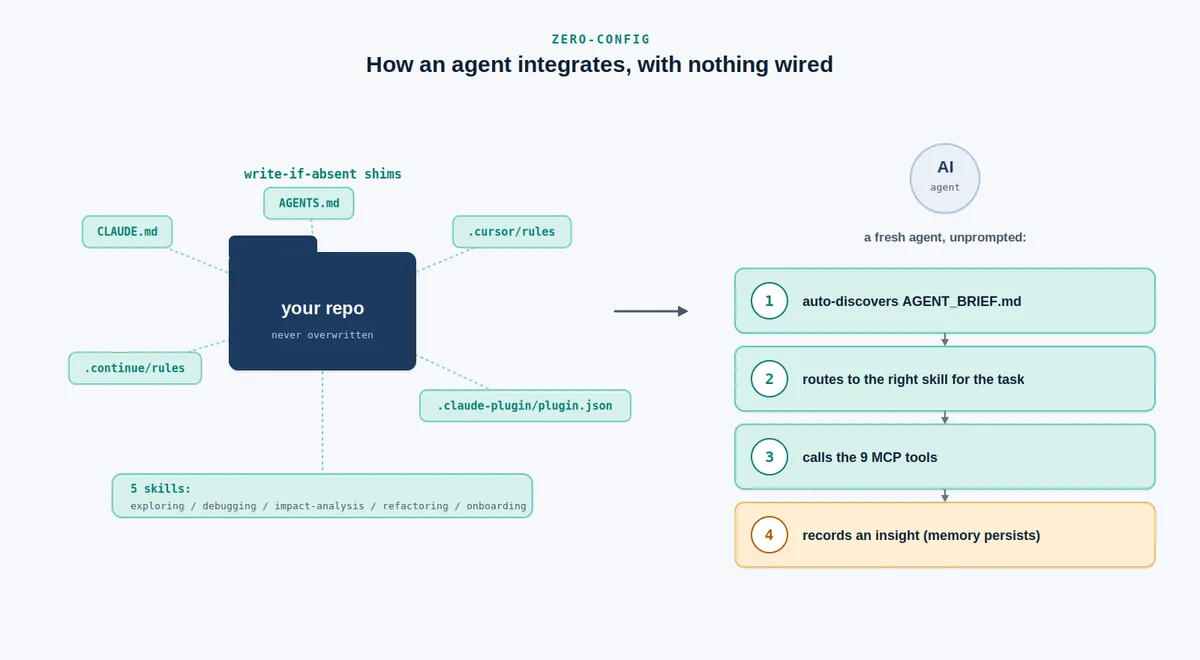
برای ادغام سریع و بدون سیمکشی دستی، این ابزار شیمهای «نوشتن در صورت عدم وجود» (write-if-absent) را در مخزن هدف قرار میدهد. اینها شامل CLAUDE.md، AGENTS.md، فایل .cursor/rules، فایل .continue/rules و مانیفست پلاگین Claude Code هستند. همچنین پنج مهارت تک-هدفه (single-intent) را ارائه میدهد: codebase-exploring (کاوش)، -debugging (عیبیابی)، -impact-analysis (تحلیل اثر)، -refactoring (بازسازی) و -onboarding (بهجاگذاری).
به طور همزمان، نُه ابزار ترکیبی را از طریق یک سرور پروتکل زمینهٔ مدل (MCP) ارائه میکند. توصیف هر ابزار زیر ۲۰۰ توکن نگه داشته شده تا در بودجه متادیتای هر نوبتِ عامل جای بگیرد:
- impact: اجرای یک BFS (جستجوی اول سطح) با عمقبندی شده و فیلتر اطمینان روی یالهای CALLS برای سنجش شعاع اثر (Blast-radius).
- context: یک فراخوانی جامع (Kitchen sink) که تعریف، فراخوانکنندهها، فراخوانشوندگان، والدین، اعضا، کامیتهای اخیر، نویسنده غالب و بینشها را فراهم میکند.
- archaeology: گزارش نرخ تغییر، نویسندگان برتر، عامل اتوبوس، خوشههای تغییر همزمان و نزدیکی عیوب.
- flow: اجرای یک DFS (جستجوی اول عمق) روی CALLS با قابلیت تشخیص چرخه (Cycle detection) داخلی.
- query: پشتیبانی از Cypher خام یا بازیابی ترکیبی زبان طبیعی (ترکیبی از BM25 + سیگنال ساختاری + معنایی آفلاین اختیاری با ادغام RRF).
- record_insight: ذخیره یک یادگیری تایید شده درباره یک نماد خاص.
- recall_insights: بازخوانی بینشهای ذخیره شده به ترتیب جدیدترینها.
- visualize: تولید یک نمودار Mermaid محدود از یک همسایگی، که در آن استایل خطچین یالها، سطح اطمینان را رمزگذاری میکند.
- trace: نقشهبرداری از یک برش ویژگی در کل پشته (Cross-stack) از طریق گره واسط Endpoint.
در تستهای خصمانه (Adversarial testing) — جایی که یک عامل تازهوارد هر پاسخ MCP را با فایلهای واقعی تطبیق داد — توسعهدهنده دریافت که باستانشناسی git، پرسوجوهای ساختاری/Cypher دقیق و خلاصههای پیشتولید شده بسیار دقیق و قابل تایید هستند.
با این حال، توابعی مثل impact()، context() و flow() برای «فراخوانی» (Recall) بهینه شدهاند تا هیچ احتمالی را از دست ندهند، حتی اگر دقت (Precision) کاهش یابد. در زبانهای با توزیع پویا (Dynamic-dispatch) مانند Dart، برخی یالهای CALLS ممکن است در واقع صرفاً «ارجاعات» ساده باشند، که باعث میشود شعاع اثر به جای یک پاسخ نهایی، به یک «مجموعه کاندیدا» تبدیل شود که عامل باید آن را تایید کند.
نسخه ۰.۸ با افزودن گذرهای دقت (Precision passes)، مانند شمارش فراخوانکنندگان متمایز و لایهبندی AMBIGUOUS برای تداخلات نام، و همچنین پرچمهای «حالت تخریبشده صادقانه»، این نقاط ضعف را اصلاح کرد. توسعهدهنده صراحتاً ذکر میکند که این ابزار در حال حاضر یک «تولیدکننده سرنخ برای تحلیل» (Assisted-analysis lead-generator) است، نه یک منبع حقیقت مطلق.
توسعهدهنده خاطرنشان میکند که ویژگیهای query() و trace در زبان طبیعی در پایههای کد بزرگ وب/بکاند میدرخشند اما برای اپلیکیشنهای کوچک آفلاین ارزش کمتری دارند؛ اکنون trace زمانی که گراف فاقد Endpoint باشد، این موضوع را خودکار یادداشت میکند. در حالی که v0.8 یک ابزار تحلیل کمکی است، پاسخ به این سوال که «آیا تغذیه عامل با این دادهها سرعت حل مسائل را به طور قابل اندازهگیری افزایش میدهد یا خیر»، به نسخه ۰.۹ موکول شده است که پس از یک پایلوت محلی بدون مدل (Model-free localization) ضبط شده در مخزن است.
نقشه راه نسخه ۰.۹ روی تعامل انسانی و اندازهگیری متمرکز است. اضافات کلیدی عبارتند از:
- یک CLI تعاملی برای نشستهای پایدار deepdive.
- یک REPL پرسوجو که گراف را باز نگه میدارد.
- یک مرورگر گراف TUI متنی.
- یک جادوگر (Wizard) راهنمای ورود.
- اندازهگیریهای کامل مفید بودن (End-to-end usefulness) و اصلاحات دقت گزارشدهی.
این چرخش به سمت گرافهای برچسبدار نشان میدهد که آینده کدنویسی با AI، نه در حجم بیشتر زمینه، بلکه در «اصالت» (Provenance) آن زمینههاست. برای توسعهدهندگان، این به معنای گذار از «اعتماد به حدس LLM» به «تایید شواهد گراف» است.
برای امتحان ابزار، کاربران میتوانند uv tool install forensic-deepdive را اجرا کرده و از دستور forensic extract /path/to/repo برای ساخت گراف استفاده کنند. این ابزار همچنین در MCP Registry (io.github.Dhevenddra/forensic-deepdive) و به عنوان پلاگین Claude Code از طریق /plugin marketplace add Dhevenddra/forensic-deepdive در دسترس است.
گام بعدی شما
- اگر از Cursor یا Claude Code استفاده میکنید، این ابزار را با
uv tool install forensic-deepdiveنصب کنید. - با دستور
forensic extract /path/to/repoگراف مخزن خود را بسازید و تفاوت دقت در تحلیل اثرات (Impact Analysis) را بسنجید. - در تنظیمات عامل خود، اولویت را به نتایج با برچسب EXTRACTED بدهید تا از تغییرات اشتباه جلوگیری کنید.
اما بررسی اینکه آیا این دادههای ساختاریافته واقعاً سرعت حل باگها را افزایش میدهند، هدف اصلی نسخه ۰.۹ است که در گزارشهای آتی بررسی خواهیم کرد.



گفتگو