تصور کنید یک باگ بحرانی در تابعی نهفته است که هیچ کلمه کلیدی مشترکی با پرسوجوی شما ندارد؛ در این حالت، هوش مصنوعی شما احتمالاً هرگز آن را پیدا نمیکند. چرا یک عامل کدنویسی شکست میخورد وقتی یک باگ حیاتی در تابعی است که هیچ کلمه کلیدی مشترکی با کوئری کاربر ندارد؟ Droste برای حل این مشکل، به عنوان یک موتور حافظه محلی کد عمل میکند که ساختار علی (Causal Structure) را بر شباهت سادهٔ متنی ترجیح میدهد.
بسیاری از گردشهای کاری فعلی عاملها بر اساس خواندن کورکورانه فایلها یا جستوجوی برداری روی تکههای متن (Chunks) هستند. این روشها با کد مانند یک متن تخت رفتار میکنند و این واقعیت را نادیده میگیرند که مثلاً یک تابع SQL ممکن است توسط یک فراخوانی RPC در زبان تایپاسکریپت فعال شود. طبق مستندات فنی این پروژه، اگر کلمات متفاوت باشند، یک شاخص برداری استاندارد معمولاً ارتباط را کاملاً از دست میدهد. در واقع، یک فایل ممکن است به دلیل اینکه «فراخوانکننده» (Caller)، «فراخوانشونده» (Callee)، «مدیریتکننده» (Handler)، «مهاجرت» (Migration) یا یک «وابستگی» (Dependency) است اهمیت داشته باشد، نه به دلیل نحوه عبارتبندی یا کلمات بهکار رفته در آن.
همانطور که در تحلیلهای پیشین ما دربارهی حافظهٔ عاملها اشاره کردیم، تکیه بر شباهت معنایی برای درک منطق پیچیده کافی نیست. این چالش در واقع ریشه در محدودیتهای روشهای تکهبندی سنتی دارد، موضوعی که در بررسی راهکارهای حذف توهمات در سیستمهای RAG به تفصیل به آن پرداختهایم. Droste یک گراف ترکیبی شامل پوشهها، فایلها، نمادها و پیوندهای صریح فراخوانکننده/فراخوانشونده میسازد. بر اساس مستندات فنی، این موتور ابتدا بردار معنایی (Embedding) — مثل کارت معرفی عددی برای هر واژه که میگوید این کلمه «همسایهی» چه کلمات دیگری است — را محاسبه میکند، اما سپس آنها را با لبههای وابستگی و پیوندهای بینزبانی تکمیل میکند. هدف این است که به عاملها یک «برش علی» (Causal Slice) از کد ارائه دهد تا نیاز نباشد هوش مصنوعی بهطور مکرر فایلها را اسکن کند یا صرفاً به شباهت معنایی تکیه نماید.
فلسفه طراحی و بستر عملیاتی
جستوجوی برداری در یافتن کدهایی که شبیه پرسوجو هستند عالی است، اما منطق کد توسط روابط تعریف میشود. برای مثال، یک کنترلکننده یک سرویس را فراخوانی میکند و آن سرویس سپس یک مخزن داده (Repository) را صدا میزند. در یک سناریوی دیگر، یک بخش فرانتاند ممکن است یک تابع RPC را فراخوانی کند، یا یک تابع Edge ممکن است با یک جدول در پایگاه داده در ارتباط باشد. همچنین، فایلهای Migration اغلب عناصری را تعریف میکنند که بهطور غیرمستقیم در کد برنامه استفاده میشوند و تستها رفتارهایی را آشکار میکنند که در پیادهسازی اولیه بدیهی نیستند. در این زنجیره، اگر عامل فقط به دنبال کلمات کلیدی باشد، ارتباط بین لایههای مختلف را گم میکند. تولید بازیابیافزا (RAG) — مثل دانشآموزی که قبل از جواب دادن، اول کتاب درسی را باز میکند و از آن نقل میآورد — در مدلهای سنتی فقط به شباهت کلمات نگاه میکند، اما در Droste، ساختار گرافیکی اولویت دارد. در این راستا، باید توجه داشت که برای بسیاری از پروژهها، استفاده از دیتابیسهای برداری تخصصی ممکن است یک اتلاف هزینه باشد و رویکردهایی مانند ساختارهای گرافیکی کارآمدتر هستند.
معماری محلیمحور (Local-First)
این ابزار بهگونهای طراحی شده که کاملاً محلیمحور (Local-First) باشد. یعنی به هیچ پایگاهداده ابری، هیچ حساب کاربری و هیچ کلید API نیاز ندارد. این معماری تضمین میکند که موتور حافظهٔ کد کاملاً خصوصی باقی بماند و در طول چرخه توسعه، هیچ تأخیری (Latency) در پاسخدهی ایجاد نشود.
جزئیات فنی و سازوکارهای اجرا
بر اساس بررسی منابع متعدد، ویژگیهای فنی این موتور به شرح زیر است:
- اندکسگذاری: برای استخراج نمادها (Symbol Extraction) و نقشهبرداری دقیق از توابع، کلاسها، متدها، فایلها و پوشهها از Tree-sitter استفاده میکند. همچنین برای حفظ آگاهی معنایی، بردارهای محلی را محاسبه میکند.
- ذخیرهسازی: از فایلهای JSON محلی تکه-تکه شده (Sharded) استفاده میکند، بهطوری که برای هر مسیر منبع (Source Path) یک تکه (Shard) مجزا وجود دارد. این روش باعث میشود پس از هر تغییر، نیازی به بازنویسی کل پایگاهداده نباشد و ذخیرهسازیهای افزایشی (Incremental Saves) بسیار سریعتر انجام شود.
- سازگاری: از یک مدل سازگاری سبک شبیه seqlock استفاده میکند. این سازوکار تضمین میکند که وقتی یک پروسه در حال نوشتن تکههاست، خوانندهها با یک снимبرداری ناقص (Torn Snapshot) مواجه نشوند. این امر یک جریان کاری زنده را پشتیبانی میکند که در آن موتور در حال اندکسگذاری است، نمایشگر گراف در حال خواندن است و سرور MCP بهطور همزمان پاسخ میدهد.
- بازیابی: بهجای پرسش سادهی «کدام تکهها شبیه هستند؟»، این موتور میپرسد: «چه چیزی این را فراخوانی میکند؟»، «این چه چیزی را صدا میزند؟»، «کدام فایل مالک این نماد است؟» و «چه گرههای مرتبطی در گراف به هم متصلاند؟»
- رابط کاربری: این سیستم از طریق یک CLI پایتونی، یک نمایشگر گراف بصری با قابلیت زوم (Zoomable Visual Graph Viewer) و یک سرور پروتکل زمینهٔ مدل (MCP) فعالیت میکند.
ادغام با MCP و مدیریت زمینه
برای کلاینتهای MCP، پیکربندی اولیه بسیار ساده است:{ "mcpServers": { "droste": { "command": "droste", "args": ["mcp"] } } }
برای کارهای جدی و پیشرفته در مخازن متعدد (Multi-repo)، Droste امکان جداسازی یک پایگاهداده مجزا برای هر پروژه را فراهم میکند:{ "mcpServers": { "droste": { "command": "droste", "args": [ "--db", "/absolute/path/to/droste_memory_db.json", "mcp" ] } } }
این پیکربندی مانع از آن میشود که هوش مصنوعی زمینه (Context) مخازن مختلف را با هم ترکیب کند و در عین حال، یک پنجره زمینه با بودجه توکن مشخص (Token-budgeted Context Window) را برای مدل زبانی (LLM) حفظ میکند.
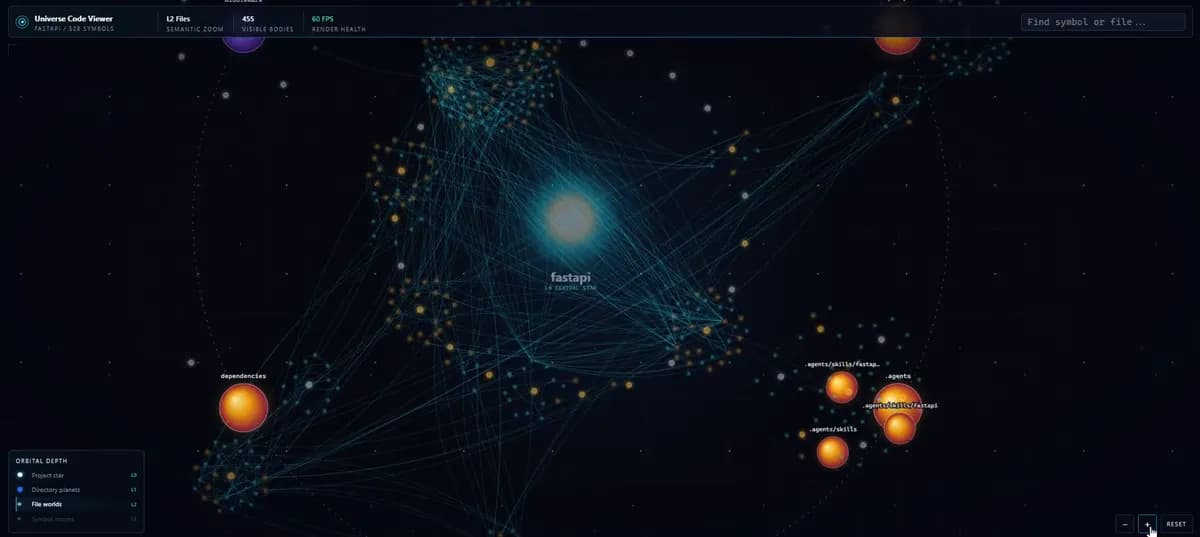
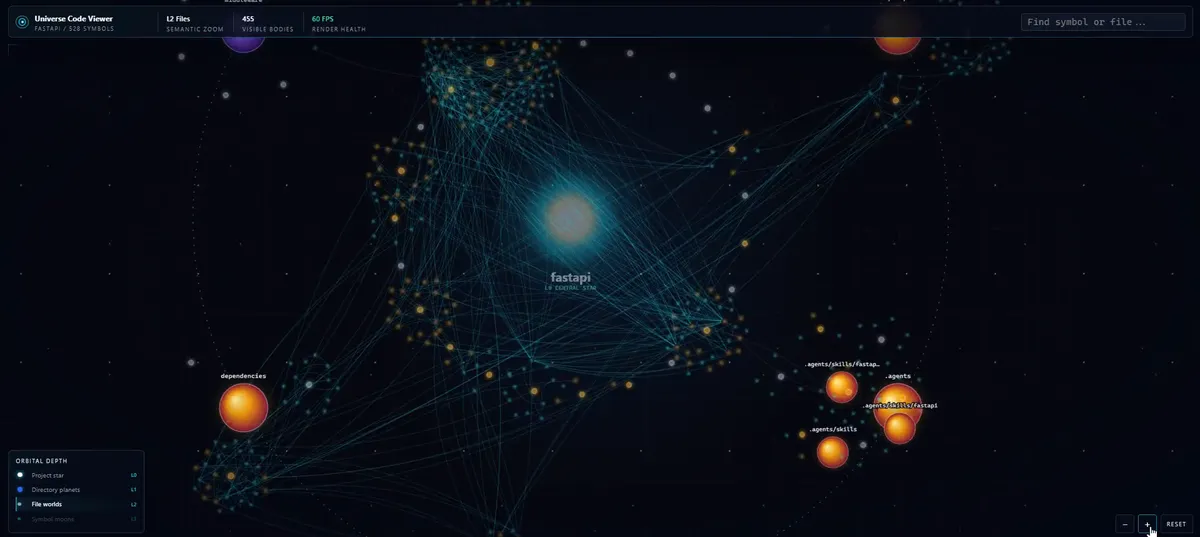
بصریسازی جهان کد
این موتور شامل یک نمایشگر گراف بصری با قابلیت زوم است. بهجای ارائه یک درخت فایل تخت (Flat File Tree)، کدبیس را به عنوان یک «جهان کد» شامل پوشههای پروژه، فایلها و نمادها نمایش میدهد. این ابزار بهگونهای طراحی شده تا کوپلینگ (Coupling) و «شعاع تخریب» (Blast Radius) یک تغییر خاص را برای توسعهدهنده انسان بهوضوح قابل مشاهده کند.
این رویکرد فرض بنیادی کدنویسی با هوش مصنوعی را تغییر میدهد: این باور که شباهت معنایی، جایگزینی کافی برای مرتبط بودن (Relevance) است، اکنون به چالش کشیده شده است. با افزودن آگاهی ساختاری، عاملها اکنون میفهمند فایلی اهمیت دارد چون یک «مدیریتکننده» یا «مهاجرت» (Migration) است، نه چون متن آن شبیه پرامپت است.
توسعهدهندگان میتوانند این ابزار را با دستور python -m pip install --upgrade droste-memory نصب کنند. دستورات رایج شامل droste index . برای اندکسگذاری، droste status برای بررسی سلامت سیستم و droste context "authentication flow" --budget 2000 برای بازیابی زمینه خاص با بودجه توکنی مشخص است. این ابزار متنباز و دارای لایسنس MIT است و در GitHub و PyPI در دسترس میباشد. اکنون محک اصلی و بحرانی این است که این برشهای علی تا چه حد نرخ موفقیت عاملهای خودکار در کدبیسهای عظیم و چندزبانه را افزایش میدهند.
گام بعدی شما
- اگر با پروژههای بزرگ چندزبانه (مثلاً ترکیب TS و Go) کار میکنید، این ابزار را جایگزین RAGهای متنی ساده کنید.
- تنظیمات MCP را برای جداسازی پایگاههای داده پروژهها فعال کنید تا از توهمات متقاطع جلوگیری شود.
- از نمایشگر گرافیکی برای شناسایی وابستگیهای پنهان قبل از انجام Refactorهای بزرگ استفاده کنید.
اما اثر این تغییر در کاهش نرخ توهمات مدلهای استدلالی حتی عمیقتر است — به تحلیل ما درباره مدلهای Reasoning مراجعه کنید.



گفتگو